Chapter 4. Integrating Event-Driven Architectures with Existing Systems
Transitioning an organization to an event-driven architecture requires the integration of existing systems into the ecosystem. Your organization may have one or more monolithic relational database applications. Point-to-point connections between various implementations are likely to exist. Perhaps there are already event-like mechanisms for transferring bulk data between systems, such as regular syncing of database dumps via an intermediary file store location. In the case that you are building an event-driven microservice architecture from the ground up and have no legacy systems, great! You can skip this section (though perhaps you should consider that EDM may not be right for your new project). However, if you have existing legacy systems that need to be supported, read on.
In any business domain, there are entities and events that are commonly required across multiple subdomains. For example, an ecommerce retailer will need to supply product information, prices, stock, and images to various bounded contexts. Perhaps payments are collected by one system but need to be validated in another, with analytics on purchase patterns performed in a third system. Making this data available in a central location as the new single source of truth allows each system to consume it as it becomes available. Migrating to event-driven microservices requires making the necessary business domain data available in the event broker, consumable as event streams. Doing so is a process known as data liberation, and involves sourcing the data from the existing systems and state stores that contain it.
Data produced to an event stream can be accessed by any system, event-driven or otherwise. While event-driven applications can use streaming frameworks and native consumers to read the events, legacy applications may not be able to access them as easily due to a variety of factors, such as technology and performance limitations. In this case, you may need to sink the events from an event stream into an existing state store.
There are a number of patterns and frameworks for sourcing and sinking event data. For each technique, this chapter will cover why it’s necessary, how to do it, and the tradeoffs associated with different approaches. Then, we’ll review how data liberation and sinking fit in to the organization as a whole, the impacts they have, and ways to structure your efforts for success.
What Is Data Liberation?
Data liberation is the identification and publication of cross-domain data sets to their corresponding event streams and is part of a migration strategy for event-driven architectures. Cross-domain data sets include any data stored in one data store that is required by other external systems. Point-to-point dependencies between existing services, and data stores often highlight the cross-domain data that should be liberated, as shown in Figure 4-1, where three dependent services are querying the legacy system directly.
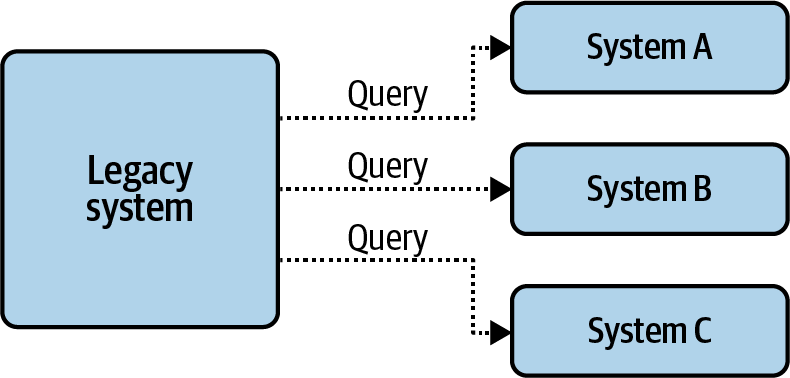
Figure 4-1. Point-to-point dependencies, accessing data directly from the underlying service
Data liberation enforces two primary features of event-driven architecture: the single source of truth and the elimination of direct coupling between systems. The liberated event streams allow new event-driven microservices to be built as consumers, with existing systems migrated in due time. Reactive event-driven frameworks and services may now be used to consume and process data, and downstream consumers are no longer required to directly couple on the source data system.
By serving as a single source of truth, these streams also standardize the way in which systems across the organization access data. Systems no longer need to couple directly to the underlying data stores and applications, but instead can couple solely on the data contracts of event streams. The post-liberation workflow is shown in Figure 4-2.
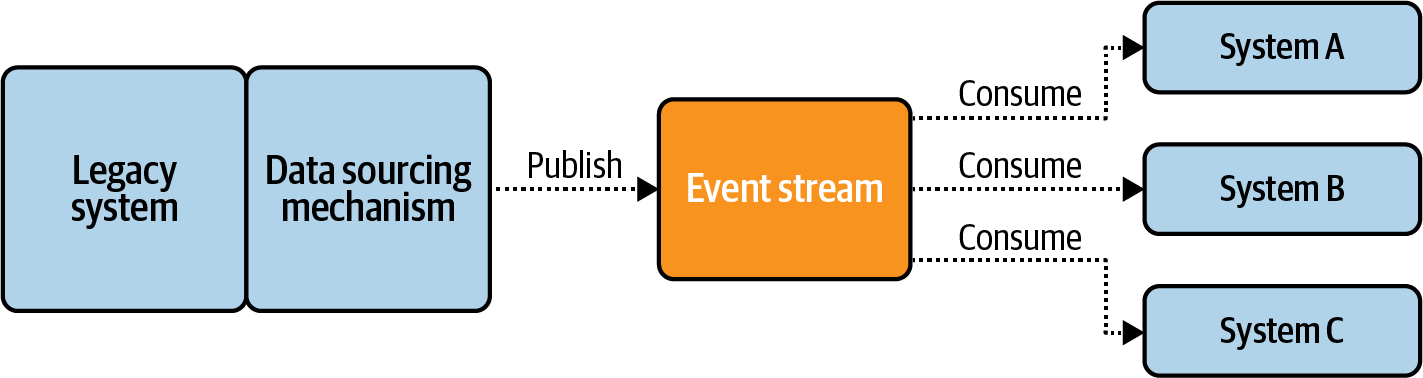
Figure 4-2. Post-data-liberation workflow
Compromises for Data Liberation
A data set and its liberated event stream must be kept fully in sync, although this requirement is limited to eventual consistency due to the latency of event propagation. A stream of liberated events must materialize back into an exact replica of the source table, and this property is used extensively for event-driven microservices (as covered in Chapter 7). In contrast, legacy systems do not rebuild their data sets from any event streams, but instead typically have their own backup and restore mechanisms and read absolutely nothing back from the liberated event stream.
In the perfect world, all state would be created, managed, maintained, and restored from the single source of truth of the event streams. Any shared state should be published to the event broker first and materialized back to any services that need to materialize the state, including the service that produced the data in the first place, as shown in Figure 4-3.
