Chapter 16. Capturing Semantic Meanings Using Deep Learning
Word embedding is a technique that treats words as vectors whose relative similarities correlate with semantic similarity. This technique is one of the most successful applications of unsupervised learning. Natural language processing (NLP) systems traditionally encode words as strings, which are arbitrary and provide no useful information to the system regarding the relationships that may exist between different words. Word embedding is an alternative technique in NLP, whereby words or phrases from the vocabulary are mapped to vectors of real numbers in a low-dimensional space relative to the vocabulary size, and the similarities between the vectors correlate with the words’ semantic similarity.
For example, let’s take the words woman, man, queen, and king. We can get their vector representations and use basic algebraic operations to find semantic similarities. Measuring similarity between vectors is possible using measures such as cosine similarity. So, when we subtract the vector of the word man from the vector of the word woman, then its cosine distance would be close to the distance between the word queen minus the word king (see Figure 16-1):
W("woman")−W("man") ≃ W("queen")−W("king")
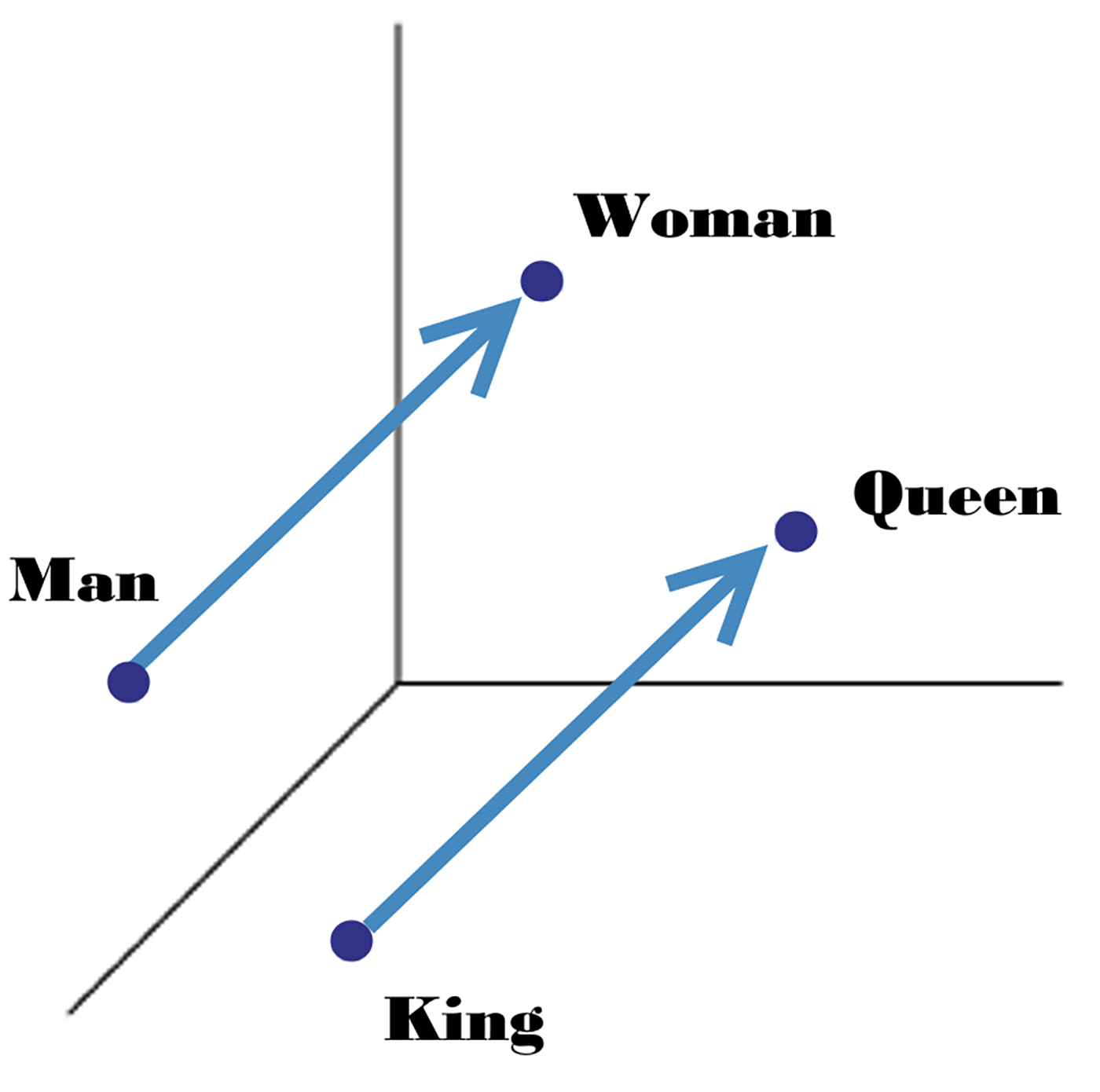
Figure 16-1. Gender vectors (image courtesy of Lior Shkiller)
Many different types of models were proposed for representing ...
Get Artificial Intelligence Now now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

