With all machine learning algorithms, we are trying to minimize a set of cost functions which help us to select the best move. Spark uses three possible selections for maximization functions. The following figure depicts the alternatives:
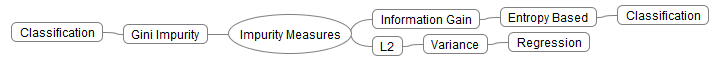
In this section, we will discuss each of the three possible alternatives:
- Information gain: Loosely speaking, this measures the level of impurity in a group based on the concept of entropy--see the Shannon information theory and then as later suggested by Quinlan in his ID3 algorithm.
The calculation of entropy is shown in the following equation:
Information gain helps us to select ...

