
 (source: Gualtiero on Flickr)
(source: Gualtiero on Flickr) For the last few millennia, libraries have been the custodians of human knowledge. By collecting books, and making them findable and accessible, they have done an incredible service to humanity. Our modern society, culture, science, and technology are all founded upon ideas that were transmitted through books and libraries.
Then the web came along, and allowed us to also publish all the stuff that wasn’t good enough to put in books, and do it all much faster and cheaper. Although the average quality of material you find on the web is quite poor, there are some pockets of excellence, and in aggregate, the sum of all web content is probably even more amazing than all libraries put together.
Google (and a few brave contenders like Bing, Baidu, DuckDuckGo and Blekko) have kindly indexed it all for us, acting as the web’s librarians. Without search engines, it would be terribly difficult to actually find anything, so hats off to them. However, what comes next, after search engines? It seems unlikely that search engines are the last thing we’re going to do with the web.
What if you had your own web crawl?
A small number of organizations, including Google, have crawled the web, processed, and indexed it, and generated a huge amount of value from it. However, there’s a problem: those indexes, the result of crawling the web, are hidden away inside Google’s data centers. We’re allowed to make individual search queries, but we don’t have bulk access to the data.
Imagine you had your own copy of the entire web, and you could do with it whatever you want. (Yes, it would be very expensive, but we’ll get to that later.) You could do automated analyses and surface the results to users. For example, you could collate the “best” articles (by some definition) written on many different subjects, no matter where on the web they are published. You could then create a tool which, whenever a user is reading something about one of those subjects, suggests further reading: perhaps deeper background information, or a contrasting viewpoint, or an argument on why the thing you’re reading is full of shit.
(I’ll gloss over the problem of actually implementing those analyses. The signal-to-noise ratio on the web is terrible, so it’s difficult to determine algorithmically whether a particular piece of content is any good. Nevertheless, search engines are able to give us useful search results because they spend a huge amount of effort on spam filtering and other measures to improve the quality of results. Any product that uses web crawl data will have to decide what is noise, and get rid of it. However, you can’t even start solving the signal-to-noise problem until you have the raw data. Having crawled the web is step one.)
Unfortunately, at the moment, only Google and a small number of other companies that have crawled the web have the resources to perform such analyses and build such products. Much as I believe Google try their best to be neutral, a pluralistic society requires a diversity of voices, not a filter bubble controlled by one organization. Surely there are people outside of Google who want to work on this kind of thing. Many a start-up could be founded on the basis of doing useful things with data extracted from a web crawl.
The web link graph
The idea of collating several related, useful pieces of content on one subject was recently suggested by Justin Wohlstadter (indeed it was a discussion with Justin that inspired me to write this article). His start-up, Wayfinder, aims to create such cross-references between URLs, by way of human curation. However, it relies on users actively submitting links to Wayfinder’s service.
I argued to Justin that I shouldn’t need to submit anything to a centralized database. By writing a blog post (such as this one) that references some things on the web, I am implicitly creating a connection between the URLs that appear in this blog post. By linking to those URLs, I am implicitly suggesting that they might be worth reading. (Of course, this is an old idea.) The web is already, in a sense, a huge distributed database.
By analogy, citations are very important in scientific publishing. Every scientific paper uses references to acknowledge its sources, to cite prior work, and to make the reader aware of related work. In the opposite direction, the number of times a paper is cited by other authors is a metric of how important the work is, and citation counts have even become a metric for researchers’ careers.
Google Scholar and bibliography databases maintain an index of citations, so you can find later work that builds upon (or invalidates!) a particular paper. As a researcher, following those forward and backward citations is an important way of learning about the state of the art.
Similarly, if you want to analyze the web, you need to need to be able to traverse the link graph and see which pages link to each other. For a given URL, you need to be able to see which pages it links to (outgoing links) and which pages link to it (incoming links).
