 Sky (source: Free-Photos)
Sky (source: Free-Photos) The patterns for how we develop software, both in teams and as individuals, are always evolving. The open source software movement has provided the software industry with somewhat of a Cambrian explosion of tools, frameworks, platforms, and operating systems—all with an increasing focus on flexibility and automation. A majority of today’s most popular open source tools focus on features that give software teams the ability to continuously deliver software faster than ever before possible, at every level, from development to operations.
Amazon’s Story
In the span of two decades, starting in the early ’90s, an online bookstore headquartered in Seattle called Amazon.com grew into the world’s largest online retailer. Known today simply as Amazon, the company now sells far more than just books. In 2015, Amazon surpassed Walmart as the most valuable retailer in the United States. The most interesting part of Amazon’s story of unparalleled growth can be summarized in one simple question: how did a website that started out as a simple online bookstore transform into one of the largest retailers in the world—without ever opening a single retail location?
It’s not hard to see how the world of commerce has been shifted and reshaped around digital connectivity, catalyzed by ever-increasing access to the internet from every corner of the globe. As personal computers became smaller, morphing into the ubiquitous smartphones, tablets, and watches we use today, we’ve experienced an exponential increase in accessibility to distribution channels that are transforming the way the world does commerce.
Amazon’s CTO, Werner Vogels, oversaw the technical evolution of Amazon from a hugely successful online bookstore into one of the world’s most valuable technology companies and product retailers. In June 2006, Vogels was interviewed in a piece for the computer magazine ACM Queue on the rapid evolution of the technology choices that powered Amazon’s growth. In the interview, Vogels talks about the core driver behind it.
A large part of Amazon.com’s technology evolution has been driven to enable this continuing growth, to be ultra-scalable while maintaining availability and performance.
Werner Vogels, “A Conversation with Werner Vogels,” ACM Queue 4, no. 4 (2006): pass:[14–22.]
Vogels goes on to state that for Amazon to achieve ultrascalability, it needed to move toward a different pattern of software architecture. He mentions that Amazon.com started as a monolithic application. Over time, as more and more teams operated on the same application, the boundaries of ownership of the codebase began to blur. “There was no isolation and, as a result, no clear ownership,” said Vogels.
Vogels pinpoints that shared resources such as databases made it difficult to scale out the overall business. The greater the number of shared resources, whether application servers or databases, the less control teams had when delivering features into production.
You build it, you run it.
Werner Vogels, CTO, Amazon
Vogels touches on a common theme that cloud native applications share: the idea that teams own what they are building. He goes on to say that “the traditional model is that you take your software to the wall that separates development and operations, and throw it over and then forget about it. Not at Amazon. You build it, you run it.”
In what has been one of the most reused quotes by prominent keynote speakers at some of the world’s premier software conferences, the words “you build it, you run it” would later become a slogan of a popular movement we know today simply as DevOps.
Many of the practices that Vogels spoke about in 2006 were seeds for popular software movements that are thriving today. Practices such as DevOps and microservices can be tied back to the ideas that Vogels introduced over a decade ago. While ideas like these were being developed at large internet companies similar to Amazon, the tooling around these ideas would take years to develop and mature into a service offering.
In 2006 Amazon launched a new product named Amazon Web Services (AWS). The idea behind AWS was to provide a platform, the same platform Amazon used internally, and release it as a service to the public. Amazon was keen to see the opportunity to commoditize the ideas and tooling behind that platform. Many of the ideas that Vogels introduced were already built into the Amazon.com platform; by releasing the platform as a service to the public, Amazon would enter a new market called the public cloud.
The ideas behind the public cloud were sound. Virtual resources could be provisioned on-demand without needing to worry about the underlying infrastructure. Developers could simply rent a virtual machine to house their applications without needing to purchase or manage the infrastructure. This approach was a low-risk self-service option that would help to grow the appeal of the public cloud, with AWS leading the way in adoption.
It would take years before AWS would mature into a set of services and patterns for building and running applications that are designed to be operated on a public cloud. While many developers flocked to these services for building new applications, many companies with existing applications still had concerns with migrations. Existing applications were not designed for portability. Also, many applications were still dependent on legacy workloads that were not compatible with the public cloud.
In order for most large companies to take advantage of the public cloud, they would need to make changes in the way they developed their applications.
The Promise of a Platform
Platform is an overused word today.
