December 2019
Intermediate to advanced
468 pages
14h 28m
English
Before focusing on the entire model, let's take a look at how the transformer attention is implemented:
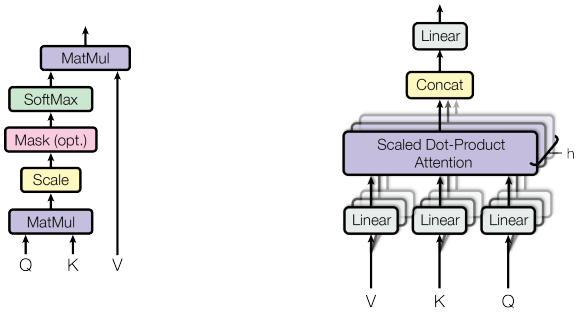
The transformer uses dot product attention (the left-hand side diagram of the preceding diagram), which follows the general attention procedure we introduced in the Seq2seq with attention section (as we have already mentioned, it is not restricted to RNN models). We can define it with the following formula:
In practice, we'll compute the attention function over a set of queries simultaneously, ...
Read now
Unlock full access






