The unwelcome guest: Why VMs aren’t the solution for next-gen applications
Scale-out applications need scaled-in virtualization.
 Horror vacui by Alejandro Almanza Pereda at the Dublin Contemporary 2011 (source: William Murphy/Flickr)
Horror vacui by Alejandro Almanza Pereda at the Dublin Contemporary 2011 (source: William Murphy/Flickr)
Data center operating systems are emerging as a first-class category of distributed system software. Hadoop, for example, is evolving from a MapReduce framework into YARN, a generic platform for scale-out applications.
To enable a rich ecosystem of diverse applications to coexist on these platforms, providing adequate isolation is crucial. The isolation mechanism must enforce resource limits, decouple software dependencies among applications and the host, provide security and privacy, confine failures, etc. Containers offer a simple and elegant solution to the problem. However, a question that comes up frequently is: Why not virtual machines (VMs)? After all, these systems face a number of the same challenges that have been solved by virtualization for traditional enterprise applications.

Learn faster. Dig deeper. See farther.
All problems in computer science can be solved by another level of indirection, except of course for the problem of too many indirections” — David Wheeler
Why not virtual machines?
While YARN and systems like it face problems similar to those addressed by VMs for traditional applications, a number of reasons make VMs unsuitable for scale-out context.
Overhead
Resources consumed by the virtualization layer itself can easily become a significant factor of the overhead equation. While resource overhead may not play a deciding role for traditional applications, for large distributed applications the resource cost compounds quickly. The portion of host memory lost on each node in a scale-out cluster amounts to a massive waste of capacity. Furthermore, high resource usage of VMs prevents dense configurations. A physical machine can typically only run several VMs at most.
High startup latency of VMs is a major source of overhead. Unlike conventional applications that are brought up once and kept running, emerging environments often run short-lived tasks. If the average task of a highly parallelized large job runs for a couple minutes, it’s unacceptable to spend a major fraction of that time bringing up the VM.
In spite of extensive optimizations across the stack from hardware all the way through to the application, runtime overhead imposed by VMs remains a problem. While hardware features can address CPU virtualization overhead, overhead continues to be a problem for I/O-centric workloads. In the case of Hadoop, for example, the virtualized I/O stack consists of HDFS, guest file system, guest driver, virtual device, image format interpreter, host file system, host driver, and finally the physical device. The overhead adds up to be significant compared to native execution.
Interestingly, experiments measuring the performance of jobs on a distributed framework like Hadoop running on VMs can be misleading. A poorly placed job on native hardware may sometimes even appear to run faster when moved to virtual infrastructure. However it is merely due to higher overall utilization across the job rather than any kind of speed up of individual tasks due to virtualization itself. After all, correctly tuned jobs are ultimately limited by resources available on underlying hardware.
Application-hypervisor hide and seek
Traditionally, applications and operating systems are built to work with each other. In a virtualized application context, the hypervisor serves the role of the traditional operating system that manages the real hardware. In doing so, it disrupts application-OS symbiosis with an opaque virtualization layer between the two. In fact, the host, guest, and the hypervisor all perform at least a subset of the traditional operating system functions. Whether it is a type-A or type-B hypervisor doesn’t really matter. In case of Xen, for instance, Xen kernel is the hypervisor, Dom0 is the host and DomUs run the guests. On Linux, Linux itself is the host, Qemu/KVM is the hypervisor that in turn runs the guest kernels. Multiple layers of software performing low-level system functions will break existing application interfaces in subtle ways.
Applications running in a VM lack visibility into the topology and configuration of underlying physical resources. What may appear to the application as a directly-attached block device may in fact be a file sitting on a remote NFS server. Obfuscating network and compute topologies compromises application-level resource scheduling. In the case of Hadoop, the resource manager would make suboptimal scheduling decisions based on an incorrect view of physical resources. Data and task locality may be lost, or worse yet, block replicas may end up on the same fault domain, leading to data loss.
Likewise, the hypervisor lacks visibility into the application. The coarse view of resources without their application-level semantic information precludes many optimizations. Reading a specific config value from a file, for example, translates into a block device read at the virtual hardware level. Without the semantic context, optimizations such as prefetching and caching would not be effective. As another example, the hypervisor reserves large portions of physical memory even when it is not used by the guest application simply because it cannot detect unused pages within the guest.
Maintainability
Large numbers of VMs and their guest operating systems imply high management burden. Promptly applying security patches to every VM across a highly dynamic infrastructure with VMs created and deleted on the fly can be a daunting task for an enterprise. VM sprawl is an additional problem as well. Furthermore, the monetary cost of guest operating system licenses can compound capex cost, particularly for scale-out applications.
Undue coupling between application and operating system
Virtualization is often viewed as a way to decouple applications from hardware. However it introduces new coupling between applications and their guest operating systems. Applications have to be run as VM appliances, which then need to bundle the guest operating system into the image black box. It may be possible to migrate the entire VM, for hardware maintenance for example, but it is not possible to upgrade the operating system without disrupting the running application.
Because an application is always tied to its guest operating system, resources allocated to the application cannot be scaled on demand. Resources are first added to the guest operating system, which in turn makes them available to the application. However, guest operating systems typically require a reboot for additional memory or added cores to be recognized.