When we talk about platforms in computing, we are generally talking about a set of capabilities that help us to either build or run applications. Platforms are best summarized by the nature in which they impose constraints on how developers build applications.
Platforms are able to automate tasks that are not essential to supporting the business requirements of an application. This makes development teams more agile in the way they are able to support only the features that help differentiate value for the business.
Any team that has written shell scripts or stamped containers or virtual machines to automate deployment has built a platform, of sorts. The question is: what promises can that platform keep? How much work would it take to support the majority (or even all) of the requirements for continuously delivering new software?
When we build platforms, we are creating a tool that automates a set of repeatable practices. Practices are formulated from a set of constraints that translate valuable ideas into a plan.
Ideas: What are our core ideas of the platform and why are they valuable?
Constraints: What are the constraints necessary to transform our ideas into practices?
Practices: How do we automate constraints into a set of repeatable practices?
At the core of every platform are simple ideas that, when realized, increase differentiated business value through the use of an automated tool.
Let’s take for example the Amazon.com platform. Werner Vogels stated that by increasing isolation between software components, teams would have more control over features they delivered into production.
Ideas:
By increasing isolation between software components, we are able to deliver parts of the system both rapidly and independently.
By using this idea as the platform’s foundation, we are able to fashion it into a set of constraints. Constraints take the form of an opinion about how a core ideal will create value when automated into a practice. The following statements are opinionated constraints about how isolation of components can be increased.
Constraints:
Software components are to be built as independently deployable services.
All business logic in a service is encapsulated with the data it operates on.
There is no direct access to a database from outside of a service.
Services are to publish a web interface that allows access to its business logic from other services.
With these constraints, we have taken an opinionated view on how isolation of software components will be increased in practice. The promises of these constraints, when automated into practices, will provide teams with more control over how features are delivered to production. The next step is to describe how these constraints can be captured into a set of repeatable practices.
Practices that are derived from these constraints should be stated as a collection of promises. By stating practices as promises, we maintain an expectation with the platform’s users of how they will build and operate their applications.
Practices:
A self-service interface is provided to teams that allows for the provisioning of infrastructure required to operate applications.
Applications are packaged as a bundled artifact and deployed to an environment using the self-service interface.
Databases are provided to applications in the form of a service, and are to be provisioned using the self-service interface.
An application is provided with credentials to a database as environment variables, but only after declaring an explicit relationship to the database as a service binding.
Each application is provided with a service registry that is used as a manifest of where to locate external service dependencies.
Each of the practices listed above takes on the form of a promise to the user. In this way, the intent of the ideas at the core of the platform are realized as constraints imposed on applications.
Cloud native applications are built on a set of constraints that reduce the time spent doing undifferentiated heavy lifting.
When AWS was first released to the public, Amazon did not force its users to adhere to the same constraints that they used internally for Amazon.com. Staying true to the name Amazon Web Services, AWS is not itself a cloud platform, but rather a collection of independent infrastructure services that can be composed into automated tooling resembling a platform of promises. Years after the first release of AWS, Amazon began offering a collection of managed platform services, with use cases ranging from IoT (Internet of Things) to machine learning.
If every company needs to build its own platform from scratch, the amount of time delivering value in applications is delayed until the platform is fully assembled. Companies that were early adopters of AWS would have needed to assemble together some form of automation resembling a platform. Each company would have had to bake in a set of promises that captured the core ideas of how to develop and deliver software into production.
More recently, the software industry has converged on the idea that there is a basic set of common promises that every cloud platform should make. These promises will be explored throughout this book using the open source Platform as a Service (PaaS) Cloud Foundry. The core motivation behind Cloud Foundry is to provide a platform that encapsulates a set of common promises for quickly building and operating. Cloud Foundry makes these promises while still providing portability between multiple different cloud infrastructure providers.
The subject of much of this book is how to build cloud native Java applications. We’ll focus largely on tools and frameworks that help reduce undifferentiated heavy lifting, by taking advantage of the benefits and promises of a cloud native platform.
The Patterns
New patterns for how we develop software enable us to think more about the behavior of our applications in production. Both developers and operators, together, are placing more emphasis on understanding how their applications will behave in production, with fewer assurances of how complexity will unravel in the event of a failure.
As was the case with Amazon.com, software architectures are beginning to move away from large monolithic applications. Architectures are now focused on achieving ultra-scalability without sacrificing performance and availability. By breaking apart components of a monolith, engineering organizations are taking efforts to decentralize change management, providing teams with more control over how features make their way to production. By increasing isolation between components, software teams are starting to enter the world of distributed systems development, with a focus on building smaller, more singularly focused services with independent release cycles.