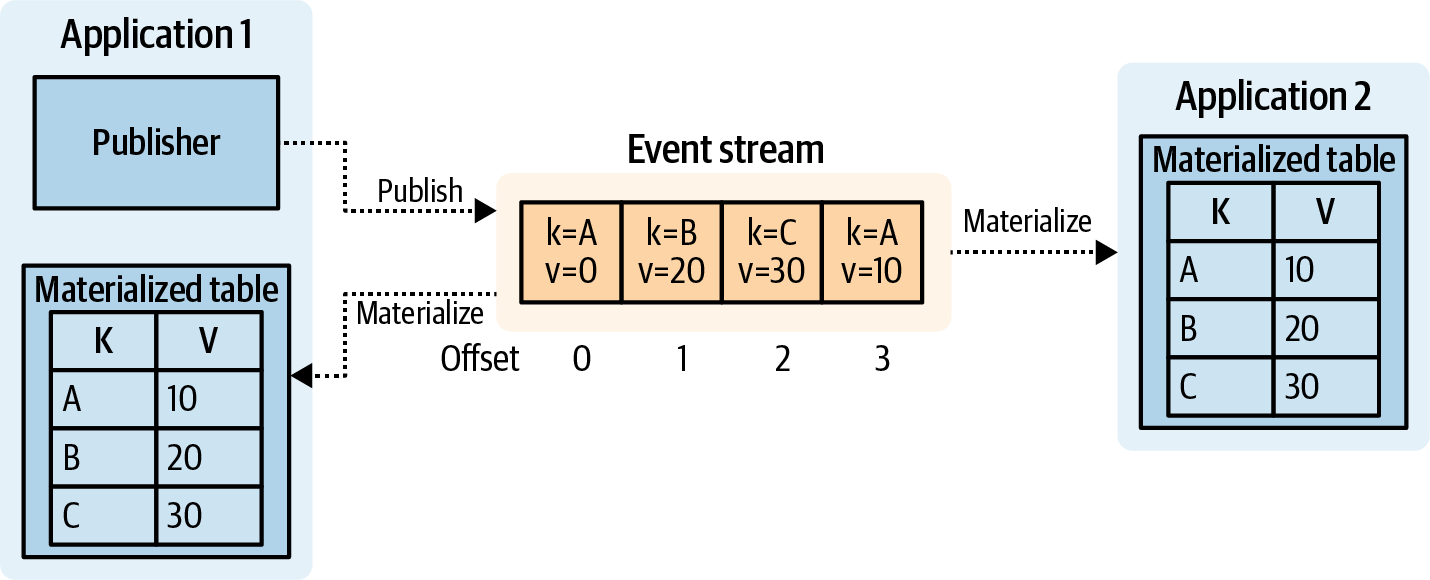
Figure 4-3. Publish to stream before materializing
While the ideal of maintaining state in the event broker is accessible for new microservices and refactored legacy applications, it is not necessarily available or practical for all applications. This is particularly true for services that are unlikely to ever be refactored or changed beyond initial integration with change-data capture mechanisms. Legacy systems can be both extremely important to the organization and prohibitively difficult to refactor, with the worst offenders being considered a big ball of mud. Despite the complexity of a system, their internal data will still need to be accessed by other new systems. While refactoring may absolutely be desirable, there are a number of issues that prevent this from happening in reality:
- Limited developer support
-
Many legacy systems have minimal developer support and require low-effort solutions to generate liberated data.
- Expense of refactoring
-
Reworking the preexisting application workflows into a mix of asynchronous event-driven and synchronous MVC (Model-View-Controller) web application logic may be prohibitively expensive, especially for complex legacy monoliths.
- Legacy support risk
-
Changes made to legacy systems may have unintended consequences, especially when the system’s responsibilities are unclear due to technical debt and unidentified point-to-point connections with other systems.
There is an opportunity for compromise here. You can use data liberation patterns to extract the data out of the data store and create the necessary event streams. This is a form of unidirectional event-driven architecture, as the legacy system will not be reading back from the liberated event stream, as shown in Figure 4-3. Instead, the fundamental goal is to keep the internal data set synchronized with the external event stream through strictly controlled publishing of event data. The event stream will be eventually consistent with the internal data set of the legacy application, as shown in Figure 4-4.
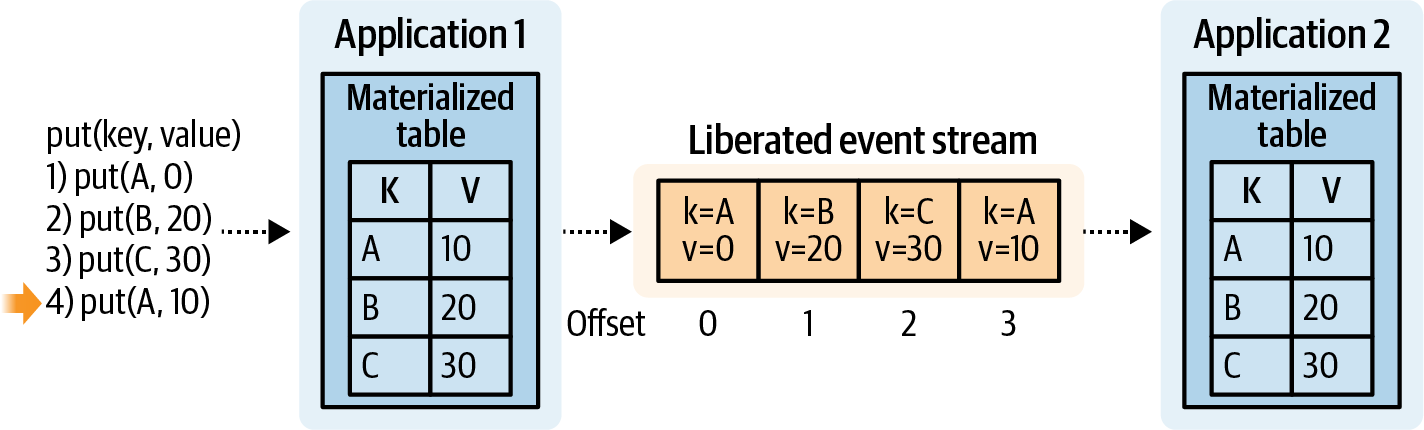
Figure 4-4. Liberating and materializing state between two services
Converting Liberated Data to Events
Liberated data, much like any other event, is subject to the same recommendations of schematization that were introduced in Chapter 3. One of the properties of a well-defined event stream is that there is an explicitly defined and evolutionarily compatible schema for the events it contains. You should ensure that consumers have basic data quality guarantees as part of the data contract defined by the schema. Changes to the schema can only be made according to evolutionary rules.
Tip
Use the same standard format for both liberated event data and native event data across your organization.
By definition, the data that is most relevant and used across the business is the data that is most necessary to liberate. Changes made to the data definitions of the source, such as creating new fields, altering existing ones, or dropping others, can result in dynamically changing data being propagated downstream to consumers. Failing to use an explicitly defined schema for liberated data will force downstream consumers to resolve any incompatibilities. This is extremely problematic for the provision of the single source of truth, as downstream consumers should not be attempting to parse or interpret data on their own. It is extremely important to provide a reliable and up-to-date schema of the produced data and to carefully consider the evolution of the data over time.
Data Liberation Patterns
There are three main data liberation patterns that you can use to extract data from the underlying data store. Since liberated data is meant to form the new single source of truth, it follows that it must contain the entire set of data from the data store. Additionally, this data must be kept up to date with new insertions, updates, and deletes.
- Query-based
-
You extract data by querying the underlying state store. This can be performed on any data store.
- Log-based
-
You extract data by following the append-only log for changes to the underlying data structures. This option is available only for select data stores that maintain a log of the modifications made to the data.
- Table-based
-
In this pattern, you first push data to a table used as an output queue. Another thread or separate process queries the table, emits the data to the relevant event stream, and then deletes the associated entries. This method requires that the data store support both transactions and an output queue mechanism, usually a standalone table configured for use as a queue.
While each pattern is unique, there is one commonality among the three. Each should produce its events in sorted timestamp order, using the source record’s most recent updated_at time in its output event record header. This will generate an event stream timestamped according to the event’s occurrence, not the time that the producer published the event. This is particularly important for data liberation, as it accurately represents when events actually happened in the workflow. Timestamp-based interleaving of events is discussed further in Chapter 6.
Data Liberation Frameworks
One method of liberating data involves the usage of a dedicated, centralized framework to extract data into event streams. Examples of centralized frameworks for capturing event streams include Kafka Connect (exclusively for the Kafka platform), Apache Gobblin, and Apache NiFi. Each framework allows you to execute a query against the underlying data set with the results piped through to your output event streams. Each option is also scalable, such that you can add further instances to increase the capacity for executing change-data capture (CDC) jobs. They support various levels of integration with the schema registry offered by Confluent (Apache Kafka), but customization can certainly be performed to support other schema registries. See “Schema Registry” for more information.
Not all data liberation processes require a dedicated framework, and many systems are better suited to taking direct ownership of their own event stream data production. In fact, these frameworks inadvertently encourage data access anti-patterns. One of the most common anti-patterns is the exposure of internal data models to external systems, further increasing coupling instead of decreasing it, as is one of the major benefits of event-driven architectures. This will be covered further in the remainder of the chapter.
