July 2020
Intermediate to advanced
364 pages
9h 2m
English
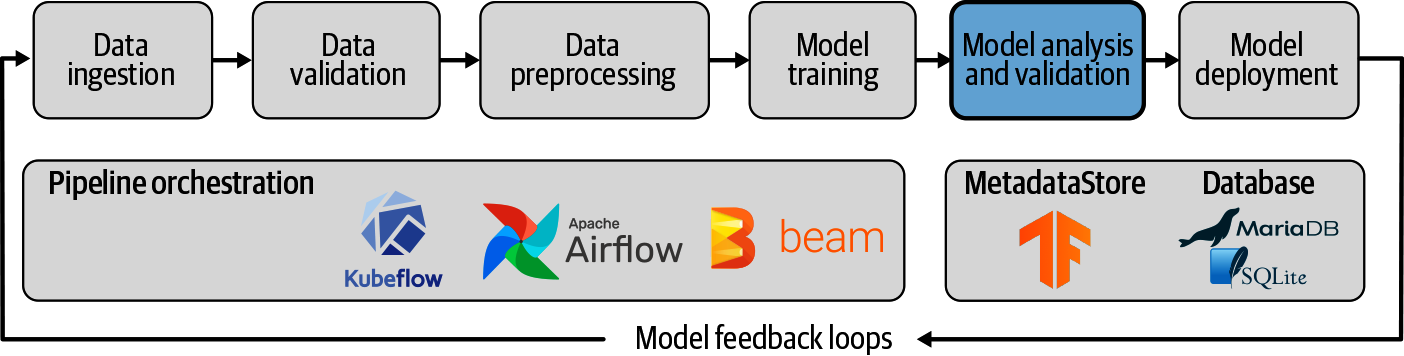
At this point in our machine learning pipeline, we have checked the statistics of our data, we have transformed our data into the correct features, and we have trained our model. Surely now it’s time to put the model into production? In our opinion, there should be two extra steps before you move on to deploy your model: analyzing your model’s performance in-depth and checking that it will be an improvement on any model that’s already in production. We show where these steps fit into the pipeline in Figure 7-1.
While we’re training a model, we’re monitoring its performance on an evaluation set during training, and we’re also trying out a variety of hyperparameters to get peak performance. But it’s common to only use one metric during training, and often this metric is accuracy.
When we’re building a machine learning pipeline, we’re often trying to answer a complex business question or trying to model a complex real-world system. One single metric is often not enough to tell us whether our model will answer that question. This is particularly true if our dataset is imbalanced or if some of our model’s decisions have higher consequences than others.
In addition, a single metric that averages performance over an entire evaluation set can hide a lot of important details. If ...
Read now
Unlock full access