Cloud native applications take advantage of a set of patterns that make teams more agile in the way they deliver features to production. As applications become more distributed (a result of increasing isolation necessary to provide more control to the teams that own applications), the chance of failure in the way application components communicate becomes an important concern. As software applications turn into complex distributed systems, operational failures become an inevitable result.
Cloud native application architectures provide the benefit of ultra-scalability while still maintaining guarantees about overall availability and performance of applications. While companies like Amazon reaped the benefits of ultra-scalability in the cloud, widely available tooling for building cloud-native applications had yet to surface. The tooling and platform would eventually surface as a collection of open source projects maintained by an early pioneer of the public cloud: Netflix.
Scalability
To develop software faster, we are required to think about scale at all levels. Scale, in a most general sense, is a function of cost that produces value. The level of unpredictability that reduces that value is called risk. We are forced to frame scale in this context because building software is fraught with risks. The risks created by software developers are not always known to operators. By demanding that developers deliver features to production at a faster pace, we are adding to the risks of its operation without having a sense of empathy for its operators.
The result of this is that operators grow distrustful of the software that developers produce. The lack of trust between developers and operators creates a blame culture: people point fingers instead of looking at systemic problems that lead to, or at least precipitate, problems that negatively impact the business.
To alleviate the strain that is put on traditional structures of an IT organization, we need to rethink how software delivery and operations teams communicate. Communication between operations and developers can affect our ability to scale, as the goals of each party tend to become misaligned over time. To succeed at this requires a shift toward a more reliable kind of software development—one that puts emphasis on the experience of an operations team inside the software development process; one that fosters shared learning and improvement.
Reliability
The expectations that are created between teams (development, operations, user experience, etc.) are contracts. The contracts that are created between teams imply that some level of service is provided or consumed. By looking at how teams provide services to one another in the process of developing software, we can better understand how failures in communication can introduce risk that leads to failures down the road.
Service agreements between teams are created in order to reduce the risk of unexpected behavior in the overall functions of scale that produce value for a business. A service agreement between teams is made explicit in order to guarantee that behaviors are consistent with the expected cost of operations. In this way, services enable units of a business to maximize its total output. The goal here for a software business is to reliably predict the creation of value through cost—what we call reliability.
The service model for a business is the same model we use when we build software. This is how we guarantee the reliability of a system, whether in the software we produce to automate a business function or in the people we train to perform a manual operation.
Agility
We are beginning to find that there is no longer only one way to develop and operate software. Driven by the adoption of agile methodologies and a move towards Software as a Service (SaaS) business models, the enterprise application stack is becoming increasingly distributed. Developing distributed systems is a complex undertaking. The move toward a more distributed application architecture for companies is fueled by the need to deliver software faster and with less risk of failure.
Note
We can hear you exclaiming, “Agile? Isn’t agile dead??” Agile, as we use it, refers both to a wholistic, organization-wide fervor for delivering new value, and to the idea of responding quickly. We’re talking about little-a agile; we don’t talk about it in terms of a management practice. There are a lot of roads that lead to production, and we don’t care what management practice you embrace to get there. The key is to understand that agile is a value, not a destination.
The modern-day software-defined business seeks to restructure its development processes to enable faster delivery of software projects and continuous deployment of applications into production. Not only are companies wanting to increase the rate at which they develop software applications, but also to increase the number of software applications they create and operate to serve an organization’s various business units.
Software is increasingly becoming a competitive advantage for companies. Better and better tools are enabling business experts to open up new sources of revenue, or to optimize business functions in ways that lead to rapid innovation.
At the heart of this movement is the cloud. When we talk about the cloud, we are talking about a very specific set of technologies that enable developers and operators to take advantage of web services that exist to provision and manage virtualized computing infrastructure.
Companies are starting to move out of the data center and into public clouds. One such company is the popular subscription-based streaming media company Netflix.
Netflix’s Story
Today, Netflix is one of the world’s largest on-demand streaming media services, operating its online services in the cloud. Netflix was founded in 1997 in Scotts Valley, California, by Reed Hastings and Marc Randolph. Originally, Netflix provided an online DVD rental service that allowed customers to pay a flat-fee subscription each month for unlimited movie rentals without late fees. Customers were shipped DVDs by mail after selecting tiles from a list and placing them in a queue, using the Netflix website.