Liberating Data by Query
Query-based data liberation involves querying the data store and emitting selected results to an associated event stream. A client is used to request the specific data set from the data store using the appropriate API, SQL, or SQL-like language. A data set must be bulk-queried to provide the history of events. Periodic updates then follow, ensuring that changes are produced to the output event stream.
There are several types of queries used in this pattern.
Bulk Loading
Bulk loading queries and loads all of the data from the data set. Bulks loads are performed when the entire table needs to be loaded at each polling interval, as well as prior to ongoing incremental updates.
Bulk loading can be expensive, as it requires obtaining the entire data set from the data store. For smaller data sets this tends not to be a problem, but large data sets, especially those with millions or billions of records, may be difficult to obtain. For querying and processing very large data sets I recommend you research best practices for your particular data store, since these can vary significantly with implementation.
Incremental Timestamp Loading
With incremental timestamp loading, you query and load all data since the highest timestamp of the previous query’s results. This approach uses an updated-at column or field in the data set that keeps track of the time when the record was last modified. During each incremental update, only records with updated-at timestamps later than the last processed time are queried.
Autoincrementing ID Loading
Autoincrementing ID loading involves querying and loading all data larger than the last value of the ID. This requires a strictly ordered autoincrementing Integer or Long field. During each incremental update, only records with an ID larger than the last processed ID are queried. This approach is often used for querying tables with immutable records, such as when using the outbox tables (see “Liberating Data Using Change-Data Capture Logs”).
Custom Querying
A custom query is limited only by the client querying language. This approach is often used when the client requires only a certain subset of data from a larger data set, or when joining and denormalizing data from multiple tables to avoid over-exposure of the internal data model. For instance, a user could filter business partner data according to a specific field, where each partner’s data is sent to its own event stream.
Incremental Updating
The first step of any incremental update is to ensure that the necessary timestamp or autoincrementing ID is available in the records of your data set. There must be a field that the query can use to filter out records it has already processed from those it has yet to process. Data sets that lack these fields will need to have them added, and the data store will need to be configured to populate the necessary updated_at
timestamp or the autoincrementing ID field. If the fields cannot be added to the data set, then incremental updates will not be possible with a query-based pattern.
The second step is to determine the frequency of polling and the latency of the updates. Higher-frequency updates provide lower latency for data updates downstream, though this comes at the expense of a larger total load on the data store. It’s also important to consider whether the interval between requests is sufficient to finish loading all of the data. Beginning a new query while the old one is still loading can lead to race conditions, where older data overwrites newer data in the output event streams.
Once the incremental update field has been selected and the frequency of updates determined, the final step is to perform a single bulk load before enabling incremental updates. This bulk load must query and produce all of the existing data in the data set prior to further incremental updates.
Benefits of Query-Based Updating
Query-based updating has a number of advantages, including:
- Customizability
-
Any data store can be queried, and the entire range of client options for querying is available.
- Independent polling periods
-
Specific queries can be executed more frequently to meet tighter SLAs (service-level agreements), while other more expensive queries can be executed less frequently to save resources.
- Isolation of internal data models
-
Relational databases can provide isolation from the internal data model by using views or materialized views of the underlying data. This technique can be used to hide domain model information that should not be exposed outside of the data store.
Caution
Remember that the liberated data will be the single source of truth. Consider whether any concealed or omitted data should instead be liberated, or if the source data model needs to be refactored. This often occurs during data liberation from legacy systems, where business data and entity data have become intertwined over time.
Drawbacks of Query-Based Updating
There are some downsides to query-based updating as well:
- Required
updated-attimestamp -
The underlying table or namespace of events to query must have a column containing their
updated-attimestamp. This is essential for tracking the last update time of the data and for making incremental updates. - Untraceable hard deletions
-
Hard deletions will not show up in the query results, so tracking deletions is limited to flag-based soft deletions, such as a boolean
is_deletedcolumn. - Brittle dependency between data set schema and output event schema
-
Data set schema changes may occur that are incompatible with downstream event format schema rules. Breakages are increasingly likely if the liberation mechanism is separate from the code base of the data store application, which is usually the case for query-based systems.
- Intermittent capture
-
Data is synced only at polling intervals, and so a series of individual changes to the same record may only show up as a single event.
- Production resource consumption
-
Queries use the underlying system resources to execute, which can cause unacceptable delays on a production system. This issue can be mitigated by the use of a read-only replica, but additional financial costs and system complexity will apply.
- Variable query performance due to data changes
-
The quantity of data queried and returned varies depending on changes made to the underlying data. In the worst-case scenario, the entire body of data is changed each time. This can result in race conditions when a query is not finished before the next one starts.
Liberating Data Using Change-Data Capture Logs
Another pattern for liberating data is using the data store’s underlying change-data capture logs (binary logs in MySQL, write-ahead logs for PostgreSQL) as the source of information. This is an append-only data logging structure that details everything that has happened to the tracked data sets over time. These changes include the creation, deletion, and updating of individual records, as well as the creation, deletion, and altering of the individual data sets and their schemas.
The technology options for change-data capture are narrower than those for query-based capturing. Not all data stores implement an immutable logging of changes, and of those that do, not all of them have off-the-shelf connectors available for extracting the data. This approach is mostly applicable to select relational databases, such as MySQL and PostgreSQL, though any data store with a set of comprehensive changelogs is a suitable candidate. Many other modern data stores expose event APIs that act as a proxy for a physical write-ahead log. For example, MongoDB provides a Change Streams interface, whereas Couchbase provides replication access via its internal replication protocol.
The data store log is unlikely to contain all changes since the beginning of time, as it can be a huge amount of data and is usually not necessary to retain. You will need to take a snapshot of the existing data prior to starting the change-data capture process from the data store’s log. This snapshot usually involves a large, performance-impacting query on the table and is commonly referred to as bootstrapping. You must ensure that there is overlap between the records in the bootstrapped query results and the records in the log, such that you do not accidentally miss any records.
You must checkpoint progress when capturing events from the changelogs, though depending on the tooling you use, this may already be built in. In the event that the change-data capture mechanism fails, the checkpoint is used to restore the last stored changelog index. This approach can only provide at-least-once production of records, which tends to be suitable for the entity-based nature of data liberation. The production of an additional record is inconsequential since updating entity data is idempotent.
There are a number of options available for sourcing data from changelogs. Debezium is one of the most popular choices for relational databases, as it supports the most common ones. Debezium can produce records to both Apache Kafka and Apache Pulsar with its existing implementations. Support for additional brokers is certainly possible, though it may require some in-house development work. Maxwell is another example of a binary log reader option, though it is currently limited in support to just MySQL databases and can produce data only to Apache Kafka.

Figure 4-5. The end-to-end workflow of a Debezium capturing data from a MySQL database’s binary log, and writing it to event streams in Kafka
Figure 4-5 shows a MySQL database emitting its binary changelog. A Kafka Connect service, running a Debezium connector, is consuming the raw binary log. Debezium parses the data and converts it into discrete events. Next, an event router emits each event to a specific event stream in Kafka, depending on the source table of that event. Downstream consumers are now able to access the database content by consuming the relevant event streams from Kafka.
Benefits of Using Data Store Logs
Some benefits of using data store logs include:
- Delete tracking
-
Binary logs contain hard record deletions. These can be converted into delete events without the need for soft deletes as in query-based updates.
- Minimal effect on data store performance
-
For data stores that use write-ahead and binary logs, change-data capture can be performed without any impact to the data store’s performance. For those that use change tables, such as in SQL Server, the impact is related to the volume of data.
- Low-latency updates
-
Updates can be propagated as soon as the event is written to the binary and write-ahead logs. This results in very low latency when compared to other data liberation patterns.
Drawbacks of Using Data Base Logs
The following are some of the downsides to using data base logs:
- Exposure of internal data models
-
The internal data model is completely exposed in the changelogs. Isolation of the underlying data model must be carefully and selectively managed, unlike query-based updating, where views can be used to provide isolation.