VMs: Wrong abstraction for applications
In the end, businesses want to run applications — not operating systems or virtual machines. It is ultimately the application that needs to be virtualized. However, VMs cannot directly virtualize applications, so they require an additional guest operating system to patch up the gap.
Over the years, industry and research communities have dedicated much collective effort to addressing the problems that occur with VMs. Numerous innovations have been proposed. Some of them have even developed into technologies in their own right. However, close consideration shows that much of this innovation doesn’t really represent a forward progress in the state of the art relative to containers. Rather, it attempts to fix the issues caused by VMs in the first place. In a way, a large segment of the industry has been fighting the wrong battle, distracted by optimizing VMs rather than applications. There is only so much optimization one can do based on a fundamentally broken model. Following examples represent just a few widely-adopted techniques that had to be invented to circumvent application-VM misalignment.
Paravirtualization
Paravirtualization is one of the most pervasive approaches to improve VM performance. Because the hypervisor cannot directly see or influence the guest operating system and its applications, it relies on the guest operating system itself to give hints or perform actions on its behalf. The interface between the guest and the hypervisor is called paravirtualization API or hypercall interface. Obviously the technique would not work with standard unmodified operating systems. These changes are nontrivial to make and maintain through changing versions of the kernel.
Ballooning
Operating system kernels are highly judicious about committing physical memory. Through a combination of techniques (lazy allocation, copy-on-write etc.), memory requests are deferred until absolutely needed. A technique called ballooning is used to get around the hypervisor’s inability to access to guest operating system’s internals. A ballooning driver is deployed within the guest to identify unused memory regions and convey the data back to the hypervisor. It squeezes out unused pages from the guest and makes them available to the host. It has the unfortunate side effect of periodically subjecting applications to artificial memory pressure. The technique does offer a weak solution but it is far less optimal compared to the native kernel mechanisms that centrally arbitrate memory.
Deduplication
Running multiple instances of the same guest operating system and its standard services within the private memory address space of each VM causes some content to be stored in multiple memory pages. To reduce the memory overhead, an online page deduplication technique called kernel same-page merging (KSM) has been developed. However, it imposes significant performance overhead, especially for hosts which are not memory-constrained and which use non-uniform memory access (NUMA) configurations.
Undoing the Blackbox
VMs treat file system data as monolithic image blobs for the guest file system to interpret. Several efforts have aimed at exposing the internal structure of the opaque VM images for indexing, deduplication, offline concurrent patching of base images etc., but dealing with the idiosyncrasies of image formats, their device partitions, their file systems and their changing on-disk structures has proven nontrivial to keep up.
Containers: Scaled-in virtualization for scale-out applications
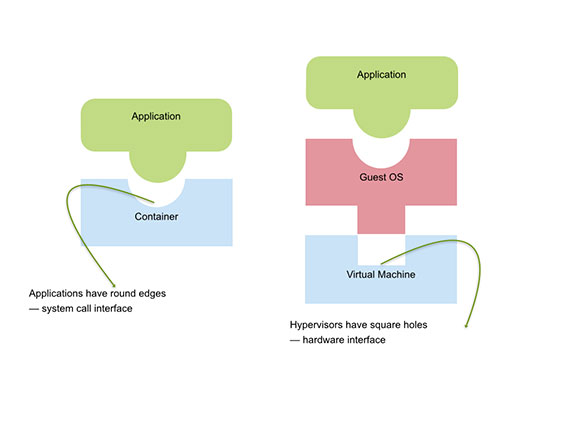
Containers are a fundamentally different form of virtualization designed to directly virtualize applications rather than the operating system. While a VM provides a virtual hardware interface that can run an operating system, a container offers a virtual operating system interface that can run applications. It decouples the application from its environment through a consistent virtual interface of the operating system by virtualizing the well-defined and semantically-rich application–OS interface, rather than OS–hardware interface.
A container consists of a set of namespaces, each of which projects a subset of host resources to the application through their virtual names. Compute resources are virtualized by the process namespace, network resources are virtualized by the network namespace, a virtual file system view is provided through mount namespace and so on. Since containerized processes run natively on the host under the control of the virtualization layer, the subsystems for which container virtualization is applied can be adjusted to suit the needs of the specific use case. The extent to which the host and its resources are exposed to the containerized processes can be controlled at a fine granularity. For instance, a containerized application can be confined to its private view of the file system but still allowed to access host’s network.
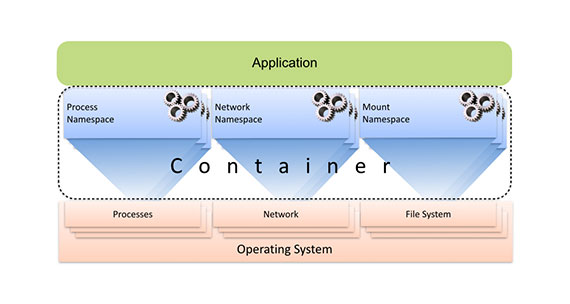
In contrast to VMs, the absence of a guest operating system layer makes containers extremely lightweight, reduces complexity, avoids duplication of functionality, and removes the overhead of intermediate layers, leading to almost imperceptible runtime overhead and startup latency, orders of magnitude higher scalability and simplified management.
Early implementations of data center operating systems such as YARN, Mesos, and Kubernetes are already using containers as their core substrate to ensure required isolation. This will pave the way for the next level of innovation based on containers. This time, it will represent true forward progress.