In 2008, Netflix experienced a major database corruption that prevented the company from shipping any DVDs to its customers. At the time, Netflix was just starting to deploy its streaming video services to customers. The streaming team at Netflix realized that a similar kind of outage in streaming would be devastating to the future of its business. As a result, Netflix made a critical decision: it would move to a different way of developing and operating its software, one that ensured that its services would always be available to its customers.
As a part of Netflix’s decision to prevent failures in its online services, it decided that it must move away from vertically scaled infrastructure and single points of failure. The realization was a result of the database corruption, which was a result of using a vertically scaled relational database. Netflix migrated its customer data to a distributed NoSQL database, an open source database project named Apache Cassandra. This was the beginning of the move to become a “cloud native” company, running all of its software applications as highly distributed and resilient services in the cloud. Netflix settled on increasing the robustness of its online services by adding redundancy to its applications and databases in a scale-out infrastructure model.
As a part of Netflix’s decision to move to the cloud, it would need to migrate its large application deployments to highly reliable distributed systems. It faced a major challenge: the teams at Netflix would have to re-architect their applications while moving away from an on-premise data center to a public cloud. In 2009, Netflix began its move to Amazon Web Services (AWS), and focused on three main goals: scalability, performance, and availability.
It was clear by the start of 2009 that demand was going to dramatically increase. In fact, Yury Izrailevsky, Vice President of Cloud and Platform Engineering at Netflix, said in a presentation at the AWS re:Invent conference in 2013 that it had increased by 100 times since 2009. “We would not be able to scale our services using an on-premise solution,” said Izrailevsky.
Furthermore, he stated that the benefits of scalability in the cloud became more evident when looking at its rapid global expansion. “In order to give our European customers a better low-latency experience, we launched a second cloud region in Ireland. Spinning up a new data center in a different territory would take many months and millions of dollars. It would be a huge investment,” he said.
As Netflix began its move to hosting its applications on Amazon Web Services, employees chronicled their learnings on Netflix’s company blog. Many of Netflix’s employees were advocating a move to a new kind of architecture that focused on horizontal scalability at all layers of the software stack.
John Ciancutti, who was then the Vice President of Personalization Technologies at Netflix, said on the company’s blog in late 2010 that “cloud environments are ideal for horizontally scaling architectures. We don’t have to guess months ahead what our hardware, storage, and networking needs are going to be. We can programmatically access more of these resources from shared pools within Amazon Web Services almost instantly.”
What Ciancutti meant by being able to “programmatically access” resources was that developers and operators could programmatically access certain management APIs that are exposed by Amazon Web Services in order to give customers a controller for provisioning their virtualized computing infrastructure. RESTful APIs gave developers a way to build applications that manage and provision virtual infrastructure for their applications.
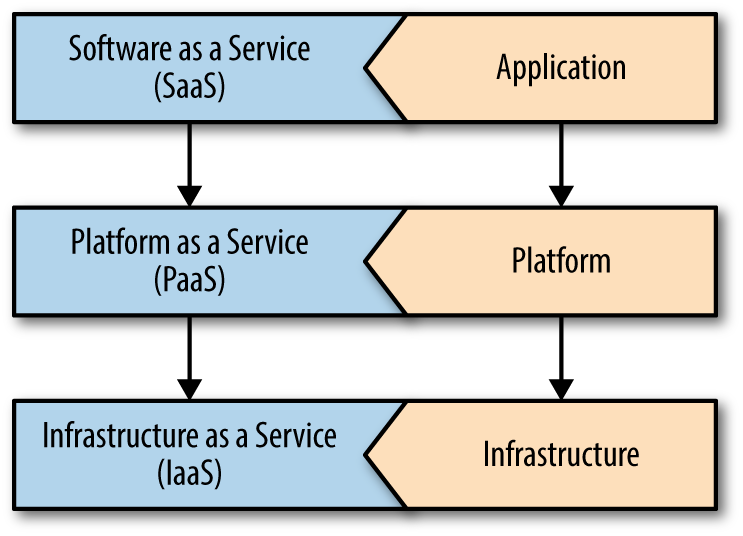
The layer cake in Figure 1-1 characterizes different cloud options characterized by different levels of abstraction.
Note
Providing management services to control virtualized computing infrastructure is one of the primary concepts of cloud computing, called Infrastructure as a Service, commonly referred to as IaaS.