- Denormalization outside of the data store
-
Changelogs contain only the event data. Some CDC mechanisms can extract from materialized views, but for many others, denormalization must occur outside of the data store. This may lead to the creation of highly normalized event streams, requiring downstream microservices to handle foreign-key joins and denormalization.
- Brittle dependency between data set schema and output event schema
-
Much like the query-based data liberation process, the binary-log-based process exists outside of the data store application. Valid data store changes, such as altering a data set or redefining a field type, may be completely incompatible for the specific evolution rules of the event schema.
Liberating Data Using Outbox Tables
An outbox table contains notable changes made to the internal data of a data store, with each significant update stored as its own row. Whenever an insert, update, or delete is made to one of the data store tables marked for change-data capture, a corresponding record can be published to the outbox table. Each table under change-data capture can have its own outbox table, or a single outbox can be used for all changes (more on this shortly).
Both the internal table updates and the outbox updates must be bundled into a single transaction, such that each occurs only if the entire transaction succeeds. A failure to do may eventually result in divergence with the event stream as the single source of truth, which can be difficult to detect and repair. This pattern is a more invasive approach to change-data capture as it requires modification to either the data store or the application layer, both of which require the involvement of the data store developers. The outbox table pattern leverages the durability of the data store to provide a write-ahead log for events awaiting to be published to external event streams.
The records in outbox tables must have a strict ordering identifier, for the same primary key may be updated many times in short order. Alternatively, you could overwrite the previous update for that primary key, though this requires finding the previous entry first and introduces additional performance overhead. It also means that the overwritten record will not be emitted downstream.
An autoincrementing ID, assigned at insertion time, is best used to determine the order in which the events are to be published. A created_at timestamp column should also be maintained, as it reflects the event time that the record was created in the data store and can be used instead of the wall-clock time during publishing to the event stream. This will allow accurate interleaving by the event scheduler as discussed in Chapter 6.
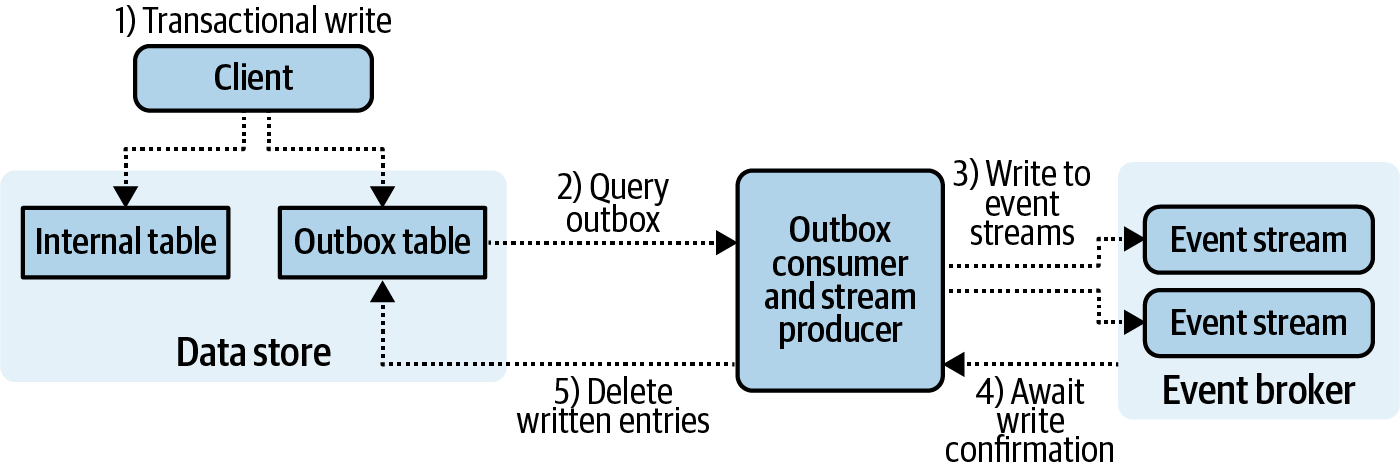
Figure 4-6. The end-to-end workflow of an outbox table CDC solution
Figure 4-6 shows the end-to-end workflow. Updates to internal tables made by the data store client are wrapped in a transaction with an update to the outbox table, such that any failures ensures data remains consistent between the two. Meanwhile, a separate application thread or process is used to continually poll the outboxes and produce the data to the corresponding event streams. Once successfully produced, the corresponding records in the outbox are deleted. In the case of any failure, be it the data store, the consumer/producer, or the event broker itself, outbox records will still be retained without risk of loss. This pattern provides at-least-once delivery guarantees.
Performance Considerations
The inclusion of outbox tables introduces additional load on the data store and its request-handling applications. For small data stores with minimal load, the overhead may go completely unnoticed. Alternately, it may be quite expensive with very large data stores, particularly those with significant load and many tables under capture. The cost of this approach should be evaluated on a case-by-case basis and balanced against the costs of a reactive strategy such as parsing the change-data capture logs.
Isolating Internal Data Models
An outbox does not need to map 1:1 with an internal table. In fact, one of the major benefits of the outbox is that the data store client can isolate the internal data model from downstream consumers. The internal data model of the domain may use a number of highly normalized tables that are optimized for relational operations but are largely unsuitable for consumption by downstream consumers. Even simple domains may comprise multiple tables, which if exposed as independent streams, would require reconstruction for usage by downstream consumers. This quickly becomes extremely expensive in terms of operational overhead, as multiple downstream teams will have to reconstruct the domain model and deal with handling relational data in event streams.
Warning
Exposing the internal data model to downstream consumers is an anti-pattern. Downstream consumers should only access data formatted with public-facing data contracts as described in Chapter 3.
The data store client can instead denormalize data upon insertion time such that the outbox mirrors the intended public data contract, though this does come at the expense of additional performance and storage space. Another option is to maintain the 1:1 mapping of changes to output event streams and denormalize the streams with a downstream event processor dedicated to just this task. This is a process that I call eventification, as it converts highly normalized relational data into easy-to-consume single event updates. This mimics what the data store client could do but does it externally to the data store to reduce load. An example of this is shown in Figure 4-7, where a User is denormalized based on User, Location, and Employer.
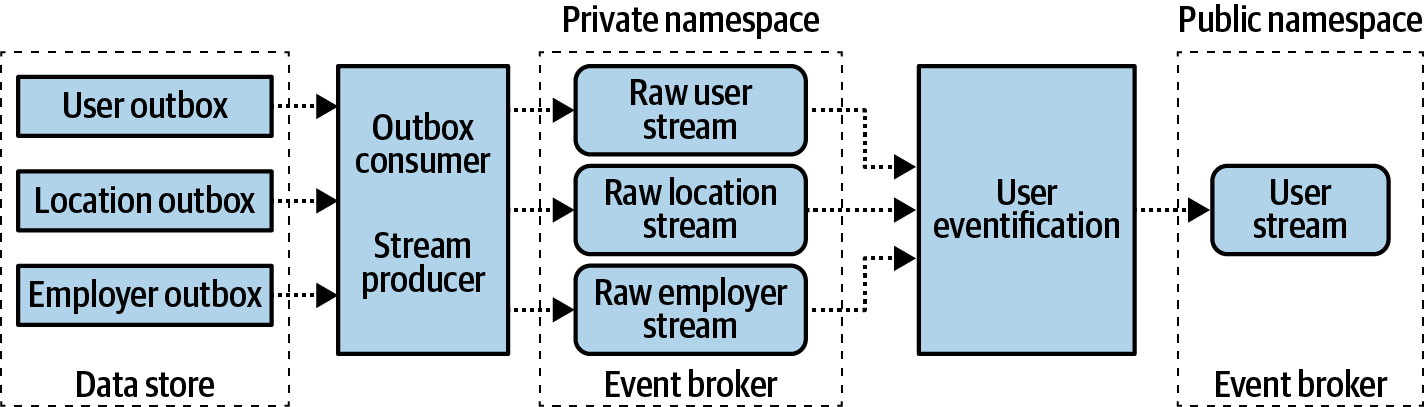
Figure 4-7. Eventification of public User events using private User, Location, and Employer event streams
In this example, the User has a foreign-key reference to the city, state/province, and country they live in, as well as a foreign-key reference to their current employer. It is reasonable that a downstream consumer of a User event may simply want everything about each user in a single event, instead of being forced to materialize each stream into a state store and use relational tooling to denormalize it. The raw, normalized events are sourced from the outboxes into their own event streams, but these streams are kept in a private namespace from the rest of the organization (covered in “Event Stream Metadata Tagging”) to protect the internal data model.
