December 2019
Intermediate to advanced
468 pages
14h 28m
English
We already discussed the training procedure that was introduced alongside matching networks in the Introduction to meta learning section. Now, let's focus on the actual model, starting with the similarity measure, which we outlined in the Metric-based meta learning section. One way to implement this is with cosine similarity (denoted with c), followed by softmax:
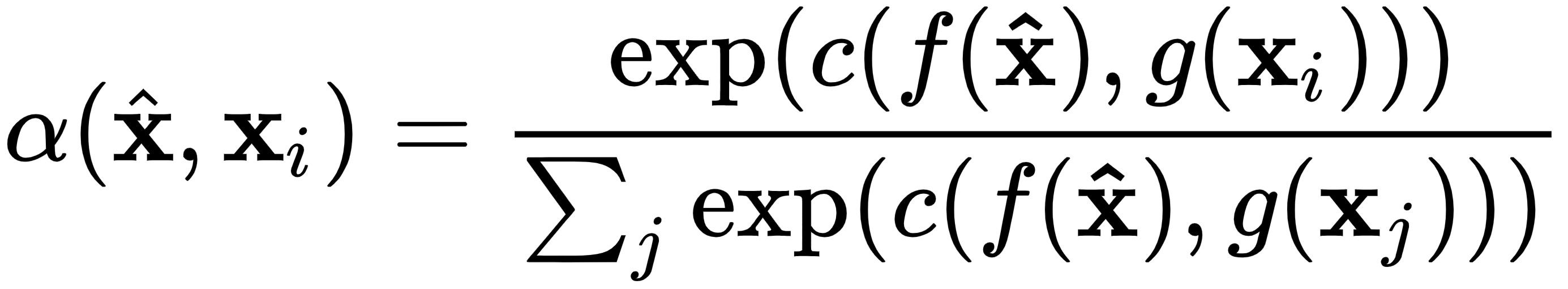
Here, f and g are encoders of the samples of the new task and the support set respectively (as we discussed, it's possible that f and g are the same function). The encoders could be CNNs for image inputs or word embeddings, such as word2vec ...
Read now
Unlock full access