You can easily write a program that fetches the HTML for a given URL, and parses out all the links — in other words, you can easily find all the outgoing links for an URL. Unfortunately, finding all the incoming links is very difficult. You need to download every page on the entire web, extract all of their links, and then collate all the web pages that reference the same URL. You need a copy of the entire web.
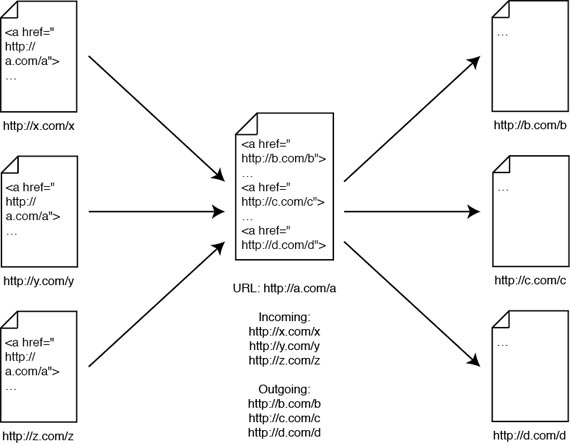
Publicly available crawl data
An interesting move in this direction is CommonCrawl, a nonprofit. Every couple of months they send a crawler out into the web, download a whole bunch of web pages (about 2.8 billion pages, at latest count), and store the result as a publicly available data set in S3. The data is in WARC format, and you can do whatever you want with it. (If you want to play with the data, I wrote an implementation of WARC for use in Hadoop.)
As an experiment, I wrote a simple MapReduce job that processed the entire CommonCrawl data set. It cost me about $100 in EC2 instance time to process all 2.8 billion pages (a bit of optimization would probably bring that down). Crunching through such quantities of data isn’t free, but it’s surprisingly affordable.
The CommonCrawl data set is about 35 TB in size (unparsed, compressed HTML). That’s a lot, but Google says they crawl 60 trillion distinct pages, and the index is reported as being over 100 PB, so it’s safe to assume that the CommonCrawl data set represents only a small fraction of the web.
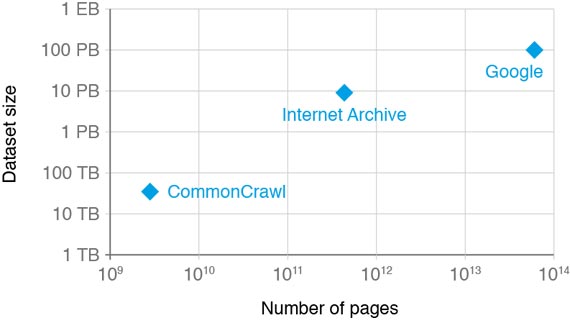
CommonCrawl is a good start. But what would it take to create a publicly available crawl of the entire web? Is it just a matter of getting some generous donations to finance CommonCrawl? But if all the data is on S3, you have to either use EC2 to process it or pay Amazon for the bandwidth to download it. A long-term solution would have to be less AWS-centric.
I don’t know for sure, but my gut instinct is that a full web crawl would best be undertaken as a decentralized effort, with many organizations donating some bandwidth, storage, and computing resources toward a shared goal. (Perhaps this is what Faroo and YaCy are doing, but I’m not familiar with the details of their systems.)
An architectural sketch
Here are some rough ideas on how a decentralized web crawl project could look.
The participants in the crawl can communicate peer-to-peer, using something like BitTorrent. A distributed hash table can be used to assign a portion of the URL space to a participant. That means each URL is assigned to one or more participants, and that participant is in charge of fetching the URL, storing the response, and parsing any links that appear in the page. Every URL that is found in a link is sent to the crawl participant to whom the URL is assigned. The recipient can ignore that message if it has already fetched that URL recently.
