

 Light stream (source: Riley McCullough on Unsplash)
Light stream (source: Riley McCullough on Unsplash) Software today is not typically a single program—something that is executed by an operator or user, producing a result to that person—but rather a service: something that runs for the benefit of its consumers, a provider of value. So, software is a part of a greater whole, and typically multiple generations of technologies must coexist peacefully and purposefully to provide a viable service. In addition to that, software is increasingly dependent on other software to provide its functionality, be it WebServices, HTTP APIs, databases, or even external devices such as sensors.
Software must also consume data from many potential sources and destinations of information—apps, websites, APIs, files, databases, proprietary services, and so on—and because of this, there’s plenty of incentives to do that well. We refer to this aspect as “integration” of different sources and destinations of information. In this article, we will discuss the need for—and how to achieve—modernization in the field of enterprise integration. We will start by reviewing the current state of enterprise integration and its challenges, and then demonstrate how organizations can achieve more scalable, composable, and functional architecture for interconnecting systems and applications by adopting a reactive and stream-based mindset and tools.
Welcome to a new world of data-driven systems
Today, data needs to be available at all times, serving its users—both humans and computer systems—across all time zones, continuously, in close to real time. As traditional architectures, techniques, and tools prove unresponsive, not scalable, or unavailable, many companies are turning toward the principles of reactive systems and real-time streaming as a way to gain insight into massive amounts of data quickly in a predictable, scalable, and resilient fashion.
Although the ideas of reactive and streaming are nowhere near new, and keeping in mind that mere novelty doesn’t imply greatness, it is safe to say they have proven themselves and matured enough to see many programming languages, platforms, and infrastructure products embrace them fully. Working with never-ending streams of data necessitates continuous processing of it, ensuring the system keeps up with the load patterns it is exposed to, and always provides real-time, up-to-date information.
One of the key aspects—as trivial as it is profound—is that data is coming from somewhere, and ends up somewhere else. Let’s dive into this concept for a bit.
The most common programming task in the world
The most common programming task that a typical software developer has to deal with is: receiving input, transforming it, and producing output.
While that statement seems obvious, it has a few subtle but important implications.
First of all, when we, programmers, write a method or a function, we do not specify where the input parameters come from, or where the output return value goes to. Sadly, it is very common to write logic that deeply couples the notion of IO with the processing of that IO. This is mixing concerns and leads to code that becomes strongly coupled, monolithic, hard to write, hard to read, hard to evolve, hard to test, and hard to reuse.
Since integrating different pieces of software, different systems, different data sources and destinations, and different formats and encodings is becoming so prevalent, this quintessential work deserves better tools.
The past and present of enterprise integration
Service-oriented architecture (SOA) was hyped in the mid-2000s as a modern take on distributed systems architecture, which through modular design would provide productivity through loose coupling between collaborative services—so-called “WebServices”—communicating through externally published APIs.
The problem was that the fundamental ideas of SOA were most often misunderstood and misused, resulting in complicated systems where an enterprise service bus (ESB) was used to hook up multiple monoliths, communicating through complicated, inefficient, and inflexible protocols—across a single point of failure: the ESB.
Anne Thomas[1] captures this very well in her article “SOA is Dead; Long Live Services“:
Although the word ‘SOA’ is dead, the requirement for service-oriented architecture is stronger than ever. But perhaps that’s the challenge: the acronym got in the way. People forgot what SOA stands for. They were too wrapped up in silly technology debates (e.g., ‘what’s the best ESB?’ or ‘WS-* vs. REST’), and they missed the important stuff: architecture and services.
Successful SOA (i.e., application re-architecture) requires disruption to the status quo. SOA is not simply a matter of deploying new technology and building service interfaces to existing applications; it requires a redesign of the application portfolio. And it requires a massive shift in the way IT operates.
What eventually led to the demise of SOAs was that not only did it get too focused on implementation details, but it completely misunderstood the architecture aspect of itself. Some of the problems were:
- The lack of mature testing tools made interoperability a nightmare, especially when services stopped adhering to their own self-published service contracts.
- WebServices, unfortunately, failed to deliver on the distributed systems front by having virtually all implementations using synchronous/blocking calls—which we all know is a recipe for scaling disaster.
- Schema evolution practices were rarely in place.
- Service discovery was rarely—if ever—used, which led to hardcoded endpoint addresses, leading to brittle setups with almost guaranteed downtime on redeployments.
- Scaling the ESBs was rarely attempted, leading to a single point of failure and a single point of bottleneck.
Furthermore, the deployment tooling was not ready for SOA. The provisioning of new machines was not done on-demand: physical servers would take a long time to get delivered and set up, and virtual servers were slow to start, and often ran on oversubscribed machines, with poor performance as a result (something that has improved drastically in the past years with the advent of technologies such as Docker, Kubernetes, and more). Orchestration tooling was also not ready for SOA, with manual deployment scripts being one of the most common ways of deploying new versions.
The rise of enterprise integration patterns
In 2003, Gregor Hohpe and Bobby Woolf released their book Enterprise Integration Patterns. Over the last 15 years, it has become a modern classic, providing a catalog with 65 different patterns of integration between components in systems, and has formed the basis for the pattern language and vocabulary that we now use when talking about system integration.
Over the years, these patterns have been implemented by numerous products, ranging from commercial ESBs and enterprise message buses to open source libraries and products.
Most well-known is probably Apache Camel. Created in 2007, and described as “a versatile open source integration framework based on known enterprise integration patterns,” it is a very popular Java library for system integration, offering implementations of most (if not all) of the standard enterprise integration patterns (EIP). It has a large community around it that, over the years, has implemented connectors to most standard protocols and products in the Java industry. Many see it as the defacto standard for enterprise integration in Java.
Breaking the Camel’s back?
Unfortunately, most of Apache Camel’s connectors are implemented in a synchronous and/or blocking fashion, without first-class support for streaming—working with data that never ends—leading to inefficient use of resources and limited scalability due to high contention for shared resources. Its strategies for flow control are either stop-and-wait (i.e., blocking), discarding data, or none—which can lead to resilience problems, poor performance, or worse: rapid unscheduled disassembly in production. Also, fan-in/fan-out patterns tend to be either poorly supported—requiring emulation[2]; static—requiring knowing all inputs/outputs at creation[3]; or, lowest-common-denominator—limiting throughput to the slowest producer/consumer[4].
The need for reactive enterprise integration
There is clearly a need to improve over the status quo: what can be done differently, given what we’ve learned in the past decades as an industry, and given what tooling is now available to us? What if we could fully embrace the concept of streaming, and redesign system integration from a reactive—asynchronous, non-blocking, scalable, and resilient perspective? What would that look like?
Streaming as a first-class concept
First of all, we need to have streams as a first-class programming concept. A stream can be defined as a potentially unbounded (“infinite”) sequence of data. Since it is potentially unbounded, we can’t wait—buffer elements—until we have received all data before we act upon it, but need to do so in an incremental fashion—ideally without overwhelming ourselves, or overwhelming those who consume the data we produce or incur a too-high processing latency.
By first-class concept, we mean that we need to be able to reason about streams as values, manipulate streams, join streams, or split them apart. Ideally, we need to land on a set of different patterns for stream processing and integration, along the same lines as the classic EIP.
Functional programming lends itself very well to stream transformation, and it is no coincidence the industry has standardized on a simple set of functional combinators that any modern stream-based DSL needs to support. Examples of these include map, flatMap, filter, groupBy, and zip, and together they form a core part of our pattern language and vocabulary for stream processing.
What is interesting is that these functional combinators—let’s call them “shapes”—are so high level, generic, powerful, composable, and reusable that the need for relying on explicit APIs and abstractions for EIP vanish[5]. Instead, the necessary integration patterns can be composed on an as-needed basis using our reusable shapes for stream processing.
From one perspective, stream processing is all about integration: ingest data from different sources and try to mine knowledge from it in real time before pushing it out to interested parties. But each implementation is doing it differently, which makes interoperability hard.
What we are lacking is a standardized way to integrate stream processing products, databases, traditional standardized protocols, and legacy enterprise products.
The need for flow control
One of the key realizations one develops when integrating components of unequal capacities is that flow control is not optional, but mandatory.
Flow control is essential for the system to stay responsive, ensuring that the sender does not send data downstream faster than the receiver is able to process. Failing to do so can, among other things, result in running out of resources, taking down the whole node, or filling up buffers, stalling the system as a whole. Therefore, flow control, especially through backpressure (see Figure 1), is essential in order to achieve resilience in a stream/integration pipeline.
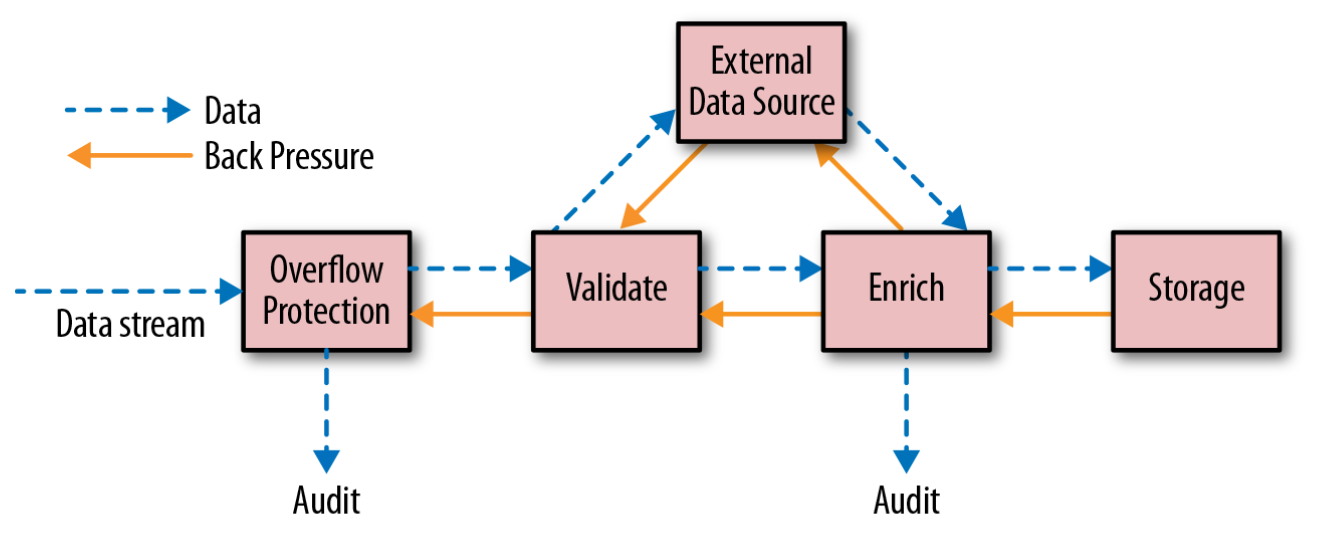
Also, during an inability to send or receive data, processing resources must be handed back and made available to other parts of the system, allowing the system to scale to many concurrent integration pipelines.
Reactive streams: A call to arms
To address the problem of flow control, an initiative called reactive streams was created in late 2013 to “provide a standard for asynchronous stream processing with non-blocking backpressure.”
Reactive streams is a set of four Java interfaces (publisher, subscriber, subscription, and processor), a specification for their interactions, and a technology compatibility kit (TCK) to aid and verify implementations.
The reactive streams specification has many implementations and was recently adopted into JDK 9 as the Flow API. Crucially, it provides the assurance that connecting publishers, processors, and subscribers—no matter who implemented them—will provide the flow control needed. When it comes to flow control, all components in the processing pipeline need to participate.
Toward reusable shapes for integration
We need to be able to reason about transformational shapes (see Figure 2)—how data is processed (separately from the sources and sinks), where data comes from and ends up. We also need to decouple the notion of representational shape from sources and sinks so we can disconnect internal representation from external representation.
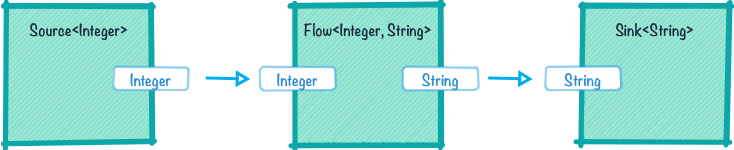
Furthermore, we want to be able to reuse the encoding and decoding of data separately from the transformation. That means encryption/decryption, compression/decompression, and other data representational concerns ought to be reusable and not depend on the medium used to facilitate the transfer of information/data.
Getting started with reactive integration
The Alpakka project is an open source library initiative to implement stream-aware, reactive, integration pipelines for Java and Scala. It is built on top of Akka Streams, and has been designed from the ground up to understand streaming natively and provide a DSL for reactive and stream-oriented programming, with built-in support for backpressure through implementing the reactive streams standard.
The DSL allows for designing reusable “graph blueprints” of data processing schematics—built from the reusable shapes—that can then be materialized[6] into running stream processing graphs.
The basic shapes in Akka Streams, which Alpakka is built with, are:
- Source<Out, M>—which represents a producer of data items of type “Out”, and yields a value of type “M” when materialized.
- Sink<In, M>—which represents a consumer of data items of type “In”, and yields a value of type “M” when materialized.
- Flow<In, Out, M>—which represents a consumer of data items of type “In” and a producer of data items of type “Out”, and yields a value of type “M” when materialized.
Alpakka has a sizeable and growing set of connectors[7] implementing support for most standard enterprise protocols (i.e., HTTP, TCP, FTP, MQTT, JMS), databases (i.e., JDBC, Cassandra, HBase, MongoDB) and infrastructure products (i.e., AWS, Kafka, Google Cloud, Spring, ElasticSearch).
From one-off scripts to reusable blueprints
Using shell scripts for integration work is a rather old and common practice; that being said, it is unfortunately suffering from a couple of different problems: those scripts are rarely tested, rarely version-controlled, typically “stringly-typed” throughout (communication using sequences of characters), and rarely composable in functionality but composable on the outside—via files or similar.
Wouldn’t it be cool if your typical integration workloads could be reusable, composable blueprints that aren’t tied to the nature of where the data comes from or goes to?
Let’s take a look at a code snippet of a simple streaming pipeline to better understand how these pieces fit together. This piece of Java code is using Alpakka to produce a series of integers ranging from 1 to 100 (a source), run each integer through a pair of transformation flows (using the map function) that turns it into a string, before passing the strings down to a sink that prints them out, one by one:
finalRunnableGraph<NotUsed>blueprint=Source.range(1,100).map(e->e.toString()).map(s->s+s).to(Sink.foreach(s->System.out.println(s)));// Materializes the blueprint and runs it asynchronously.blueprint.run(materializer);
If we break this snippet down into its constituents we get three distinct reusable pieces (shapes):
- Source.range(1, 100): is the source stage that is producing/ingesting the data, and is of type Source<Int, NotUsed>
- map(e -> e.toString): is a flow stage that is performing a transformation—turning Integers into Strings—and is of type Flow<Int, String, NotUsed>
- map(s -> s + s): is a flow stage that is performing a transformation—concatenating Strings—and is of type Flow<String, String, NotUsed>
- to(Sink.foreach(s -> System.out.println(s)): is the sink stage that is receiving the transformed output and potentially running side-effects, and is of type Sink<String, CompletionStage<Done>>
When all inputs and outputs have been attached, the result is a RunnableGraph<NotUsed>, which means that the blueprint is now ready to be materialized, and upon materialization, it will start executing the pipeline asynchronously and return, in this case[8], an instance of NotUsed[9] to the caller.
As we’ve discussed previously, most of the time, coupling between sources, transformations, and sinks impair composability and reusability, so if we break the example up into its constituents, we end up with the following:
finalSource<Integer,NotUsed>source=Source.range(1,100);finalFlow<Integer,String,NotUsed>transformation1=Flow.of(Integer.class).map(e->e.toString());finalFlow<String,String,NotUsed>transformation2=Flow.of(String.class).map(s->s+s);finalSink<String,CompletionStage<Done>>sink=Sink.foreach(s->System.out.println(s));finalRunnableGraph<NotUsed>blueprint=source// elements flow from the source.via(transformation1)// then via (through) transformation1.via(transformation2)// then via (through) transformation2.to(sink);// then to the sinkblueprint.run(materializer);
As you can see, the composability of the stream pipeline is driven by the types and is verified at compile time by the type system. If we want to reuse the transformation, or extend it, we can now do so without duplication of logic. Different sources, and sinks, can be used—and reused—effortlessly, in a fully typesafe manner.
Connecting all the things!
Enough with theory and conceptual discussions—it’s time to take a practical problem and see how we can solve it using a reactive and stream-native approach to enterprise integration. We will take a look at how to design a simple integration system connecting orders to invoices, allowing us to hook up orders from various sources, transform them, and perform business logic, before creating invoices that are pushed downstream into a pluggable set of sinks.
The sample project can be found on GitHub, in case you are interested in cloning it and running or modifying it.
Create the domain objects
Let’s start by creating domain objects for our sample project, starting with a very rudimentary Order class.
finalpublicclassOrder{publicfinallongcustomerId;publicfinallongorderId;// More fields would go here, omitted for brevity of the example@JsonCreatorpublicOrder(@JsonProperty("customerId")longcustomerId,@JsonProperty("orderId")longorderId){this.customerId=customerId;this.orderId=orderId;}// toString, equals & hashCode omitted for brevity}
We’re going to be receiving orders, and from those orders we’ll want to create invoices. So, let’s create a bare-minimum Invoice class[10].
finalpublicclassInvoice{publicfinallongcustomerId;publicfinallongorderId;publicfinallonginvoiceId;@JsonCreatorpublicInvoice(@JsonProperty("customerId")longcustomerId,@JsonProperty("orderId")longorderId,@JsonProperty("invoiceId")longinvoiceId){this.customerId=customerId;this.orderId=orderId;this.invoiceId=invoiceId;}// toString, equals & hashCode omitted for brevity}
Let’s also create a Transport[11] enumeration so we can easily instruct the main method where we want to read our orders from, and where we want to produce our invoices to.
enumTransport{file,jms,test;}
Bootstrap the system
Now, let’s create a “main method” so we can execute this example from a command line. As arguments, the invoker will have to specify which transport is going to be used from the input, as well as the output, of the program.
publicstaticvoidmain(finalString[]args)throwsException{if(args.length<2)thrownewIllegalArgumentException("Syntax: [file, jms, test](source) [file, jms, test](sink)");finalTransportinputTransport=Transport.valueOf(args[0]);finalTransportoutputTransport=Transport.valueOf(args[1]);...}
Since we’re going to use Alpakka, which is based on Akka, to construct our integration pipeline, we first need to create what’s called an ActorSystem—the main entrypoint to Akka-based applications.
finalActorSystemsystem=ActorSystem.create("integration");
Now we need to create an ActorMaterializer that will be responsible for taking the blueprints of our integration pipelines and executing them.
finalActorMaterializermaterializer=ActorMaterializer.create(system);
Also, since we want to use the JDK CompletionStage at certain points in this exercise, we’re going to have them execute their logic on the Executor associated with the ActorSystem. So, let’s get a reference to it.
finalExecutorexec=system.dispatcher();
Generate a source of domain objects (for testing purposes)
We’ll want to generate a stream of orders, for example for testing or, as we’ll see further along in this example, to have an in-memory data source. In order to achieve this, we’ll create an unbounded stream of orders by repeating a dummy value—in this case, the empty string—and for each of those, generate an Order instance using a random generator.
finalSource<Order,NotUsed>generateOrders=Source.repeat("").map(unused->{finalRandomr=ThreadLocalRandom.current();returnnewOrder(r.nextLong(),r.nextLong());});
In order to create a test datasource, we will randomly generate 1,000 orders using the generateOrders source.
finalSource<Order,?>fromTest=generateOrders.take(1000);
Serialize domain objects into JSON
We’re going to serialize and deserialize JSON—a format we’ve chosen for this example. First, we define how bytes in UTF-8 encoding will be converted to strings. The “1024”-argument to the JsonFraming.objectScanner method means that every Order is at most 1KB large[12].
finalFlow<ByteString,String,NotUsed>bytesUtf8ToJson=JsonFraming.objectScanner(1024).map(bytes->bytes.utf8String());finalFlow<String,ByteString,NotUsed>jsonToUtf8Bytes=Flow.of(String.class).map(ByteString::fromString);
We also need to be able to convert strings containing JSON to POJOs (plain old Java objects) and vice versa. Most notably, we’ll need to read Orders from JSON and write Invoices to JSON. We also intersperse[13] the individual Invoice JSON with commas and newlines to make the output nicer to read.
finalObjectMappermapper=newObjectMapper();finalObjectReaderreadOrder=mapper.readerFor(Order.class);finalObjectWriterwriteInvoice=mapper.writerFor(Invoice.class);finalFlow<String,Order,NotUsed>jsonToOrder=Flow.of(String.class).map(readOrder::<Order>readValue);finalFlow<Invoice,String,NotUsed>invoiceToJson=Flow.of(Invoice.class).map(writeInvoice::writeValueAsString).intersperse(",\n\r");
Integrating with File IO
One of the possible datasources is a file containing orders, in this case named “orders.json”. Since the Orders in this file is stored as JSON, we need to first transform the raw bytes in the file to UTF-8 encoded characters and then construct Orders from these characters—we achieve this by composing the source with the bytesUtf8ToJson and the jsonToOrder flows using the via combinator, which connects flows together.
finalSource<Order,?>fromFile=FileIO.fromPath(Paths.get("orders.json")).via(bytesUtf8ToJson).via(jsonToOrder);
Integrating with JMS
Another possible data source for integration is JMS (Java messaging service). Let’s try it out by connecting to a JMS broker and subscribe to its “orders” topic to start receiving the orders that are sent to it.
finalSource<Order,?>fromJms=JmsSource.textSource(JmsSourceSettings.create(connectionFactory).withQueue("orders")// If you want to close the stream after an idle timeout// uncomment this line below, and tweak the duration if needed//.takeWithin(FiniteDuration.create(2, TimeUnit.SECONDS)).via(jsonToOrder);
Creating our sinks
Once we have processed our Orders, we need to send them somewhere. Let’s start by defining a test destination for our Invoices. Since this approach will store the generated Invoices in memory, we have to be careful not to create too many Invoices—nothing that would work in production, but it is a good example for how it could be used in a test.
finalSink<Invoice,?extendsCompletionStage<?>>toTest=Sink.<Invoice>seq();
Another common (and more useful) destination for information is a plain file. In this case, we’ll want to be able to serialize our Invoices as UTF-8 encoded JSON to the file system, more specifically to a file named “invoices.json”.
finalSink<Invoice,?extendsCompletionStage<?>>toFile=invoiceToJson.via(jsonToUtf8Bytes).toMat(FileIO.toPath(Paths.get("invoices.json")),Keep.right());
A third option for a destination of Invoices in our example is a JMS topic. Let’s connect to the JMS broker and get ready to publish the Invoices to a topic called “invoices”.
finalSink<Invoice,?extendsCompletionStage<?>>toJms=invoiceToJson.toMat(JmsSink.textSink(JmsSinkSettings.create(connectionFactory).withQueue("invoices")),Keep.right());
If you are wondering about what the toMat method or Keep.right directive is all about, it instructs Akka Streams to keep the JmsSink’s materialized value, which is a CompletionStage that is completed when the stream is done.
Customizing the integration pipeline
In order to create some visibility into our processing pipeline, we’re going to create two Flows that will send everything flowing through them to a side channel. In this case, to a sink that simply prints them out to stdout[14] (standard out).
finalFlow<Order,Order,NotUsed>logInput=Flow.of(Order.class).alsoTo(Sink.foreach(order->System.out.println("Processing order: "+order)));finalFlow<Invoice,Invoice,NotUsed>logOutput=Flow.of(Invoice.class).alsoTo(Sink.foreach(invoice->System.out.println("Created invoice: "+invoice)));
In a real-world system, you might want to add validation logic to incoming orders, so let’s add a validation stage that can take care of this for us. Our simplified validation stage below simply passes anything through, and as an exercise, you can change it to verify properties of your orders, where one option is to discard all invalid orders, another to send invalid orders to a different output sink, or whatever you deem appropriate.
finalFlow<Order,Order,NotUsed>validate=Flow.of(Order.class);
Another common situation is when one wants to “enrich” inbound data with additional information. If you want to do that, then a custom transformation flow is the place to do it. For example, one can make HTTP requests to a service to look up information, and attach that to the order. Feel free to add this logic to the enrich stage below.
finalFlow<Order,Order,NotUsed>enrich=Flow.of(Order.class);
Finally, we need to convert orders into invoices so that our pipeline can start to add customer value. You can make this transformation and elaborate as needed.
finalFlow<Order,Invoice,NotUsed>xform=Flow.of(Order.class).map(order->newInvoice(order.customerId,order.orderId,ThreadLocalRandom.current().nextLong()));
Assemble the full pipeline
Let’s take all the pieces of reusable stream processing blueprints and compose them into a single pipeline that encapsulates the order processing logic. In our case, that is the validation flow composed with the enrichment flow, which is then composed with our order-to-invoice transformation logic.
At this point, we have separated out the order processing logic such that it is separated from where the orders come from, and where the invoices go to.
finalFlow<Order,Invoice,NotUsed>orderProcessing=validate.via(enrich).via(xform);
Now, let’s try out our orderProcessing logic. First we need to select a source for our orders. This selection is represented by the first Transport enum argument passed to the main method, so let’s use that to map the transport type to an actual sink.
finalSource<Order,?>input=(inputTransport==Transport.file)?fromFile:(inputTransport==Transport.jms)?fromJms:(inputTransport==Transport.test)?fromTest:Source.empty();
Similarly, we use the second Transport argument to select the destination.
finalSink<Invoice,?extendsCompletionStage<?>>output=(outputTransport==Transport.file)?toFile:(outputTransport==Transport.jms)?toJms:(outputTransport==Transport.test)?toTest:Sink.ignore();
At this point, we have all we need to compose a full integration pipeline: the input, the processing logic, and the output. Note the complete pipeline that we are creating is in itself a blueprint we can reuse multiple times—running several copies of this integration pipeline in parallel.
finalRunnableGraph<?extendsCompletionStage<?>>pipeline=input.via(logInput).via(orderProcessing).via(logOutput).toMat(output,Keep.right());
Here, the toMat method means that we create the sink for the pipeline by passing in the output argument, and the Keep.right directive means that we get a reference to what it materializes (the so-called “materialized value”): in this case, a CompletionStage instance, which is completed once the sink is closed, so we can keep track of it when we’re done.
Running the integration pipeline
Note that until this point, we have only described what we want to happen, not actually instructed Alpakka to make it happen, which now becomes as simple as the following piece of logic:
finalCompletionStage<?>done=pipeline.run(materializer);
The run method will use the materializer to transform the pipeline into a running stream turning orders into invoices between the two selected transports.
As discussed, the pipeline’s materialized value is a CompletionStage instance, which will become completed once the stream has finished its execution, and we can use that to manage the shutdown (including adding shutdown hooks if needed), and track when the program has completed.
To prove that it really does what is intended, here’s some sample output from running the example from a file with JSON formatted orders to a file with the invoices in JSON:
{"customerId":-2516180380437636182,"orderId":5140204751357487010,"invoiceId":-1929532331670255840},{"customerId":4447578045652995339,"orderId":-2598465089215501202,"invoiceId":-1959814745158207379},{"customerId":6639344057100895851,"orderId":-2338438557092483130,"invoiceId":6442126490918332720},{"customerId":-7455407343600198326,"orderId":6576315874496209408,"invoiceId":3470555577363488735},...
Summary
As you’ve seen in this article, it is possible to improve on the current state of the art in enterprise integration by applying reactive and stream-oriented programming—here illustrated through Alpakka and Akka Streams—allowing for a more scalable, composable, and functional architecture for interconnecting systems and applications. What’s noteworthy here is that nowhere in the code did you need to manually deal with flow control (backpressure) or IO. It was handled automatically by Alpakka, and you could describe transformations in a completely reusable, composable way.
You can visit the project’s GitHub repo to explore the code examples in greater detail. For more information about Alpakka and Akka Streams, have a look at the Alpakka and Akka Streams technical documentation. You can also learn more about reactive programming and reactive systems by checking out our article, “Reactive Programming vs. Reactive Systems,” or reading Bonér’s latest short book, “Reactive Microsystems.”