Ciancutti admitted in the same blog post that Netflix was not very good at predicting customer growth or device engagement. This is a central theme behind cloud native companies. Cloud native is a mindset that admits to not being able to reliably predict when and where capacity will be needed.
In Yury Izrailevsky’s 2013 re:Invent presentation, he said that “in the cloud, we can spin up capacity in just a few days as traffic eventually increases. We could go with a tiny footprint in the beginning and gradually spin it up as our traffic increases.”
He went on to say, “As we become a global company, we have the benefit of relying on multiple Amazon Web Services regions throughout the world to give our customers a great interactive experience no matter where they are.”
The economies of scale that benefited AWS international expansion also benefited Netflix. With AWS expanding availability zones to regions outside the United States, Netflix expanded its services globally using only the management APIs provided by AWS.
Izrailevsky quoted a general argument of cloud adoption by enterprise IT: “Sure, the cloud is great, but it’s too expensive for us.” His response to this argument was that “as a result of Netflix’s move to the cloud, the cost of operations has decreased by 87%. We’re paying one-eighth of what we used to pay in the data center.”
Izrailevsky explained further why the cloud provided such large cost savings to Netflix: “It’s really helpful to be able to grow without worrying about capacity buffers. We can scale to demand as we grow.”
Microservices
We touch on microservices many times throughout this book. While this book is not exclusively about microservices, you often find that cloud native applications and microservices go hand in hand. One of the main ideas behind building microservices is the ability to have feature teams organize themselves and applications around specific business capabilities. This approach is not particularly novel by any means. Creating a system from small distributed components that work well together—and are split up in such a way as to minimize the resistance of delivering individual features into production—has been possible for decades. So, why now? Why is this kind of architecture just now becoming popular? Could it have something to do with the cloud?
Building software has always been hard. The difference between making sense and making do is often the result of someone else depriving you of your own poor choices. Technical decisions made yesterday will hamper your ability to make the right decisions for an architecture tomorrow. Now, it’s true that we all want a clean slate—tabula rasa—and microservices give us a way to take poor decisions of yesterday and decompose them into new—and hopefully better—choices for tomorrow.
It’s easy to comprehend a small thing—but much harder to comprehend the impact of its absence. If we scrutinize a well-designed monolithic application, we will see similar drives toward modularity, simplicity, and loose-coupling as we see in today’s microservice architectures. One of the main differences, of course, is history. It isn’t hard to understand how the layers of choices transformed a well-designed thing into a big horrific ball of mud. If one person made a poor choice in one small replaceable unit of an architecture, that choice can be more easily decomposed over time. But if the same person were to work on many separate modules of a well-designed monolith, the additional history may infect everyone else’s ability to make desirable choices later on. So we end up having to compromise—we are forced into making just slightly better decisions on top of a smattering of choices that we never had a chance to make ourselves.
Software that is meant for change becomes a living thing—always transformed by history—and never immune to the shifting winds of survival. Because of this, we have to build with change in mind. We have to embrace change while resisting the urge to future-proof an architecture. After all, future-proofing is just a grand design dressed up as agile development. No matter how clever we are in a concerted up-front effort to design the perfect system, we cannot reliably predict how its function will change in the future—because very often it will not be up to us. The market tends to decide a product’s fate. Because of this, we can only design with today in mind.
Microservices are not much more than an idea today. The patterns and practices of microservices are in a fluid state—still fluctuating while we patiently await a stable definition. Their embrace in a wider range of industry verticals is—for better or worse—still pending a final verdict.
There are two primary forces influencing the rapidity of architectural change: microservices and the cloud. The cloud has drastically driven down the cost and effort required to manage infrastructure. Today we are able to use self-service tools to provision infrastructure for our applications on-demand. From this, new, innovative tooling has begun to rapidly materialize—continually causing us to rethink and reshape our prior conventions. What was true yesterday about building software may not be true today—and in most cases, the truth is nebulous. We now find ourselves needing to make hard decisions on a foundation of mercurial assumptions: that our servers are physical. That our virtual machines are permanent. That our containers are stateless. Our assumptions surrounding the infrastructure layer are under a constant barrage of attack from an endless selection of new choices.
Splitting the Monolith
Netflix cites two major benefits of moving to a distributed systems architecture in the cloud from a monolith: agility and reliability.
Netflix’s architecture before going cloud native comprised a single monolithic Java Virtual Machine (JVM) application. While there were multiple advantages of having one large application deployment, the major drawback was that development teams were slowed down, due to needing to coordinate their changes.
