


 Crossing stairways (source: stevepb via Pixabay)
Crossing stairways (source: stevepb via Pixabay) Velocity ushered in a radical change to our industry when, in 2009, John Allspaw and Paul Hammond took the stage and gave their then-revolutionary talk “10 Deploys Per Day.” Just seven years later, automated, as-needed deployments that are part of a larger continuous delivery pipeline are now commonplace. We’ve seen not just the rise of DevOps, but a massive re-thinking and re-tooling of operations and systems for internet-driven businesses. And along the way, there’s also been a rise in the complexity of the systems being built.
We have reached a point where we can no longer understand, see, or control all the component parts of the systems we are building, both technical and social/organizational; they are increasingly complex and distributed. What we’re seeing is an industry working very hard to become more resilient in the face of that complexity. We have begun to accept that failure is inevitable and adopt new strategies, tactics, tools, and approaches to deal with that acceptance.
A distributed systems approach to speed and resilience
Velocity, by definition, consists of speed focused in a specific direction. As the industry has evolved, we are adjusting the trajectory of our Velocity conference to reflect this fundamental shift—from web performance and operations toward a more inclusive systems stack covering:
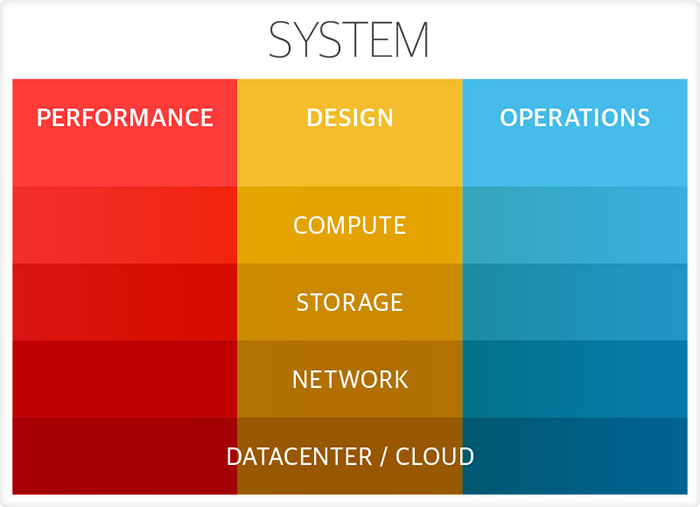
This expands Velocity’s scope into new domains, looking at performance and operations from the bottom of the stack right up to the customer, while retaining its focus on moving fast and being resilient.
Why distributed systems?
Most organizations building modern web sites and/or apps are distributed systems, whether they realize it or not. The decentralized, networked nature of the internet demands it, but those demands are challenging and capricious. Long gone are the days of simply thinking about latency in client/server interactions; now engineers and operators alike are dealing with microservices, containers, an endless array of delivery devices, and ever-increasing demands for 24/7 availability. We aim to help people navigate this shifting landscape and the expanding sprawl of systems, tools, and philosophies. Some of the main concepts we’ll be exploring include:
- Distributed systems fail in unpredictable ways
- Solving the problem of “it’s slow” requires a systems-thinking approach
- Monitoring is critical
- Cultural decisions about your systems matter as much as technical ones
A common theme across all these areas is resilience—designing and building systems that expect failure and can adapt to avoid catastrophic results. We’re looking for a deep and diverse set of perspectives on resilience, from fault injection to distributed tracing, orchestration, capacity management, networking, distributed data, to the emerging set of technical leadership skills required to navigate these domains.
The first 2017 Velocity Conference is taking place in San Jose, California, June 19-22. We look forward to seeing you there.