Eventification of the user is performed by denormalizing the User entity and shedding any internal data model structures. This process requires maintaining materialized tables of User, Location, and Employer, such that any updates can re-exercise the join logic and emit updates for all affected Users. The final event is emitted to the public namespace of the organization for any downstream consumer to consume.
The extent to which the internal data models are isolated from external consumers tends to become a point of contention in organizations moving toward event-driven microservices. Isolating the internal data model is essential for ensuring decoupling and independence of services and to ensure that systems need only change due to new business requirements, and not upstream internal data-model changes.
Ensuring Schema Compatibility
Schema serialization (and therefore, validation) can also be built into the capture workflow. This may be performed either before or after the event is written to the outbox table. Success means the event can be proceed in the workflow, whereas a failure may require manual intervention to determine the root cause and avoid data loss.
Serializing prior to committing the transaction to the outbox table provides the strongest guarantee of data consistency. A serialization failure will cause the transaction to fail and roll back any changes made to the internal tables, ensuring that the outbox table and internal tables stay in sync. This process is shown in Figure 4-8. A successful validation will see the event serialized and ready for event stream publishing. The main advantage of this approach is that data inconsistencies between the internal state and the output event stream are significantly reduced. The event stream data is treated as a first-class citizen, and publishing correct data is considered just as important as maintaining consistent internal state.
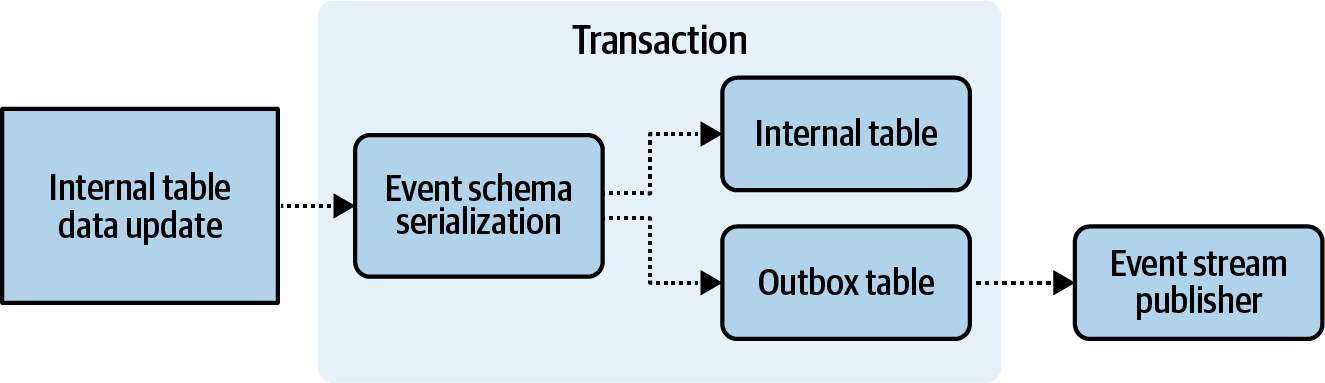
Figure 4-8. Serializing change-data before writing to outbox table
Serializing before writing to the outbox also provides you with the option of using a single outbox for all transactions. The format is simple, as the content is predominantly serialized data with the target output event stream mapping. This is shown in Figure 4-9.

Figure 4-9. A single output table with events already validated and serialized (note the output_stream entry for routing purposes)
One drawback of serializing before publishing is that performance may suffer due to the serialization overhead. This may be inconsequential for light loads but could have more significant implications for heavier loads. You will need to ensure your performance needs remain met.
Alternately, serialization can be performed after the event has been written to the outbox table, as is shown in Figure 4-8.
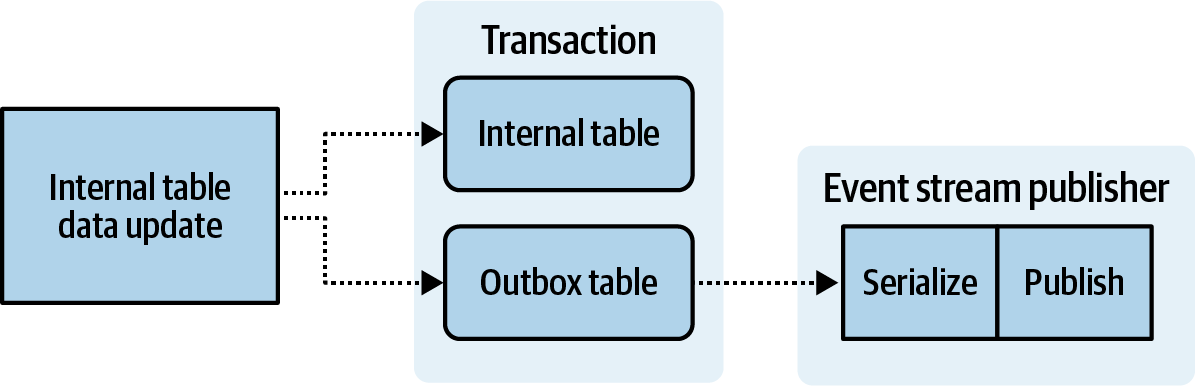
Figure 4-10. Serializing change-data after writing to outbox table, as part of the publishing process
With this strategy you typically have independent outboxes, one for each domain model, mapped to the public schema of the corresponding output event stream. The publisher process reads the unserialized event from the outbox and attempts to serialize it with the associated schema prior to producing it to the output event stream. Figure 4-11 shows an example of multiple outboxes, one for a User entity and one for an Account entity.
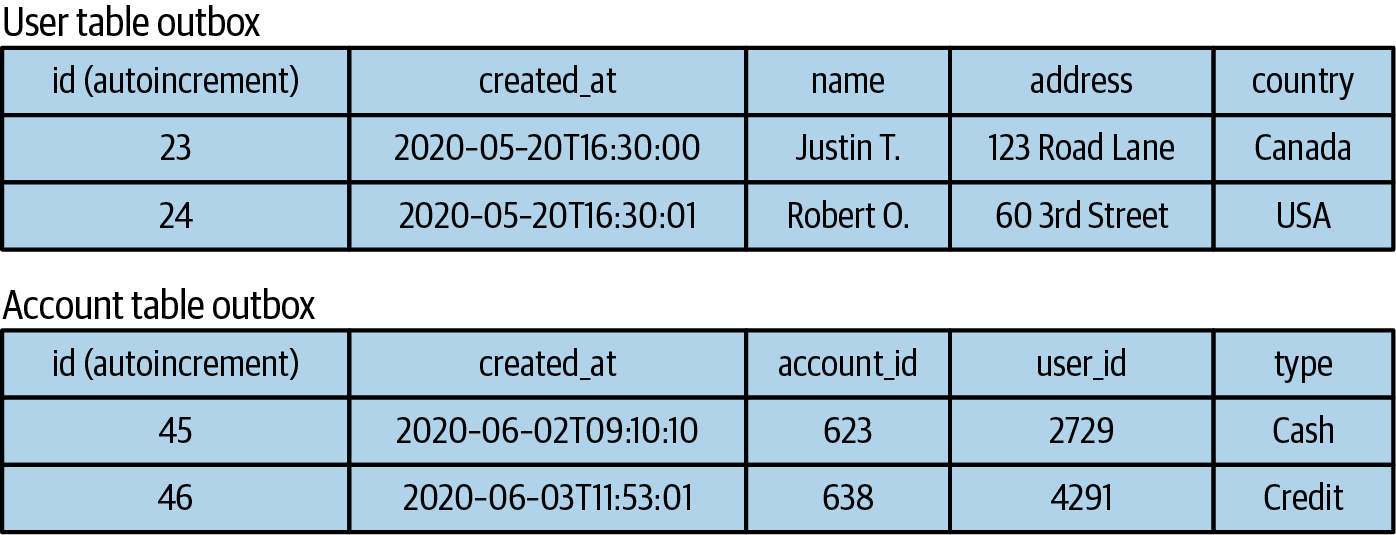
Figure 4-11. Multiple outbox tables (note that the data is not serialized, which means that it may not be compatible with the schema of the output event stream)
A failure to serialize indicates that the data of the event does not comply with its defined schema and so cannot be published. This is where the serialization-after-write option becomes more difficult to maintain, as an already completed transaction will have pushed incompatible data into the outbox table, and there is no guarantee that the transaction can be reversed.