When building and operating software, increased centralization decreases the risk of a failure at an increased cost of needing to coordinate. Coordination takes time. The more centralized a software architecture is, the more time it will take to coordinate changes to any one piece of it.
Monoliths also tend not to be very reliable. When components share resources on the same virtual machine, a failure in one component can spread to others, causing downtime for users. The risk of making a breaking change in a monolith increases with the amount of effort by teams needing to coordinate their changes. The more changes that occur during a single release cycle, the greater the risk of a breaking change that will cause downtime. By splitting up a monolith into smaller, more singularly focused services, deployments can be made with smaller batch sizes on a team’s independent release cycle.
Netflix not only needed to transform the way it builds and operates its software, it needed to transform the culture of its organization. Netflix moved to a new operational model called DevOps. In this new operational model, each team became a product group, moving away from the traditional project group structure. In a product group, teams were composed vertically, embedding operations and product management into each team. Product teams would have everything they needed to build and operate their software.
Netflix OSS
As Netflix transitioned to become a cloud native company, it also started to participate actively in open source. In late 2010, Kevin McEntee, then the Vice President of Systems & Ecommerce Engineering, announced in a blog post the company’s future role in open source.
McEntee stated that “the great thing about a good open source project that solves a shared challenge is that it develops its own momentum and it is sustained for a long time by a virtuous cycle of continuous improvement.”
In the years that followed this announcement, Netflix open sourced more than 50 of its internal projects, each of which would become a part of the Netflix OSS brand.
Key employees at Netflix would later clarify the company’s aspirations to open source many of its internal tools. In July 2012, Ruslan Meshenberg, Netflix’s Director of Cloud Platform Engineering, published a post on the company’s technology blog. The blog post, “Open Source at Netflix,” explained why Netflix was taking such a bold move to open source so much of its internal tooling.
Meshenberg wrote in the blog post, on the reasoning behind its open source aspirations, that “Netflix was an early cloud adopter, moving all of our streaming services to run on top of AWS infrastructure. We paid the pioneer tax—by encountering and working through many issues, corner cases, and limitations.”
The cultural motivations at Netflix to contribute back to the open source community and technology ecosystem are seen to be strongly tied to the principles behind the microeconomics concept known as Economies of Scale. “We’ve captured the patterns that work in our platform components and automation tools,” Meshenberg continues. “We benefit from the scale effects of other AWS users adopting similar patterns, and will continue working with the community to develop the ecosystem.”
In the advent of what has been referred to as the era of the cloud, we have seen that its pioneers are not technology companies such as IBM or Microsoft, but rather companies that were born on the back of the internet. Netflix and Amazon are both businesses that started in the late ’90s as dot-com companies. Both companies started out by offering online services that aimed to compete with their brick-and-mortar counterparts.
Both Netflix and Amazon have in time surpassed the valuation of their brick-and-mortar counterparts. As Amazon entered the cloud computing market, it did so by turning its collective experience and internal tooling into a set of services. Netflix then did the same on the back of Amazon’s services. Along the way, Netflix open sourced both its experiences and tooling, transforming into a cloud native company built on virtualized infrastructure services provided by AWS by Amazon. This is how the economies of scale are powering forward a revolution in the cloud computing industry.
In early 2015, on reports of Netflix’s first quarterly earnings, the company was reported to be valued at $32.9 billion. As a result of this new valuation for Netflix, the company’s value surpassed the value of the CBS network for the first time.
Cloud Native Java
Netflix has provided the software industry with a wealth of knowledge as a result of its move to become a cloud native company. This book will take Netflix’s lessons and open source projects and apply them as a set of patterns with two central themes:
Building resilient distributed systems using Spring and Netflix OSS
Using continuous delivery to operate cloud native applications with Cloud Foundry
The first stop on our journey will be to understand a set of terms and concepts that we will use throughout this book to describe building and operating cloud native applications.
The Twelve Factors
The twelve-factor methodology is a popular set of application development principles compiled by the creators of the Heroku cloud platform. The Twelve-Factor App is a website that was originally created by Adam Wiggins, a co-founder of Heroku, as a manifesto that describes SaaS applications designed to take advantage of the common practices of modern cloud platforms.
On the website, the methodology starts out by describing a set of core foundational ideas for building applications.
