The information gain model
The information gain model is a type of machine learning concept that can be used in place of the inverse document frequency approach. The concept being used here is the probability of observing two terms together on the basis of their occurrence in an index. We use an index to evaluate the occurrence of two terms x and y and calculate the information gain for each term in the index:
P(x): Probability of a termxappearing in a listingP(x|y): Probability of the termxappearing given a termyalso appears
The information gain value of the term y can be computed as follows:
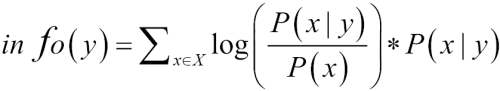
Information gain equation
This equation says that ...
Get Apache Solr Search Patterns now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

