Building a simple GraphQL server with Neo4j
How to implement a GraphQL API that queries Neo4j for a simple movie app.
 Louvre (source: jraffin)
Louvre (source: jraffin)
GraphQL is a powerful new tool for building APIs that allows clients to ask for only the data they need. Originally designed at Facebook to minimize data sent over the wire and reduce round-trip API requests for rendering views in native mobile apps, GraphQL has since been open sourced to a healthy community that is building developer tools. There are also a number of large companies and startups such as GitHub, Yelp, Coursera, Shopify, and Mattermark building public and internal GraphQL APIs.
Despite what the name seems to imply, GraphQL is not a query language for graph databases, it is instead an API query language and runtime for building APIs. The “Graph” component of the name comes from the graph data model that GraphQL uses in the frontend. GraphQL itself is simply a specification, and there are many great tools available for building GraphQL APIs in almost every language. In this post we’ll make use of graphql-tools by Apollo to build a simple GraphQL API in JavaScript that queries a Neo4j graph database for movies and movie recommendations. We will follow a recipe approach: first, exploring the problem in more detail, then developing our solution, and finally we discuss our approach. Good resources for learning more about GraphQL are GraphQL.org and the Apollo Dev Blog.

Learn faster. Dig deeper. See farther.
GraphQL by design can work with any database or backend system, however in this example we’ll be using the Neo4j graph database as our persistence layer. Why use a graph database with GraphQL? The idea of application data as a graph is an underpinning design choice of GraphQL. For example, think of customers who have placed orders that contain products—that’s a graph! GraphQL enables developers to translate their backend data into the application data graph on the frontend, but if we use a graph database on the backend we can do away with this impedance mismatch and we have graphs all the way down.
Problem
We’d like to build a simple GraphQL API for a movie app that can do two things:
- Search for movies by specifying a substring to be matched against movie titles.
- For each movie, show “recommended” or similar movies.
In a traditional REST-ish API approach we might create two separate endpoints, perhaps /movies/search and /movies/similar. One endpoint to search for movies by substring of the title, and another to return a list of similar movies. As we add additional features we might keep adding endpoints. With GraphQL, our API is served from a single endpoint /graphql that takes one or more GraphQL queries and returns JSON data in a shape that is specified by the GraphQL query – only the data requested by the client is returned. Let’s see how we can build this simple API.
Solution
We’ll be building a simple node.js JavaScript web server using Express.js to serve our GraphQL endpoint1.
Dependencies
First of all we’ll need a Neo4j database (with data) for our GraphQL server to query. For this example we’ll make use of a Neo4j Sandbox instance. Neo4j Sandbox allows us to quickly spin up a hosted Neo4j instance, optionally with existing datasets focused around specific use cases. We’ll use the Recommendations Neo4j Sandbox which includes data about movies and movie reviews and is designed to be used for generating personalized recommendations (for example, by using collaborative filtering to recommend movies based on similar users’ reviews).
We’ll be making use of a few dependencies for this GraphQL server. I won’t list them all here (you can see the full list in the package.json for this project, but there a few worth noting:
- Graphql-tools – a package for building GraphQL schema and resolvers in JavaScript, following the GraphQL-first development workflow from the folks at Apollo.
- express – the webserver for node.js
- Neo4j-driver – the official JavaScript driver for Neo4j. This driver will allow us to connect to and query Neo4j using Cypher, the query language for graph databases.
We’ll follow the “GraphQL First” development paradigm. In this approach, we start by defining a GraphQL schema. This schema defines the types and queries available in our API and then becomes the specification for the API. If we were building a complete application, the frontend developers could use this schema to build out the frontend while the backend team builds the backend in parallel, speeding development. Once we’ve defined our schema we’ll need to create resolver functions that are responsible for fetching data from Neo4j.