Earlier in the chapter we talked about the promises that platforms make to users who are building applications. In Table 1-1, we have a set of ideas that explicitly state the value proposition of building applications that follow the twelve-factor methodology. These ideas break down further into a set of constraints—the 12 individual factors that distill these core ideas into a collection of opinions for how applications should be built.
| Use declarative formats for setup automation, to minimize time and cost for new developers joining the project |
| Have a clean contract with the underlying operating system, offering maximum portability between execution environments |
| Are suitable for deployment on modern cloud platforms, obviating the need for servers and systems administration |
| Minimize divergence between development and production, enabling continuous deployment for maximum agility |
| And can scale up without significant changes to tooling, architecture, or development practices |
The 12 factors listed in Table 1-2 describe constraints that help build applications that take advantage of the ideas in Table 1-1. The 12 factors are a basic set of constraints that can be used to build cloud native applications. Since the factors cover a wide range of concerns that are common practices in all modern cloud platforms, building twelve-factor apps is a common starting point in cloud native application development.
| Codebase | One codebase tracked in revision control, many deploys |
| Dependencies | Explicitly declare and isolate dependencies |
| Config | Store config in the environment |
| Backing services | Treat backing services as attached resources |
| Build, release, run | Strictly separate build and run stages |
| Processes | Execute the app as one or more stateless processes |
| Port binding | Export services via port binding |
| Concurrency | Scale out via the process model |
| Disposability | Maximize robustness with fast startup and graceful shutdown |
| Dev/prod parity | Keep development, staging, and production as similar as possible |
| Logs | Treat logs as event streams |
| Admin processes | Run admin/management tasks as one-off processes |
Outside of the twelve-factor website—which covers each of the 12 factors in detail—full books have been written that expand even more on each constraint. The twelve-factor methodology is now used in some application frameworks to help developers comply with some, or even all, of the 12 out of the box.
We’ll be using the twelve-factor methodology throughout this book to describe how certain features of Spring projects were implemented to satisfy this style of application development. For this reason, it’s important that we summarize each of the factors here.
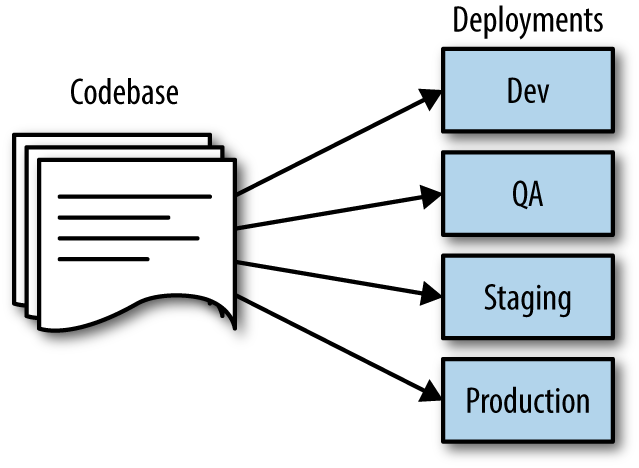
Codebase
One codebase tracked in revision control, many deploys
Source code repositories for an application should contain a single application with a manifest to its application dependencies. There should be no need to recompile or package an application for different environments. The things that are unique to each environment should live external to the code, as shown in Figure 1-2.
Dependencies
Explicitly declare and isolate dependencies
Application dependencies should be explicitly declared, and any and all dependencies should be available from an artifact repository that can be downloaded using a dependency manager, such as Apache Maven.
Twelve-factor applications never rely on the existence of implicit systemwide packages required as a dependency to run the application. All dependencies of an application are declared explicitly in a manifest file that cleanly declares the detail of each reference.
Config
Store config in the environment
Application code should be strictly separated from configuration. The configuration of the application should be driven by the environment.
Application settings such as connection strings, credentials, or hostnames of dependent web services should be stored as environment variables, making them easy to change without deploying configuration files.
Any divergence in your application from environment to environment is considered an environment configuration, and should be stored in the environment and not with the application, as demonstrated in Figure 1-3.

Backing Services
Treat backing services as attached resources
A backing service is any service that the twelve-factor application consumes as a part of its normal operation. Examples of backing services are databases, API-driven RESTful web services, an SMTP server, or an FTP server.
Backing services are considered to be resources of the application. These resources are attached to the application for the duration of operation. A deployment of a twelve-factor application should be able to swap out an embedded SQL database in a testing environment with an external MySQL database hosted in a staging environment without making changes to the application’s code.