In reality, you will typically end up with a large number of unserializable events in your outbox. Human intervention will most likely be required to try to salvage some of the data, but resolving the issue will be time-consuming and difficult and may even require downtime to prevent additional issues. This is compounded by the fact that some events may indeed be compatible and have already been published, leading to possible incorrect ordering of events in output streams.
Tip
Before-the-fact serialization provides a stronger guarantee against incompatible data than after-the-fact and prevents propagation of events that violate their data contract. The tradeoff is that this implementation will also prevent the business process from completing should serialization fail, as the transaction must be rolled back.
Validating and serializing before writing ensures that the data is being treated as a first-class citizen and offers a guarantee that events in the output event stream are eventually consistent with the data inside the source data store, while also preserving the isolation of the source’s internal data model. This is the strongest guarantee that a change-data capture solution can offer.
Benefits of event-production with outbox tables
Producing events via outbox tables allow for a number of significant advantages:
- Multilanguage support
-
This approach is supported by any client or framework that exposes transactional capabilities.
- Before-the-fact schema enforcement
-
Schemas can be validated by serialization before being inserted into the outbox table.
- Isolation of the internal data model
-
Data store application developers can select which fields to write to the outbox table, keeping internal fields isolated.
- Denormalization
-
Data can be denormalized as needed before being written to the outbox table.
Drawbacks of event production with outbox tables
Producing events via outbox tables has several disadvantages as well:
- Required application code changes
-
The application code must be changed to enable this pattern, which requires development and testing resources from the application maintainers.
- Business process performance impact
-
The performance impact to the business workflow may be nontrivial, particularly when validating schemas via serialization. Failed transactions can also prevent business operations from proceeding.
- Data store performance impact
-
The performance impact to the data store may be nontrivial, especially when a significant quantity of records are being written, read, and deleted from the outbox.
Note
Performance impacts must be balanced against other costs. For instance, some organizations simply emit events by parsing change-data capture logs and leave it up to downstream teams to clean up the events after the fact. This incurs its own set of expenses in the form of computing costs for processing and standardizing the events, as well as human-labor costs in the form of resolving incompatible schemas and attending to the effects of strong coupling to internal data models. Costs saved at the producer side are often dwarfed by the expenses incurred at the consumer side for dealing with these issues.
Capturing Change-Data Using Triggers
Trigger support predates many of the auditing, binlog, and write-ahead log patterns examined in the previous sections. Many older relational databases use triggers as a means of generating audit tables. As their name implies, triggers are set up to occur automatically on a particular condition. If it fails, the command that caused the trigger to execute also fails, ensuring update atomicity.
You can capture row-level changes to an audit table by using an AFTER trigger. For example, after any INSERT, UPDATE, or DELETE command, the trigger will write a corresponding row to the change-data table. This ensures that changes made to a specific table are tracked accordingly.
Consider the example shown in Figure 4-12. User data is being upserted to a user table, with a trigger capturing the events as they occur. Note that the trigger is also capturing the time at which the insertion occurred as well as an autoincrementing sequence ID for the event publisher process to use.
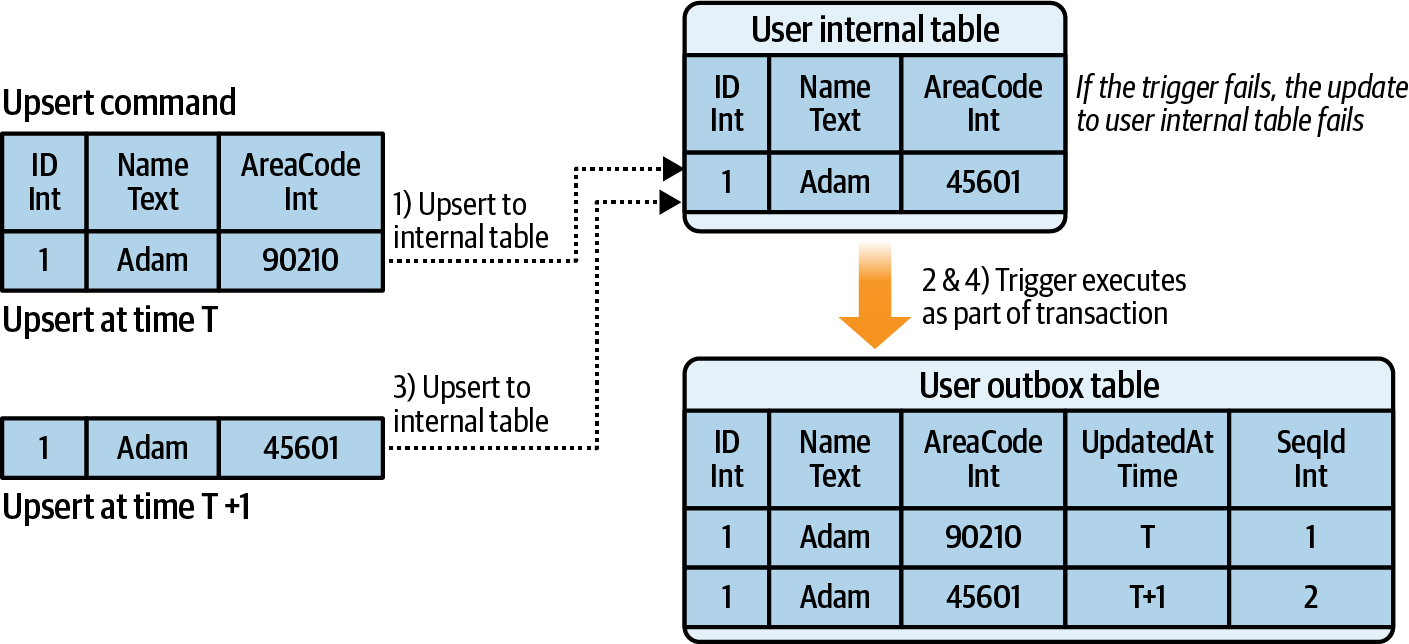
Figure 4-12. Using a trigger to capture changes to a user table
You generally cannot validate the change-data with the event schema during the execution of a trigger, though it is not impossible. One main issue is that it may simply not be supported, as triggers execute within the database itself, and many are limited to the forms of language they can support. While PostgreSQL supports C, Python, and Perl, which may be used to write user-defined functions to perform schema validation, many other databases do not provide multilanguage support. Finally, even if a trigger is supported, it may simply be too expensive. Each trigger fires independently and requires a nontrivial amount of overhead to store the necessary data, schemas, and validation logic, and for many system loads the cost is too high.
