March 2019
Intermediate to advanced
538 pages
13h 38m
English
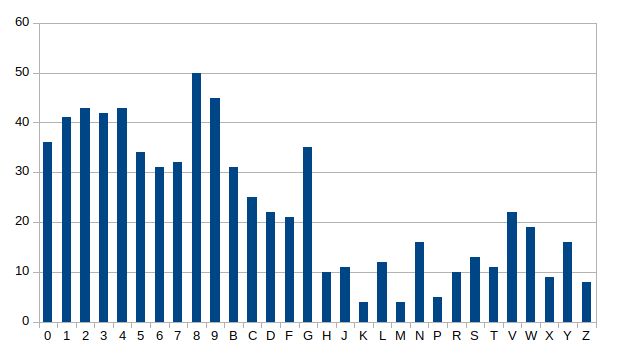
We have 30 characters and numbers, distributed along 702 images in our dataset with the following distribution. We can check that there are more than 30 images for numbers, but some letters such as K, M, and P, have fewer images samples:
In the following image, we can see a small sample of images from our dataset:
This dataset is very small for deep learning. Deep learning requires a huge amount of samples and is a common technique. In some cases, use a dataset augmentation over the original dataset. Dataset augmentation ...
Read now
Unlock full access