Build, Release, Run
Strictly separate build and run stages
The twelve-factor application strictly separates the build, release, and run stages.
- Build stage
The build stage takes the source code for an application and either compiles or bundles it into a package. The package that is created is referred to as a build.
- Release stage
The release stage takes a build and combines it with its config. The release that is created for the deploy is then ready to be operated in an execution environment. Each release should have a unique identifier, either using semantic versioning or a timestamp. Each release should be added to a directory that can be used by the release management tool to rollback to a previous release.
- Run stage
The run stage, commonly referred to as the runtime, runs the application in the execution environment for a selected release.
By separating each of these stages into separate processes, it becomes impossible to change an application’s code at runtime. The only way to change the application’s code is to initiate the build stage to create a new release, or to initiate a roll back to deploy a previous release.
Processes
Execute the app as one or more stateless processes
Twelve-factor applications are created to be stateless in a share-nothing architecture. The only persistence that an application may depend on is through a backing service. Examples of a backing service that provides persistence include a database or an object store. All resources to the application are attached as a backing service at runtime. A litmus test for whether or not an application is stateless is that the application’s execution environment can be torn down and recreated without any loss of data.
Twelve-factor applications do not store state on a local filesystem in the execution environment.
Port Bindings
Export services via port binding
Twelve-factor applications are completely self-contained, which means that they do not require a web server to be injected into the execution environment at runtime in order to create a web-facing service. Each application will expose access to itself over an HTTP port that is bound to the application in the execution environment. During deployment, a routing layer will handle incoming requests from a public hostname by routing to the application’s execution environment and the bound HTTP port.
Note
Josh Long, one of the coauthors of this book, is attributed with popularizing the phrase “Make JAR not WAR” in the Java community. Josh uses this phrase to explain how newer Spring applications are able to embed a Java application server, such as Tomcat, in a build’s JAR file.
Concurrency
Scale out via the process model
Applications should be able to scale out processes or threads for parallel execution of work in an on-demand basis. JVM applications are able to handle in-process concurrency automatically using multiple threads.
Applications should distribute work concurrently, depending on the type of work that is used. Most application frameworks for the JVM today have this built in. Some scenarios that require data processing jobs that are executed as long-running tasks should utilize executors that are able to asynchronously dispatch concurrent work to an available pool of threads.
The twelve-factor application must also be able to scale out horizontally and handle requests load-balanced to multiple identical running instances of an application. By ensuring applications are designed to be stateless, it becomes possible to handle heavier workloads by scaling applications horizontally across multiple nodes.
Disposability
Maximize robustness with fast startup and graceful shutdown
The processes of a twelve-factor application are designed to be disposable. An application can be stopped at any time during process execution and gracefully handle the disposal of processes.
Processes of an application should minimize startup time as much as possible. Applications should start within seconds and begin to process incoming requests. Short startups reduce the time it takes to scale out application instances to respond to increased load.
If an application’s processes take too long to start, there may be reduced availability during a high-volume traffic spike that is capable of overloading all available healthy application instances. By decreasing the startup time of applications to just seconds, newly scheduled instances are able to more quickly respond to unpredicted spikes in traffic without decreasing availability or performance.
Dev/Prod Parity
Keep development, staging, and production as similar as possible
The twelve-factor application should prevent divergence between development and production environments. There are three types of gaps to be mindful of.
- Time gap
Developers should expect development changes to be quickly deployed into production
- Personnel gap
Developers who make a code change are closely involved with its deployment into production, and closely monitor the behavior of an application after making changes
- Tools gap
Each environment should mirror technology and framework choices in order to limit unexpected behavior due to small inconsistencies
Logs
Treat logs as event streams
Twelve-factor apps write logs as an ordered event stream to stout. Applications should not attempt to manage the storage of their own logfiles. The collection and archival of log output for an application should instead be handled by the execution environment.
Admin Processes
Run admin/management tasks as one-off processes
It sometimes becomes the case that developers of an application need to run one-off administrative tasks. These kinds of tasks could include database migrations or running one-time scripts that have been checked in to the application’s source code repository. They are considered to be admin processes. Admin processes should be run in the execution environment of an application, with scripts checked into the repository to maintain consistency between environments.
Summary
In this chapter we’ve looked at some of the motivations that have driven organizations to embrace certain constraints and architectural shifts. We’ve tried to familiarize you with some of the good ideas, in particular the twelve-factor manifesto, that have come before.