The system will need to ensure it is well-behaved as a whole (obey robots.txt, stay within rate limits, de-duplicate URLs that return the same content, etc.). This will require some coordination between crawl participants. However, even if the crawl was done by a single organization, it would have to be distributed across multiple nodes, probably using asynchronous message passing for loose coordination. The same principles apply if the crawl nodes are distributed across several participants — it just means the message-passing is across the Internet rather than within one organization’s data center.
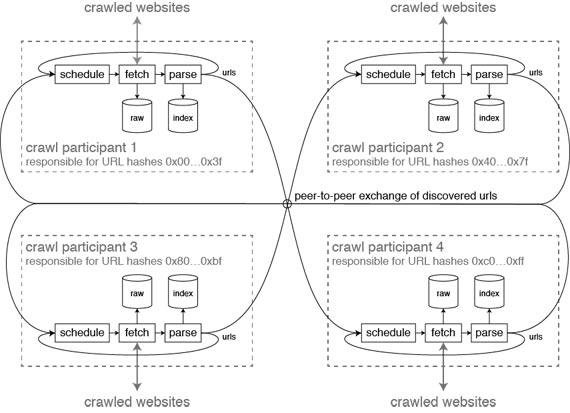
There remain many questions. What if your crawler downloads some content that is illegal in your country? How do you keep crawlers honest (ensuring they don’t manipulate the crawl results to their own advantage)? How is the load balanced across participants with different amounts of resources to offer? Is it necessary to enforce some kind of reciprocity (you can only use crawl data if you also contribute data), or have a payment model (bitcoin?) to create an incentive for people to run crawlers? How can index creation be distributed across participants?
(As an aside, I think Samza‘s model of stream computation would be a good starting point for implementing a scalable distributed crawler. I’d love to see someone implement a proof of concept.)
Motivations for contributing
Why would different organizations — many of them probably competitors — potentially collaborate on creating a public domain crawl data set? Well, there is precedence for this, namely in open source software.
Simplifying for the sake of brevity, there are a few reasons why this model works well:
- Cost: Creating and maintaining a large software project (eg. Hadoop, Linux kernel, database system) is very expensive, and only a small number of very large companies can afford to run a project of that size by themselves. As a mid-size company, you have to either buy an off-the-shelf product from a vendor or collaborate with other organizations in creating an open solution.
- Competitive advantage: With infrastructure software (databases, operating systems) there is little competitive advantage in keeping a project proprietary because competitive differentiation happens at the higher levels (closer to the user interface). On the other hand, by making it open, everybody benefits from better software infrastructure. This makes open source a very attractive option for infrastructure-level software.
- Public relations: Companies want to be seen as doing good, and contributing to open source is seen as such. Many engineers also want to work on open source, perhaps for idealistic reasons, or because it makes their skills and accomplishments publicly visible and recognized, including to prospective future employers.
I would argue that all the same arguments apply to the creation of an open data set, not only to the creation of open source software. If we believe that there is enough value in having publicly accessible crawl data, it looks like it could be done.
Perhaps we can make it happen
What I’ve described is a pie in the sky right now (although CommonCrawl is totally real).
Collaboratively created data sets such as Wikipedia and OpenStreetMap are an amazing resource and accomplishment. At first, people thought the creators of these projects were crazy, but they turned out to work very well. We can safely say they have made a positive impact on the world, by summarizing a certain subset of human knowledge and making it freely accessible to all.
I don’t know if freely available web crawl data would be similarly valuable because it’s hard to imagine all the possible applications, which only arise when you actually have the data and start exploring it. However, there must be interesting things you can do if you have access to the collective outpourings of humanity. How about augmenting human intellect, which we’ve talked about for so long? Can we use this data to create fairer societies, better mutual understanding, better education, and such good things?
Cropped image by gualtiero on Flickr, used under a Creative Commons license.
This post is part of our ongoing exploration into Big Data Components and Big Data Tools and Pipelines. Kleppmann’s new book Designing Data-Intensive Applications is available in early release here.