Spark comparison: AWS vs. GCP
Assessing cost, performance, and run time of a typical Spark workload.
 Hourglass comparison. (source: Pixabay)
Hourglass comparison. (source: Pixabay)
There’s little doubt that cloud computing will play an important role in data science for the foreseeable future. The flexible, scalable, on-demand computing power available is an important resource, and as a result, there’s a lot of competition between the providers of this service. Two of the biggest players in the space are Amazon Web Services (AWS) and Google Cloud Platform (GCP).
This article includes a short comparison of distributed Spark workloads in AWS and GCP—both in terms of setup time and operating cost. We ran this experiment with our students at The Data Incubator, a big data training organization that helps companies hire top-notch data scientists and train their employees on the latest data science skills. Even with the efficiencies built into Spark, the cost and time of distributed workloads can be substantial, and we are always looking for the most efficient technologies so our students are learning the best and fastest tools.

Learn faster. Dig deeper. See farther.
Submitting Spark jobs to the cloud
Spark is a popular distributed computation engine that incorporates MapReduce-like aggregations into a more flexible, abstract framework. There are APIs for Python and Java, but writing applications in Spark’s native Scala is preferable. That makes job submission simple, as you can package your application and all its dependencies into one JAR file.
It’s common to use Spark in conjunction with HDFS for distributed data storage, and YARN for cluster management; this makes Spark a perfect fit for AWS’s Elastic MapReduce (EMR) clusters and GCP’s Dataproc clusters. Both EMR and Dataproc clusters have HDFS and YARN preconfigured, with no extra work required.
Configuring cloud services
Managing data, clusters, and jobs from the command line is more scalable than using the web interface. For AWS, this means installing and using the command-line interface (cli). You’ll have to set up your credentials beforehand as well as make a separate keypair for the EC2 instances that are used under the hood. You’ll also need to set up roles—basically permissions—for both users (making sure they have sufficient rights) and EMR itself (usually running aws emr create-default-roles in the cli is good enough to get started).
For GCP the process is more straightforward. If you install the Google Cloud SDK and sign in with your Google account, you should be able to do most things right off the bat. The thing to remember here is to enable the relevant APIs in the API Manager: Compute Engine, Dataproc, and Cloud Storage JSON.
Once you have things set up to your liking, the fun part begins! Using commands like aws s3 cp or gsutil cp you can copy your data into the cloud. Once you have buckets set up for your inputs, outputs, and anything else you might need, running your app is as easy as starting up a cluster and submitting the JAR file. Make sure you know where the logs are kept—it can be tricky to track down problems or bugs in a cloud environment.
You get what you pay for
When it comes to cost, Google’s service is more affordable in several ways. First, the raw cost of purchasing computing power is cheaper. Running a Google Compute Engine machine with 4 vCPUs and 15 GB of RAM will run you $0.20 every hour, or $0.24 with Dataproc. An identically-specced AWS instance will cost you $0.336 per hour running EMR.
The second factor to consider is the granularity of the billing. AWS charges by the hour, so you pay the full rate even if your job takes 15 minutes. GCP charges by the minute, with a 10-minute minimum charge. This ends up being a huge difference in cost in a lot of use cases.
Both services have various other discounts. You can effectively bid on spare cloud capacity with AWS’s spot instances or GCP’s preemptible instances. These will be cheaper than dedicated, on-demand instances, but they’re not guaranteed to be available. Discounted rates are available on GCP if your instances live for long periods of time (25% to 100% of the month). On AWS, paying some of the costs upfront or buying in bulk can save you some money. The bottom line is, if you’re a power user and you use cloud computing on a regular or even constant basis, you’ll need to delve deeper and perform your own calculations.
Lastly, the costs for new users wanting to try out these services are lower for GCP. They offer a 60-day free trial with $300 in credit to use however you want. AWS only offers a free tier where certain services are free to a certain point or discounted, so you will end up paying to run Spark jobs.This means that if you want to test out Spark for the first time, you’ll have more freedom to do what you want on GCP without worrying about price.
Performance comparison
We set up a trial to compare the performance and cost of a typical Spark workload. The trial used clusters with one master and five core instances of AWS’s m3.xlarge and GCP’s n1-standard-4. They differ slightly in specification, but the number of virtual cores and amount of memory is the same. In fact, they behaved almost identically when it came to job execution time.
The job itself involved parsing, filtering, joining, and aggregating data from the publicly available Stack Exchange Data Dump. We ran the same JAR on a ~50M subset of the data (Cross Validated) and then on the full ~9.5G data set.