Schema
This schema will define the types and GraphQL queries that we’ll be able to use in our API. You can think of the schema as the API blueprint.
schema.js
// import graphql-tools
import { makeExecutableSchema } from 'graphql-tools';
// we’ll define our resolver functions in the next section
import resolvers from './resolvers';
// Simple Movie schema
const typeDefs = `
type Movie {
movieId: String!
title: String
year: Int
plot: String
poster: String
imdbRating: Float
genres: [String]
similar: [Movie]
}`;
type Query {
movies(subString: String!, limit: Int!): [Movie]
}
export default makeExecutableSchema({
typeDefs: typeDefs,
resolvers,
});
Resolvers
Each GraphQL field is resolved by a resolver function. The resolver function defines how data is fetched for that field.
resolvers.js
// import Neo4j driver
import {v1 as neo4j} from 'neo4j-driver';
// create Neo4j driver instance, here we use a Neo4j Sandbox instance. See neo4j.com/sandbox-v2, Recommendations example dataset
let driver = neo4j.driver("bolt://54.236.8.156:33471", neo4j.auth.basic("neo4j", "carburetor-requirement-kick"));
const resolveFunctions = {
Query: {
// here we define the resolver for the movies query, which searches for movies by title
// params object contains the values for the substring and limit parameters
movies(_, params) {
// query Neo4j for matching movies
let session = driver.session();
let query = "MATCH (movie:Movie) WHERE movie.title CONTAINS $subString RETURN movie LIMIT $limit;"
return session.run(query, params)
.then( result => { return result.records.map(record => { return record.get("movie").properties })})
},
},
Movie: {
// the similar field in the Movie type is an array of similar Movies
similar(movie) {
// we define similarity to be movies with overlapping genres, we could use a more complex
// Cypher query here to use collaborative filtering based on user ratings, see Recommendations
// Neo4j Sandbox for more complex examples
let session = driver.session(),
params = {movieId: movie.movieId},
query = `
MATCH (m:Movie) WHERE m.movieId = $movieId
MATCH (m)-[:IN_GENRE]->(g:Genre)<-[:IN_GENRE]-(movie:Movie)
WITH movie, COUNT(*) AS score
RETURN movie ORDER BY score DESC LIMIT 3
`
return session.run(query, params)
.then( result => { return result.records.map(record => { return record.get("movie").properties })})
},
genres(movie) {
// Movie genres are represented as relationships in Neo4j so we need to query the database
// to resolve genres
let session = driver.session(),
params = {movieId: movie.movieId},
query = `
MATCH (m:Movie)-[:IN_GENRE]->(g:Genre)
WHERE m.movieId = $movieId
RETURN g.name AS genre;
`
return session.run(query, params)
.then( result => { return result.records.map(record => { return record.get("genre") })})
}
},
};
export default resolveFunctions;
Server
Now that we’ve defined the GraphQL schema and resolver functions we are ready to serve the GraphQL endpoint, using Express.js.
server.js
import express from 'express';
import { graphqlExpress, graphiqlExpress } from 'graphql-server-express';
import bodyParser from 'body-parser';
import cors from 'cors';
import schema from './schema';
const app = express().use('*', cors());
app.use('/graphql', bodyParser.json(), graphqlExpress({
schema,
context: {},
}));
app.use('/graphiql', graphiqlExpress({
endpointURL: '/graphql'
}));
app.listen(8080, () => console.log(
`GraphQL Server running on http://localhost:8080/graphql`
));
If you’ve ever used Express this should look familiar, you’ll notice that we’re creating two endpoints and serving them on localhost:8080
/graphql– this will be our GraphQL API endpoint, handled by an executable schema (yet to be created) that we’re passing to thegraphqlExpressroute handler./graphiql– this endpoint will serve GraphiQL, an in-browser IDE for exploring GraphQL
Discussion
Let’s take a look at what we just did:
schema.js– Here we define our GraphQL schema using the GraphQL Schema Definition Language as a template string.resolvers.js– Here we declare our resolver functions. Resolver functions define how to fetch data for each GraphQL field, in this case from a Neo4j database. We use the Cypher query language to query Neo4j for movies and recommendations.server.js– Finally, we define our routes for our GraphQL endpoint (as well as the Graphiql IDE) and use thegraphql-server-expresshelper to create a Express.js server for our GraphQL API.
