Looking at Tags
In addition to all this ordinal and numeric data, we have a set of free-form tags that users are able enter about a person's picture. The tags range from descriptive ("freckles", "nosering") to crass ("takemetobed", "dirtypits") to friendly ("you.look.good.in.red") to advice ("cutyourhair", "avoidsun") to editorial ("awwdorable!!!!!", "EnoughUploadsNancy") to mean ("Thefatfriend") to nonsensical ("…", "plokmnjiuhbygvtfcrdxeszwaq"). In general, free-text data is more complicated to process.
The first thing to do is examine the distribution of the tags. What's the most common tag?
Load our tags > face_tags = read.delim("face_tags.tsv",sep="\t",as.is=T) then count > counts = table(face_tags$tag) and rank them. > sorted_counts = sort(counts, decreasing=T) Show the most common tags. > sorted_counts[1:20]
The following table contains the output.
cute 81333 | pretty 40954 | happy 36263 | nice 33221 | fun 30622 | young 27900 |
sweet 20362 | friendly 14895 | cool 14709 | weird 12731 | hot 12662 | gay 12409 |
Cute 12132 | funny 11508 | scary 11445 | sexy 11287 | old 10958 | goofy 10511 |
emo 10292 | shy 10207 |
What are the least common tags?
Show the least common tags. > tail(sorted_count, 20)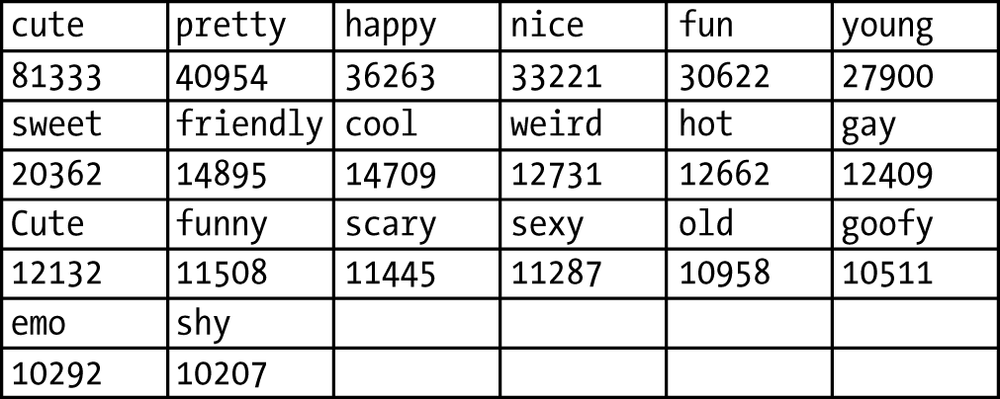
Glancing at a few of the tags raises questions about normalization. Should "cute" and "Cute" be merged into the same tag? Should punctuation be dropped entirely? Should that funny-looking full-width question mark for Asian languages be considered ...
Get Beautiful Data now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