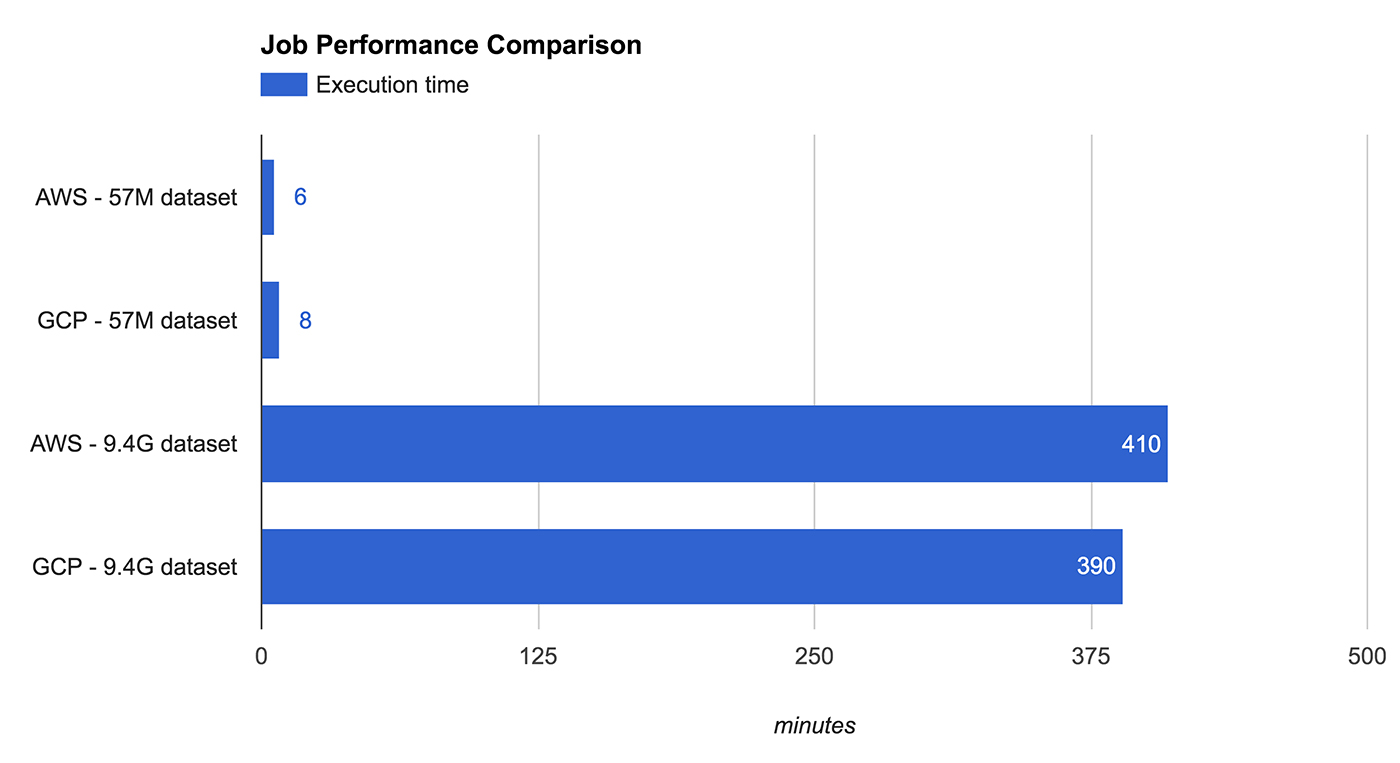
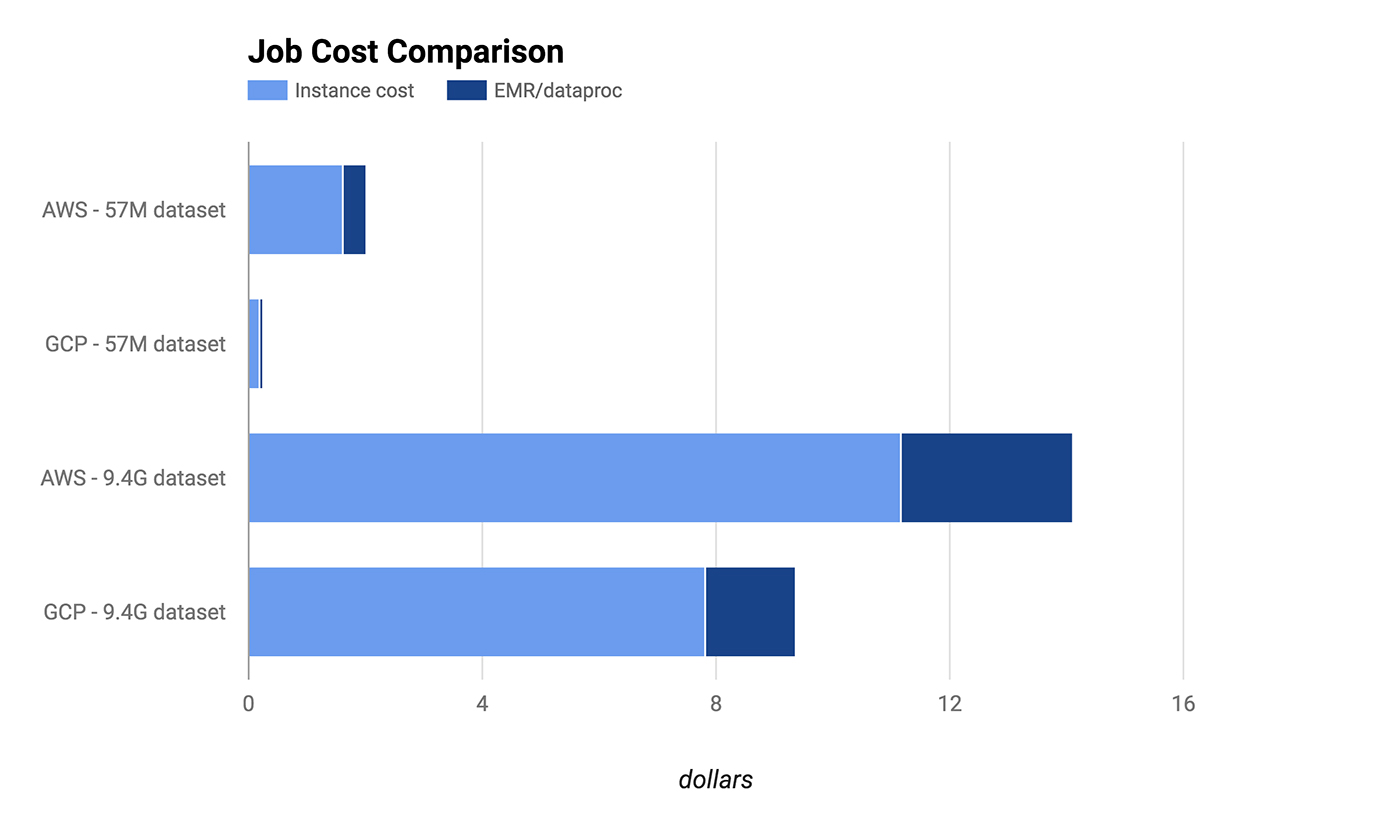
The short job clearly benefited from GCP’s by-the-minute billing, being charged only for 10 minutes of cluster time, whereas AWS charged for a full hour. But even the longer job was cheaper on GPS both because of fractional-hour billing and a lower per-unit time cost for comparable performance. It’s also worth noting that storage costs weren’t included in this comparison.
Conclusion
AWS was the first mover in the space, and this shows in the API. Its ecosystem is vast, but its permissions model is a little dated, and its configuration is a little arcane. By contrast, Google is the shiny new entrant in this space and has polished off some of the rough edges. It is missing some features on our wishlist, like an easy way to auto-terminate clusters and detailed billing information broken down by job. Also, for managing tasks programmatically in Python, the API client library isn’t as full-featured as AWS’s Boto.
If you’re new to cloud computing, GCP is easier to get up and running, and the credits make it a tempting platform. Even if you are already used to AWS, you may still find the cost savings make switching worth it, although the switching costs may not make moving to GCP worth it.
Ultimately, it’s difficult to make sweeping statements about these services because they’re not just one entity; they’re entire ecosystems of integrated parts, and both have pros and cons. The real winners are the users. As an example, at The Data Incubator, our Ph.D. data science fellows really appreciate the cost reduction as they learn about distributed workloads. And while our big data corporate training clients may be less price sensitive, they appreciate being able to crunch enterprise data faster, while holding price constant. Data scientists can now enjoy the multitude of options available, and the benefits of having a competitive cloud computing market.