Figure 4-13 shows a continuation of the previous example. After-the-fact validation and serialization is performed on the change-data, with successfully validated data produced to the output event stream. Unsuccessful data would need to be error-handled according to business requirements, but would likely require human intervention.
The change-data capture table schema is the bridge between the internal table schema and the output event stream schema. Compatibility among all three is essential for ensuring that data can be produced to the output event stream. Because output schema validation is typically not performed during trigger execution, it is best to keep the change-data table in sync with the format of the output event schema.
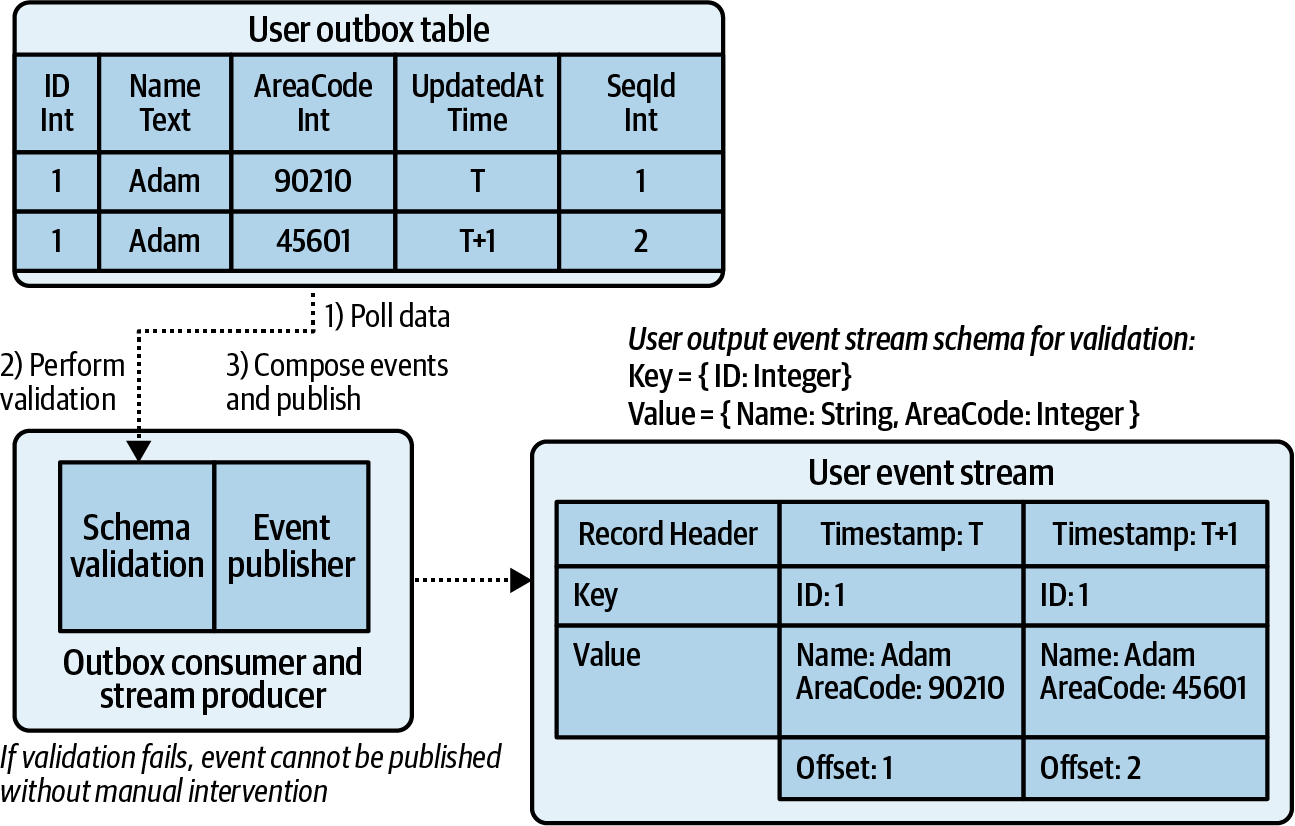
Figure 4-13. After-the-fact validation and production to the output event stream
Tip
Compare the format of the output event schema with the change-data table during testing. This can expose incompatibilities before production deployment.
That being said, triggers can work great in many legacy systems. Legacy systems tend to use, by definition, old technology; triggers have existed for a very long time and may very well be able to provide the necessary change-data capture mechanism. The access and load patterns tend to be well defined and stable, such that the impact of adding triggering can be accurately estimated. Finally, although schema validation is unlikely to occur during the triggering process itself, it may be equally unlikely that the schemas themselves are going to change, simply due to the legacy nature of the system. After-the-fact validation is only an issue if schemas are expected to change frequently.
Warning
Try to avoid the use of triggers if you can instead use more modern functionality for generating or accessing change-data. You should not underestimate the overhead performance and management required for a trigger-based solution, particularly when many dozens or hundreds of tables and data models are involved.
Benefits of using triggers
Benefits of using triggers include the following:
- Supported by most databases
-
Triggers exist for most relational databases.
- Low overhead for small data sets
-
Maintenance and configuration is fairly easy for a small number of data sets.
- Customizable logic
-
Trigger code can be customized to expose only a subset of specific fields. This can provide some isolation into what data is exposed to downstream consumers.
Drawbacks of using triggers
Some cons of using triggers are:
- Performance overhead
-
Triggers execute inline with actions on the database tables and can consume non-trivial processing resources. Depending on the performance requirements and SLAs of your services, this approach may cause an unacceptable load.
- Change management complexity
-
Changes to application code and to data set definitions may require corresponding trigger modifications. Necessary modifications to underlying triggers may be overlooked by the system maintainers, leading to data liberation results that are inconsistent with the internal data sets. Comprehensive testing should be performed to ensure the trigger workflows operate as per expectations.
- Poor scaling
-
The quantity of triggers required scales linearly with the number of data sets to be captured. This excludes any additional triggers that may already exist in the business logic, such as those used for enforcing dependencies between tables.
- After-the-fact schema enforcement
-
Schema enforcement for the output event occurs only after the record has been published to the outbox table. This can lead to unpublishable events in the outbox table.
Tip
Some databases allow for triggers to be executed with languages that can validate compatibility with output event schemas during the trigger’s execution (e.g., Python for PostgreSQL). This can increase the complexity and expense, but significantly reduces the risk of downstream schema incompatibilities.
Making Data Definition Changes to Data Sets Under Capture
Integrating data definition changes can be difficult in a data liberation framework. Data migrations are a common operation for many relational database applications and need to be supported by capture. Data definition changes for a relational database can include adding, deleting, and renaming columns; changing the type of a column; and adding or removing defaults. While all of these operations are valid data set changes, they can create issues for the production of data to liberated event streams.
Note
Data definition is the formal description of the data set. For example, a table in a relational database is defined using a data definition language (DDL). The resultant table, columns, names, types, and indices are all part of its data definition.
For example, if full schema evolution compatibility is required, you cannot drop a non-nullable column without a default value from the data set under capture, as consumers using the previously defined schema expect a value for that field. Consumers would be unable to fall back to any default because none was specified at contract definition time, so they would end up in an ambiguous state. If an incompatible change is absolutely necessary and a breach of data contract is inevitable, then the producer and consumers of the data must agree upon a new data contract.
Caution
Valid alterations to the data set under capture may not be valid changes for the liberated event schema. This incompatibility will cause breaking schema changes that will impact all downstream consumers of the event stream.
Capturing DDL changes depends on the integration pattern used to capture change-data. As DDL changes can have a significant impact on downstream consumers of the data, it’s important to determine if your capture patterns detect changes to the DDL before or after the fact. For instance, the query pattern and CDC log pattern can detect DDL changes only after the fact—that is, once they have already been applied to the data set. Conversely, the change-data table pattern is integrated with the development cycle of the source system, such that changes made to the data set require validation with the change-data table prior to production release.
