

In this episode of the Data Show, I spoke with Andrew Feldman, founder and CEO of Cerebras Systems, a startup in the blossoming area of specialized hardware for machine learning. Since the release of AlexNet in 2012, we have seen an explosion in activity in machine learning, particularly in deep learning. A lot of the work to date happened primarily on general purpose hardware (CPU, GPU). But now that we’re six years into the resurgence in interest in machine learning and AI, these new workloads have attracted technologists and entrepreneurs who are building specialized hardware for both model training and inference, in the data center or on edge devices.
{kind=link}
In fact, companies with enough volume have already begun building specialized processors for machine learning. But you have to either use specific cloud computing platforms or work at specific companies to have access to such hardware. A new wave of startups (including Cerebras) will make specialized hardware affordable and broadly available. Over the next 12-24 months architects and engineers will need to revisit their infrastructure and decide between general purpose or specialized hardware, and cloud or on-premise gear.
In light of the training duration and cost they face using current (general purpose) hardware, some experiments might be hard to justify. Upcoming specialized hardware will enable data scientists to try out ideas that they previously would have hesitated to pursue. This will surely lead to more research papers and interesting products as data scientists are able to run many more experiments (on even bigger models) and iterate faster.
As founder of one of the most anticipated hardware startups in the deep learning space, I wanted get Feldman’s views on the challenges and opportunities faced by engineers and entrepreneurs building hardware for machine learning workloads.
Here are some highlights from our conversation:
A renaissance for computer architecture
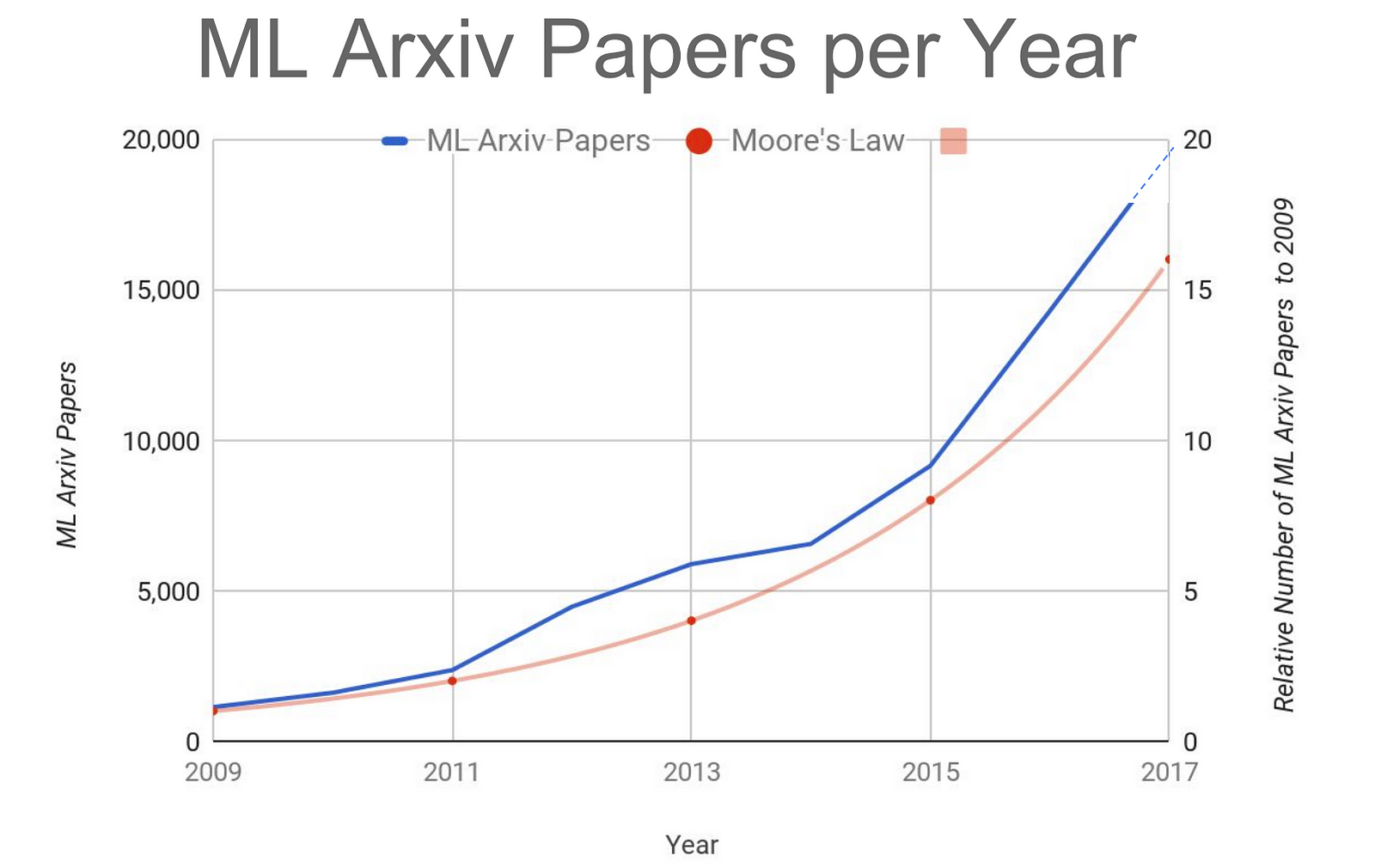
OpenAI put out some very interesting analysis recently that showed that since 2012, the compute use for the largest AI training runs has increased by 300,000x. … What’s available to us to attack the vast discrepancy between compute demand and what we have today? Two things are available to us. The first is, exploring interesting compute architectures. I think this ushers in a golden age for compute architectures. And number two, it’s building dedicated hardware and saying: ‘We’re prepared to make trade offs to accelerate AI compute by not trying to be good at other things. By not trying to be good at graphics or by not trying to be a good web server. But we will attack this vast demand for compute by building dedicated hardware for artificial intelligence work.’ Historically, the following has been a very productive and valuable trade off: new and interesting architectures dedicated for a particular type of work. That’s the opportunity that many of these hardware companies or chip companies have seen.
Communication intensive workloads
When you stay on a chip, one can communicate fairly quickly. The problem is our work in artificial intelligence often spans more than one traditional chip. And the performance penalty for leaving the chip is very, very high. On-chip, you stay in silicon; off-chip, you have to wrap your communication in some sort of protocol, you need to send it, connect it over lanes on a print circuit board or maybe through a PCI switch, or maybe through an Ethernet switch or an InfiniBand switch. This adds two, three, four orders of magnitude of latency.
Some of the problems the hardware vendors who are interested in solving data center training, data center inference are working on are how you can accelerate the communication between cores and across tens of thousands of cores, or even hundreds of thousands of cores across many chips. Some are inventing new techniques for special switches and modifying PCIe to do that. Others have sort of more fundamental approaches to accelerating this communication. But if you can’t communicate quickly, you can’t train a model quickly and you can’t provide inference quickly.
New hardware will significantly reduce training times
You should see a reduction in training times of 10-50x sometime over the next 12-18 months. … I think you’re going to see an additional 10-25x in the following year. We’re looking at three orders of magnitude in reduction in training time over the next several years.
Related resources:
- “How big compute is powering the deep learning rocket ship”: Greg Diamos on building computer systems for deep learning and AI.
- “The artificial intelligence computing stack”: A look at why the U.S. and China are investing heavily in this new computing stack
- “How to train and deploy deep learning at scale”: Ameet Talwalkar on large-scale machine learning.
- “Scaling machine learning”: Reza Zadeh on deep learning, hardware/software interfaces, and why.
- “A new benchmark suite for machine learning”: David Patterson and Gu-Yeon Wei on MLPerf, a new set of benchmarks compiled by industry and academic contributors.
- “Building tools for the AI applications of tomorrow”
- “Toward the Jet Age of machine learning”