
 Book tunnel (source: PublicDomainPictures via Pixabay)
Book tunnel (source: PublicDomainPictures via Pixabay) In July 2016, I broached the idea for an NLP library aimed at Apache Spark users to my friend David Talby. A little over a year later, Talby and his collaborators announced the release of Spark NLP. They described the motivation behind the project in their announcement post and in this accompanying podcast that Talby and I wrote, as well as in this recent post comparing popular open source NLP libraries. [Full disclosure: I’m an advisor to Databricks, the startup founded by the team that originated Apache Spark.]
As we close in on the two-year anniversary of the project, I asked Talby where interest in the project has come from, and he graciously shared geo-demographic data of visitors to the project’s homepage:
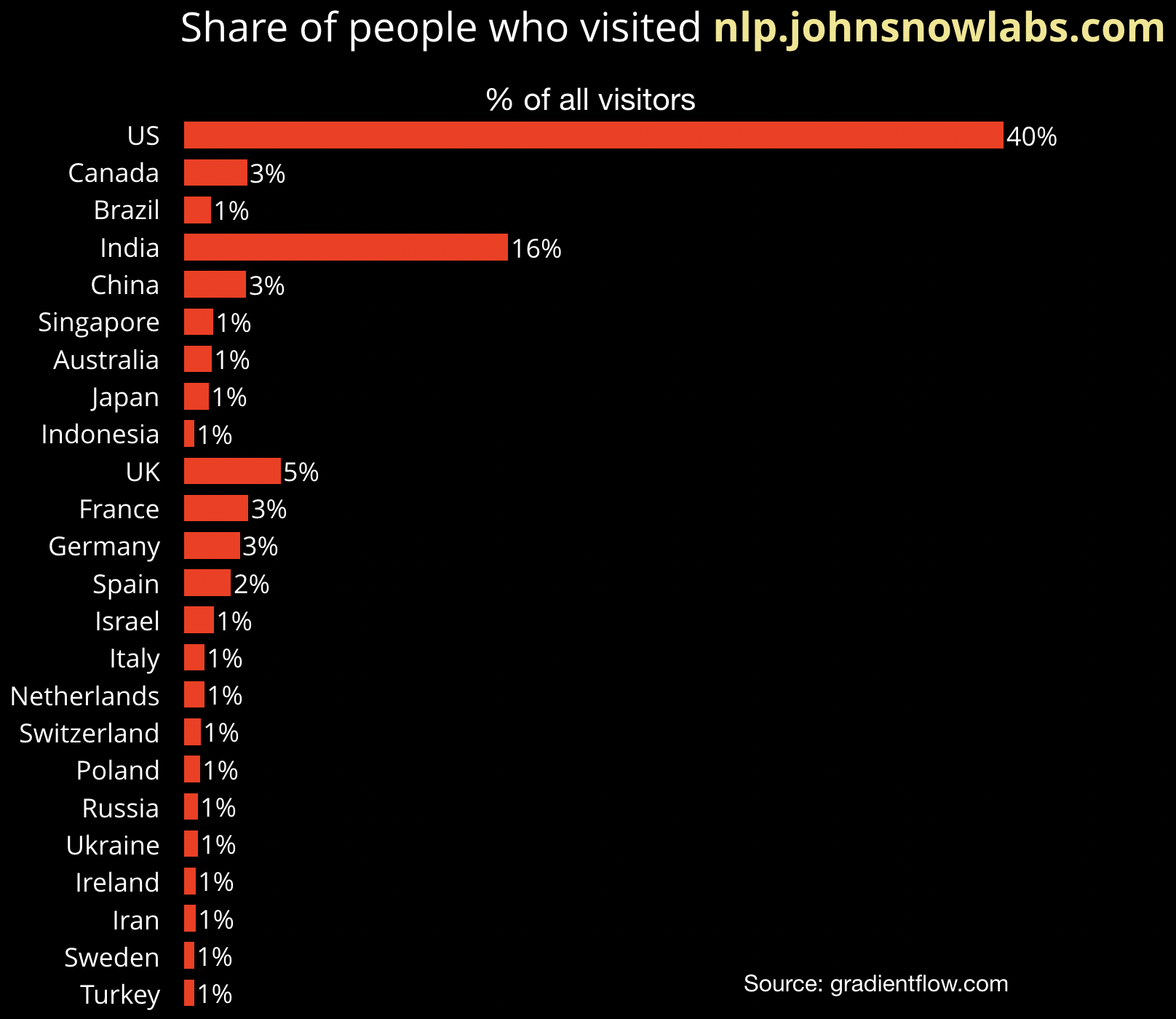
Of the thousands of visitors to the site: 44% are from the Americas, 24% from Asia-Pacific, and the remaining 22% are based in the EMEA region.
Many of these site visitors are turning into users of the project. In our recent survey AI Adoption in the Enterprise, quite a few respondents signalled that they were giving Spark NLP a try. The project also garnered top prize—based on a tally of votes cast by Strata Data Conference attendees—in the open source category at the Strata Data awards in March.
There are many other excellent open source NLP libraries with significant numbers of users—spaCy, OpenNLP, Stanford CoreNLP, NLTK—but at the time when the project started, there seemed to be an opportunity for a library that appealed to users who already had Spark clusters (and needed a scalable solution). While the project started out targeting Apache Spark users, it has evolved to provide simple API’s that get things done in a few lines of code and fully hide Spark under the hood. The library’s Python API now has the most users. Installing Spark NLP is a one-liner operation using pip or conda for Python, or a single package pull on Java or Scala using maven, sbt, or spark-packages. The library’s documentation has also grown, and there are public online examples for common tasks like sentiment analysis, named entity recognition, and spell checking. Improvements in documentation, ease-of-use, and its production-ready implementation of key deep learning models, combined with speed, scalability, and accuracy has made Spark NLP a viable option for enterprises needing an NLP library.
For more on Spark NLP, join Talby and his fellow instructors for a three-hour tutorial, Natural language understanding at scale with Spark NLP, at the Strata Data Conference in New York City, September 23-26, 2019.
Related content: