

 Lights (source: novelrobinson)
Lights (source: novelrobinson) Serverless Architecture is a new approach to building systems in the cloud. It incorporates Backends-as-a-Service (BaaS) – vendor-hosted, highly scalable, data and logic components to handle your needs for databases, messaging platforms, user management, and more. Additionally Serverless Architecture includes Functions-as-a-Service (FaaS) – the ability to write custom server-side software in small, event-triggered, functions, deployed to a fully-managed platform. FaaS outsources all deployment, resource allocation & provisioning, scaling, operating system maintenance and process monitoring.
Serverless system design can mean infrastructure cost savings because it keeps billing closely coupled to actual use of your systems; reduces effort for repetitive, error prone, lower-level technical operations; and significantly shortens time-to-market of new products and features.
Three classes of application that have good affinity for a serverless approach are:
- Synchronous API backend services for mobile applications, single page web apps, or B2B products. Serverless is useful for these types of applications because of the rapid time-to-market benefits it brings.
- ‘Glue’ logic for operations use and API integration. Serverless is great here because the technical overhead of running small pieces of infrastructure is much reduced in comparison to traditional architectures.
- Asynchronous message and file processing. These types of system can much more economically adjust to different loads using Serverless because of the automatic and rapid scaling benefits such services provide.
We’ll look at asynchronous message and file processing in depth in this article. We look at some typical applications, vendor services we can use in these systems, and how Java can be a great language choice for serverless data processing.
Examining real-life examples of serverless asynchronous processing
“Asynchronous message and file processing” isn’t a particularly precise description, and in fact encompasses a vast application space. But overall what we’re thinking about here are applications, or application components, that exhibit the following attributes:
- Are triggered by the event of a message, file or other type of object being instantiated and passed to their context
- Perform some amount of processing of the input event
- Output to one or more endpoints that may include data storage systems, messaging components, or API-oriented services, but do not synchronously return a result to the original event source
- May use local state, pulling in data from other external components, in order to complete processing
One of the canonical usages of AWS Lambda is image file processing. This is great for when you have a mobile app or single page web app that uploads large photos to a server, and you want a system to produce alternative versions of those images, like the workflow shown below.

Using the framework of our attribute list above, such image file processing applications:
- Are triggered by the creation of a original file in AWS S3
- Use image manipulation libraries to create new versions of the image
- Output these other versions to other locations in S3
- Are stateless, and require no external components
A more complicated example is a data pipeline. A data pipeline is an ecosystem of linked asynchronous services that perform operational data manipulation, extract-transform-load (ETL) processing of data into analytics systems, and other tasks. These systems are especially popular where there is a significant amount of data to continually be processed, for instance click data from websites and event data from mobile apps.
A serverless data pipeline is one that makes extensive use of a FaaS platform, such as AWS Lambda, for computational needs, and also uses a number of hosted Serverless BaaS infrastructure services for data storage and transport, like the pipeline shown below.
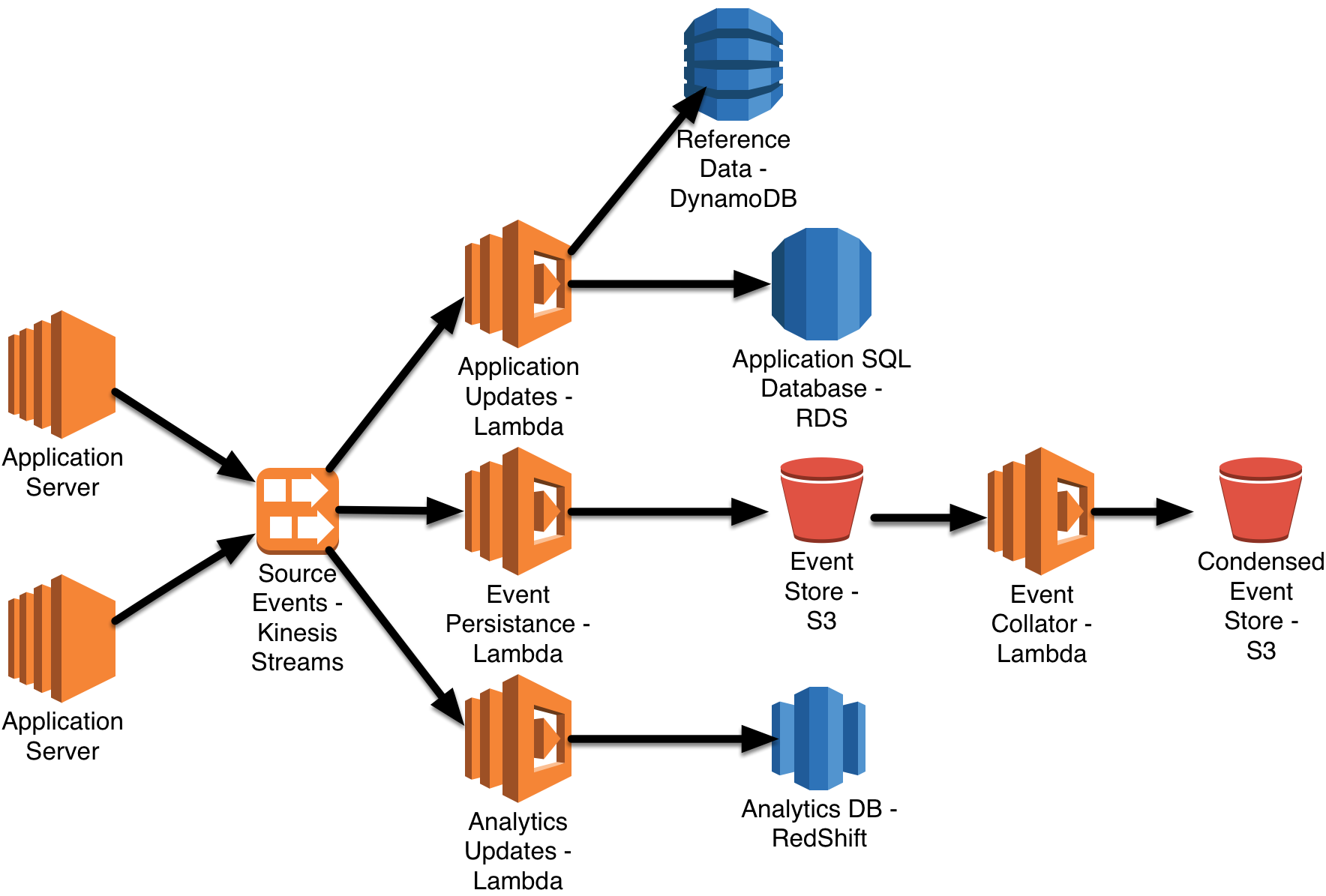
Note that this diagram has elements that are simplified from actual production usage, for example we would likely use Kinesis Firehose to load data into RedShift.
Each component of a data pipeline exhibits the attributes we defined above in the following ways:
- Is triggered by an event on a message bus, such as AWS Kinesis Streams or SNS; the creation of an object / file in AWS S3; or the update of a AWS DynamoDB table
- Typically interrogates and transforms the event, possibly splitting into sub-events, or combining a number of events together
- May create a new message on a different bus, write a new file to S3, update an operational or analytical database, or communicate with another service over HTTP
- Can make requests to remote services for other data needed to process an event. These services may be Serverless, like DynamoDB or a Lambda-backed HTTP service. Alternatively they may be non-Serverless, like Elasticache (Redis / Memcached), a SQL Database, etc. The component may cache local state across multiple messages, but cannot use it’s own local memory or disk as the only place that non-message data resides, due the ephemeral nature of FaaS.
Understanding the serverless vendor services from the AWS ecosystem
In our example applications above we described a number of services that our components could integrate with. In those examples all of the services are offered by Amazon Web Services, but other major cloud vendors (including Google and Microsoft) have their own equivalents. We’re using AWS because, at the time of this article, it’s the most widely used serverless vendor and offers a comprehensive range of serverless components.
Let’s quickly give a little more detail about these AWS services, in the context of data processing, and see how each can save money, reduce repetitive operations, and shorten your time to market.
- Lambda is AWS’ Functions-as-a-Service (FaaS) platform. Beyond the basic definition of a FaaS we saw at the beginning of this article, Lambda provides massive and highly reactive scaling, a lightweight programming model, and several different runtime language options, including Javascript, Python, Java / JVM, and C#.
- S3 is one of AWS’ oldest services and performs object storage in a way that feels like an ‘infinite file store’. It provides huge scale, high durability and precise and reasonable costs. Importantly it also integrates closely with Lambda – S3 events such as ‘put object’ and ‘delete object’ can be tied to one or more lambda functions, restricted by scope such as S3 ‘bucket’ (a top level S3 container), path / object name prefix, and object name suffix (to filter by, e.g., file extension)
- Kinesis Streams is AWS’ high-throughput, durable, replicated, ordered log. What does this mean? In short it’s Amazon’s version of a system similar to Apache Kafka – a highly scalable data store that is often used as a publish-subscribe message bus, and more besides. Lambda integrates well with Kinesis Streams to perform message processing.
- SNS is another AWS message bus, but it’s more simple and designed for much smaller volumes. If you don’t have a huge amount of streaming data, but still want a pub-sub messaging system that integrates tightly with Lambda, then you’d be wise to look at SNS.
- DynamoDB is AWS’ high performance NoSQL database service. It requires no managing of underlying hosts by the user, and costs are based on required read and write throughput (which can be adjusted through the day up and down, optionally with auto-scaling.) DynamoDB is a popular choice to use as backing store for Lambda since it can scale in the same way Lambda can – quickly and massively! But it can also be used as an event source for Serverless data processing with Lambda, through the use of the DynamoDB Streams with Lambda triggers.
These five services are all serverless. In the case of Kinesis and DynamoDB there’s a small asterisk, but they are effectively serverless. With Kinesis scaling isn’t automatic, and for both Kinesis and DynamoDB costs don’t quite wind down to zero when the system isn’t in use – both of these aspects are useful traits of most other serverless services. For more detail on this we refer you to Chapter 5 of our What is Serverless? report.
Incorporating non-serverless services into your architecture
It’s perfectly reasonable to also incorporate non-Serverless services as part of an overall generally Serverless approach. For example you might have a Lambda function writing to a SQL database. Even though a SQL database isn’t serverless in how it scales, it might still be fully vendor managed, as is the case with AWS RDS.
Further you might include a non-Serverless compute component as part of an otherwise-serverless data pipeline. An example here is where you want to perform concatenation and/or de-duplication of a large number of messages from a Kinesis bus. In this case a traditional server component running in EC2, or in a container on ECS, might be more appropriate than Lambda.
One area to be mindful of when mixing serverless and non-serverless technologies in such a hybrid application is that these types of components often have different scaling capabilities, and without some thoughtful design you may end up overloading one component from another.
Implementing data processing functions in Java
We’ve mentioned already that in the AWS ecosystem, AWS Lambda is the platform for writing FaaS code, and we also said that Lambda functions can be implemented in several languages, including Java.
Java has a bad reputation in some circles of the Lambda world, and that’s because it has a higher cold-start latency overhead than Javascript and Python. Cold starts are what occur when AWS creates a new container for your function under the covers. This happens when you run a new version of a function for the first time, when AWS scales the function up, and in a few other scenarios. Cold start overhead for Java Lambda functions can be large – several seconds in the worst case in specific scenarios. However, for data processing functions, Java is often actually a very appropriate choice of language for several reasons:
- Cold-start impact can often be reduced to just a few hundreds of milliseconds with some fairly simple tuning. For many asynchronous event processing systems this is perfectly reasonable. Further, for systems continually processing events, only a tiny fraction might be subject to a cold start. And by tiny we mean possibly as small as 0.001% .
- When processing a fairly continuous stream of events Java can often perform with a lower latency than Javascript and Python, on average. Not only is this good for application performance, but for even moderately complex lambda functions that take longer than 100ms to run you may see cost savings using Java as your environment due to the highly precise way in which Lambda is billed.
- Since there are a vast class of existing non-Serverless data processing applications already implemented in Java you may see opportunities for code re-use by porting Java domain logic from an older application to a new Lambda component.
Conclusions
Serverless architectures offer significant benefits in terms of infrastructure cost, labor and time-to-market. In this article we’ve shown how serverless architectures can be used to build effective serverless data processing applications of various types and complexity.
To learn more about serverless we recommend our O’Reilly report, What is Serverless? especially the sections on Benefits and Limitations. We also write and speak extensively about both introductory and in-depth topics regarding serverless, which you can access on our website.
Serverless is still a new way of building systems – when you use these ideas you won’t have signposts to guide you along every step of the path. Over the next couple of years the best ways to use these technologies will become much clearer, and we expect more fascinating case studies to be written. But for people willing to roll up their sleeves today there are already many advantages to be gained from this exciting evolution of our industry.