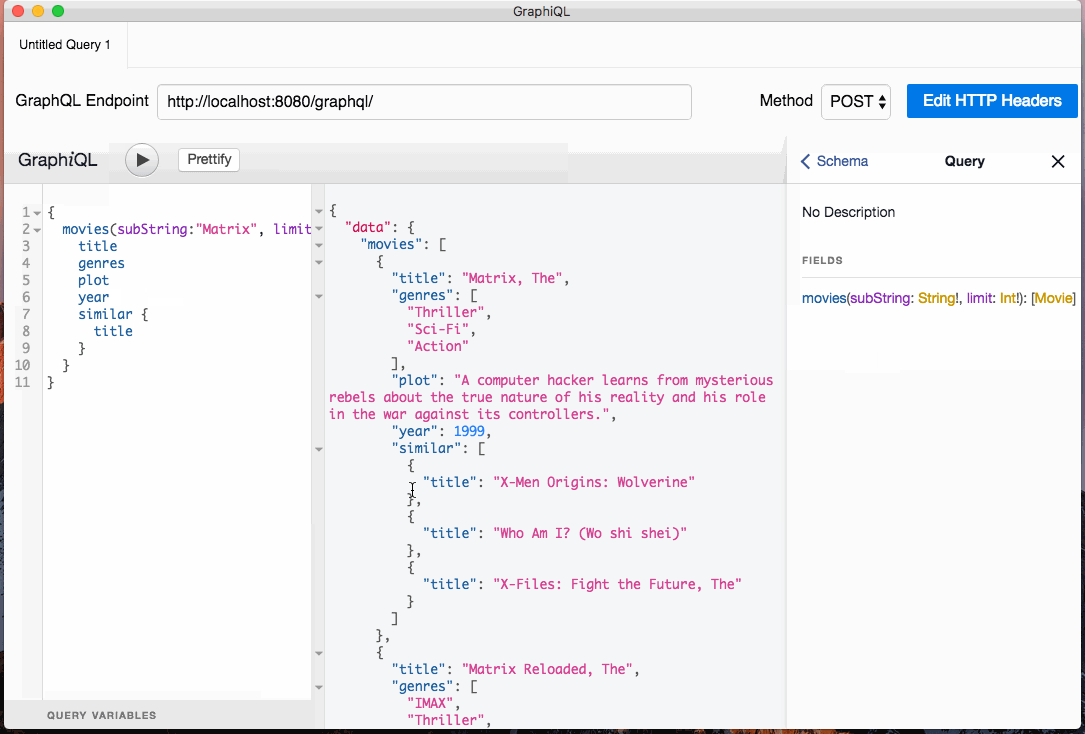
Now that we have our API running, let’s use the GraphiQL in-browser IDE for GraphQL to search for movies whose titles contain “Matrix” and find similar movies for each matching movie. We can load GraphiQL by opening http://loalhost:8080/graphiql in our browser and querying with this GraphQL query:
{
movies(subString: "Matrix", limit: 3) {
title
genres
plot
year
similar {
title
}
}
}
GraphQL is still new to almost everyone with the exception of Facebook, where it has been used since 2012, so many conventions and best practices are still being developed. However, GraphQL First Development is a philosophy the community has adopted which gives structure to the process of building a GraphQL API. By defining a contract for the API, expressed as a GraphQL schema, the frontend and backend developer teams can independently implement their applications, using the schema as a guide.
To make GraphQL First Development even easier with Neo4j, the Neo4j team has built neo4j-graphql-cli, a command line tool for easily spinning up a Neo4j backed GraphQL endpoint based on a user defined GraphQL schema that can optionally be annotated with Cypher queries – exposing the power of Cypher from within GraphQL. You can learn more about this here.
1 All code for this project is available on GitHub . This example is also available as an Apollo Launchpad Pad, which you can run live in the browser.↩