September 2024
Intermediate to advanced
366 pages
9h 58m
German
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
An diesem Punkt unserer Pipeline für maschinelles Lernen haben wir die Statistiken unserer Daten überprüft, unsere Daten in die richtigen Merkmale umgewandelt und unser Modell trainiert. Ist es jetzt nicht an der Zeit, das Modell in Produktion zu geben? Unserer Meinung nach sollten zwei weitere Schritte folgen, bevor du dein Modell in Betrieb nimmst: die gründliche Analyse der Leistung deines Modells und die Überprüfung, ob es eine Verbesserung gegenüber einem bereits in Produktion befindlichen Modell darstellt. Wir zeigen in Abbildung 7-1, wo diese Schritte in der Pipeline liegen.
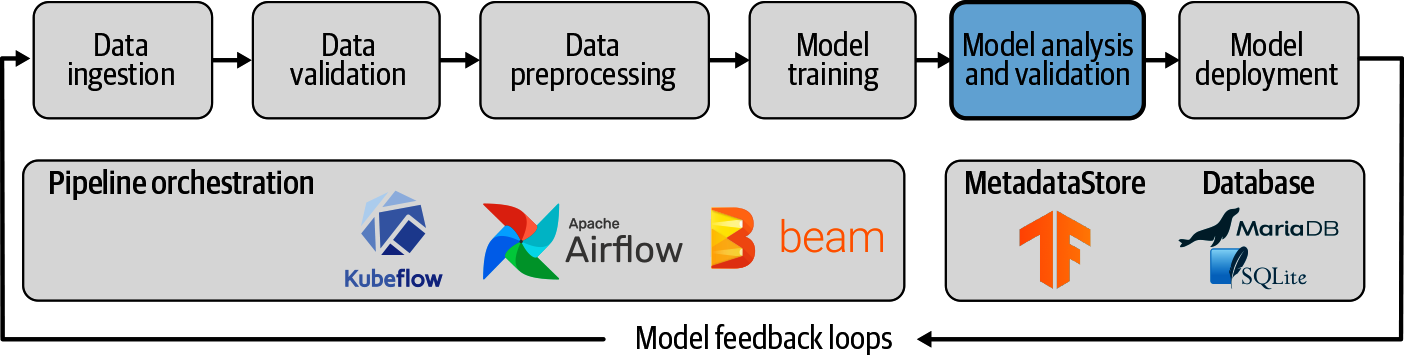
Während wir ein Modell trainieren, überwachen wir seine Leistung auf einer Auswertungsmenge und probieren verschiedene Hyperparameter aus, um die beste Leistung zu erzielen. Es ist jedoch üblich, während des Trainings nur eine Metrik zu verwenden, und das ist oft die Genauigkeit.
Wenn wir eine Pipeline für maschinelles Lernen aufbauen, versuchen wir oft, eine komplexe Geschäftsfrage zu beantworten oder ein komplexes reales System zu modellieren. Eine einzige Kennzahl reicht oft nicht aus, um uns zu sagen, ob unser Modell die Frage beantworten kann. Das gilt ...