Handling After-the-Fact Data Definition Changes for the Query and CDC Log Patterns
For the query pattern, the schema can be obtained at query time, and an event schema can be inferred. The new event schema can be compared with the output event stream schema, with schema compatibility rules used to permit or prohibit publishing of the event data. This mechanism of schema generation is used by numerous query connectors, such as those provided with the Kafka Connect framework.
For the CDC log pattern, data definition updates are typically captured to their own part of the CDC log. These changes need to be extracted from the logs and inferred into a schema representative of the data set. Once the schema is generated, it can be validated against the downstream event schema. Support for this functionality, however, is limited. Currently, the Debezium connector supports only MySQL’s data definition changes.
Handling Data Definition Changes for Change-Data Table Capture Patterns
The change-data table acts as a bridge between the output event stream schema and the internal state schema. Any incompatibilities in the application’s validation code or the database’s trigger function will prevent the data from being written to the change-data table, with the error sent back up the stack. Alterations made to the change-data capture table will require a schema evolution compatible with the output event stream, according to its schema compatibility rules. This involves a two-step process, which significantly reduces the chance of unintentional changes finding their way into production.
Sinking Event Data to Data Stores
Sinking data from event streams consists of consuming event data and inserting it into a data store. This is facilitated either by the centralized framework or by a standalone microservice. Any type of event data, be it entity, keyed events, or unkeyed events, can be sunk to a data store.
Event sinking is particularly useful for integrating non-event-driven applications with event streams. The sink process reads the event streams from the event broker and inserts the data into the specified data store. It keeps track of its own consumption offsets and writes event data as it arrives at the input, acting completely independently of the non-event-driven application.
A typical use of event sinking is replacing direct point-to-point couplings between legacy systems. Once the data of the source system is liberated into event streams, it can be sunk to the destination system with few other changes. The sink process operates both externally and invisibly to the destination system.
Data sinking is also employed frequently by teams that need to perform batch-based big-data analysis. They usually do this by sinking data to a Hadoop Distributed File System, which provides big-data analysis tools.
Using a common platform like Kafka Connect allows you to specify sinks with simple configurations and run them on the shared infrastructure. Standalone microservice sinks provide an alternative solution. Developers can create and run them on the microservice platform and manage them independently.
The Impacts of Sinking and Sourcing on a Business
A centralized framework allows for lower-overhead processes for liberating data. This framework may be operated at scale by a single team, which in turn supports the data liberation needs of other teams across the organization. Teams looking to integrate then need only concern themselves with the connector configuration and design, not with any operational duties. This approach works best in larger organizations where data is stored in multiple data stores across multiple teams, as it allows for a quick start to data liberation without each team needing to construct its own solution.
There are two main traps that you can fall into when using a centralized framework. First, the data sourcing/sinking responsibilities are now shared between teams. The team operating the centralized framework is responsible for the stability, scaling, and health of both the framework and each connector instance. Meanwhile, the team operating the system under capture is independent and may make decisions that alter the performance and stability of the connector, such as adding and removing fields, or changing logic that affects the volume of data being transmitted through the connector. This introduces a direct dependency between these two teams. These changes can break the connectors, but may be detected only by the connector management team, leading to linearly scaling, cross-team dependencies. This can become a difficult-to-manage burden as the number of changes grows.
The second issue is a bit more pervasive, especially in an organization where event-driven principles are only partially adopted. Systems can become too reliant upon frameworks and connectors to do their event-driven work for them. Once data has been liberated from the internal state stores and published to event streams, the organization may become complacent about moving onward into microservices. Teams can become overly reliant upon the connector framework for sourcing and sinking data, and choose not to refactor their applications into native event-driven applications. In this scenario they instead prefer to just requisition new sources and sinks as necessary, leaving their entire underlying application completely ignorant to events.
Warning
CDC tools are not the final destination in moving to an event-driven architecture, but instead are primarily meant to help bootstrap the process. The real value of the event broker as the data communication layer is in providing a robust, reliable, and truthful source of event data decoupled from the implementation layers, and the broker is only as good as the quality and reliability of its data.
Both of these issues can be mitigated through a proper understanding of the role of the change-data capture framework. Perhaps counterintuitively, it’s important to minimize the usage of the CDC framework and have teams implement their own change-data capture (such as the outbox pattern) despite the additional up-front work this may require. Teams become solely responsible for publishing and their system’s events, eliminating cross-team dependencies and brittle connector-based CDC. This minimizes the work that the CDC framework team needs to do and allows them to focus on supporting products that truly need it.
Reducing the reliance on the CDC framework also propagates an “event-first” mind-set. Instead of thinking of event streams as a way to shuffle data between monoliths, you view each system as a direct publisher and consumer of events, joining in on the event-driven ecosystem. By becoming an active participant in the EDM ecosystem, you begin to think about when and how the system needs to produce events, about the data out there instead of just the data in here. This is an important part of the cultural shift toward successful implementation of EDM.
For products with limited resources and those under maintenance-only operation, a centralized source and sink connector system can be a significant boon. For other products, especially those that are more complex, have significant event stream requirements, and are under active development, ongoing maintenance and support of connectors is unsustainable. In these circumstances it is best to schedule time to refactor the codebase as necessary to allow the application to become a truly native event-driven application.
Finally, carefully consider the tradeoffs of each of the CDC strategies. This often becomes an area of discussion and contention within an organization, as teams try to figure out their new responsibilities and boundaries in regard to producing their events as the single source of truth. Moving to an event-driven architecture requires investment into the data communication layer, and the usefulness of this layer can only ever be as good as the quality of data within it. Everyone within the organization must shift their thinking to consider the impacts of their liberated data on the rest of the organization and come up with clear service-level agreements as to the schemas, data models, ordering, latency, and correctness for the events they are producing.
Summary
Data liberation is an important step toward providing a mature and accessible data communication layer. Legacy systems frequently contain the bulk of the core business domain models, stored within some form of centralized implementation communication structure. This data needs to be liberated from these legacy systems to enable other areas of the organization to compose new, decoupled products and services.
There are a number of frameworks, tools, and strategies available to extract and transform data from their implementation data stores. Each has its own benefits, drawbacks, and tradeoffs. Your use cases will influence which options you select, or you may find that you must create your own mechanisms and processes.
The goal of data liberation is to provide a clean and consistent single source of truth for data important to the organization. Access to data is decoupled from the production and storage of it, eliminating the need for implementation communication structures to serve double duty. This simple act reduces the boundaries for accessing important domain data from the numerous implementations of legacy systems and directly promotes the development of new products and services.
There is a full spectrum of data liberation strategies. On one end you will find careful integration with the source system, where events are emitted to the event broker as they are written to the implementation data store. Some systems may even be able to produce to the event stream first before consuming it back for their own needs, further reinforcing the event stream as the single source of truth. The producer is cognizant of its role as a good data-producing citizen and puts protections in place to prevent unintentional breaking changes. Producers seek to work with the consumers to ensure a high-quality, well-defined data stream, minimize disruptive changes, and ensure changes to the system are compatible with the schemas of the events they are producing.
On the other end of the spectrum, you’ll find the highly reactive strategies. The owners of the source data in the implementation have little to no visibility into the production of data into the event broker. They rely completely on frameworks to either pull the data directly from their internal data sets or parse the change-data capture logs. Broken schemas that disrupt downstream consumers are common, as is exposure of internal data models from the source implementation. This model is unsustainable in the long run, as it neglects the responsibility of the owner of the data to ensure clean, consistent production of domain events.
The culture of the organization dictates how successful data liberation initiatives will be in moving toward an event-driven architecture. Data owners must take seriously the need to produce clean and reliable event streams, and understand that data capture mechanisms are insufficient as a final destination for liberating event data.
Get Building Event-Driven Microservices now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

