Chapter 4. Documents and Text
Up until this point, we’ve looked at multi-model through the lens of data integration with a focus on integrating data from relational systems. This is frequently where data integration begins, but there is tremendous value in being able to search structured data with unstructured and semi-structured data such as documents and text. Unfortunately, most people who hear documents and text in relation to a database automatically think of Binary Large OBjects (BLOBs) or Character Large OBjects (CLOBs) or the amount of shredding required to get those documents and text to fit a relational schema. But a multi-model database allows us to load them and use them as is because their text and structure are self-describing.
When we asked more than 200 IT professionals what percentage of their data was not relational, 44% said 1 to 25% of their data was unstructured. That is a shockingly low volume of unstructured data—for a surprisingly high number of organizations. Although it is possible that these organizations really do have a paucity of data that isn’t relational, it is more likely that most companies aren’t dealing with their unstructured data because it is simply too inconvenient to do so.
The ubiquity of relational databases has meant that, for many, only that which fits in a relational database management systems (RDBMS)—billing, payroll, customer, and inventory—is considered data. But this view of data is changing. Analysts estimate that more than 80% of data being created and stored is unstructured. This includes documentation, instant messages, email, customer communications, contracts, product information, and website tracking data.
So why does the survey indicate that at most 25% of an organization’s data is unstructured? Possibly because data that is unstructured (or even semi-structured) is rarely dealt with by IT management.
That doesn’t make unstructured data low-value. In fact, the inverse is true. Instead, it means this highly valuable content is unused.
But there are options for modeling, storing, and querying unstructured data that give us insight into the 80% of the data that, for many, has remained unexplored. Further, any multi-model database that includes a structured model, such as JSON or XML, with text indexing provides the ability to query structured and unstructured data together.
Schemas Are Key to Querying Documents
XML and JSON documents are self-describing. The schema is already defined within the elements and properties already written within each document. Multi-model systems can identify this implicit schema when data is imported into the database and allow you to immediately query it.
Schemas create a consistent way to describe and query your data. As we noted earlier, in a relational database, the schema is defined in terms of tables, columns, and attributes; each table has one or more columns, and each column has one or more attributes. Different rows in a relational database table have the same schema—period. This makes the schema static, with only slow, painful, and costly changes possible. Relational systems are schema-first, in that we have to define the schema before pouring in the data. Changing the shape of the schema after data has been poured in can be painfully challenging and costly.
In a nonrelational database, the idea of a schema is more fluid. Some NoSQL databases have a concept of a schema that is similar to the relational picture, but most do not. Of those that do not, you can further divide them into databases for which the schema is latent, that is implicit, in the structure of each semi-structured or unstructured entity. When working with data from existing sources, your data has already been modeled. Data usually comes to us with some shape to it. When we load XML or JSON documents into a multi-model database, the latent or implicit schema is already defined within the XML elements or JSON properties of the documents, as demonstrated in Figure 4-1.

Figure 4-1. Same document saved in two different formats
If the primary data entity is a document, frequently represented as an XML or JSON object, the latent schema implicit in a document might be different than that of another document in the same NoSQL database or database collection. That is to say, one document might have a title and author, whereas another has a headline and writer. Each of those two documents can be in the same NoSQL database because the schema is included in the documents themselves. In other words, in document stores, the schema is organized in each document, but it’s not defined externally as it would be in a relational database. The latent schema is the shape of the data when you loaded it. In NoSQL databases, the schema for any document could, and often does, change frequently.
A true multi-model database is schema-agnostic and schema-aware so that you are not forced to cast your queries in a predefined and unchanging schema.
This is perfect for managing and querying text, and for querying text with structured data. This gives you a semantic view of varied databases and one place where you can look up every fact that you have. In that case, a multi-model database handles (at least) a document data model as well as semantic RDF data.
In the preceding documents, a multi-model database will index the JSON properties and XML elements as well as their values. In this way, the system is schema-aware, in that element and property values can be used for structured queries such as this one:
Show me the documents where heading equals "Data Models"
We also can use them as full-text search queries such as the following:
Show me any documents with the word "relational" in them anywhere in the document.
Combining full-text search and structured query, we should be able to perform a search query of the following type:
Search for documents with the word "relational" anywhere in a paragraph element/property.
A multi-model database management system must let you load data with multiple schemas. You shouldn’t need to be concerned about lengths nor worry about cardinality of elements/properties. And, if something unexpected shows up tomorrow, you can still store it just fine.
Document-Store Approach to Search
In a document-store, documents are akin to rows, although a contract will make a lot more sense stored as a document versus stored as a row. Now, without knowing anything else about the document, you would be able to do a Boolean and full-text search against it. This approach sounds familiar if you have used Apache Lucene or Apache SOLR.
Flexible Indexing
The beauty of indexing in a document store is that it also provides for structured search, indexing the inherent structure of the document in addition to the text and values within the document. That is to say, documents have plenty of structure, including titles, section headings, book chapters, headers, footers, contract IDs, line items, addresses, and subheadings, and we can describe that structure by using JSON properties or XML elements. A multi-model database creates a generalized index of the JSON and XML values for that structure and indexes every value and every parent-child relationship that has been defined. In other words, the document model operating in a multi-model database, where anything can be added to any record (and is immediately queryable in a structured way) is far more powerful and flexible than the related-table model of a relational database for storing rich representations of entities. It also allows us to store, manage, and query relationships between those entities.
With a multi-model database, we can also extend the generalized document text and structure index with special purpose indexes such as range, geospatial, bitemporal, and triples.
Mapping (Mainframe) Data into Documents
Let’s take a moment to look at documents that might come to us from mainframe systems. COBOL copybooks and Virtual Storage Access Method (VSAM) can actually be a very good fit for the document model.
COBOL is an acronym for the Common Business-Oriented Language. It’s an older computer language designed for business use and found in many legacy mainframe applications. Data in these systems is found in copybook format, which is used to define data elements that can be referenced by COBOL programs. Due to the declining popularity of mainframes and the retirement of experienced COBOL programmers, COBOL-based programs are being migrated to new platforms, rewritten in modern languages, or replaced with software packages; and their associated data is being moved to more modern repositories such as NoSQL and multi-model databases.
Copybooks capture data resembling objects, or entities, and as a result are often a more natural fit for a document store than relational. You can transform a copybook object into an XML or JSON document in a pretty straightforward manner, as illustrated in Figure 4-2. There are open source libraries available on the web to help do this.

Figure 4-2. COBOL copybook as XML
Additionally, the REDEFINES clause in COBOL creates a data polymorphism, something else that isn’t simple or easy to capture in a relational system. Using entities and relationships in a multi-model system, however, this becomes a much more straightforward transformation, as shown in Figure 4-3.
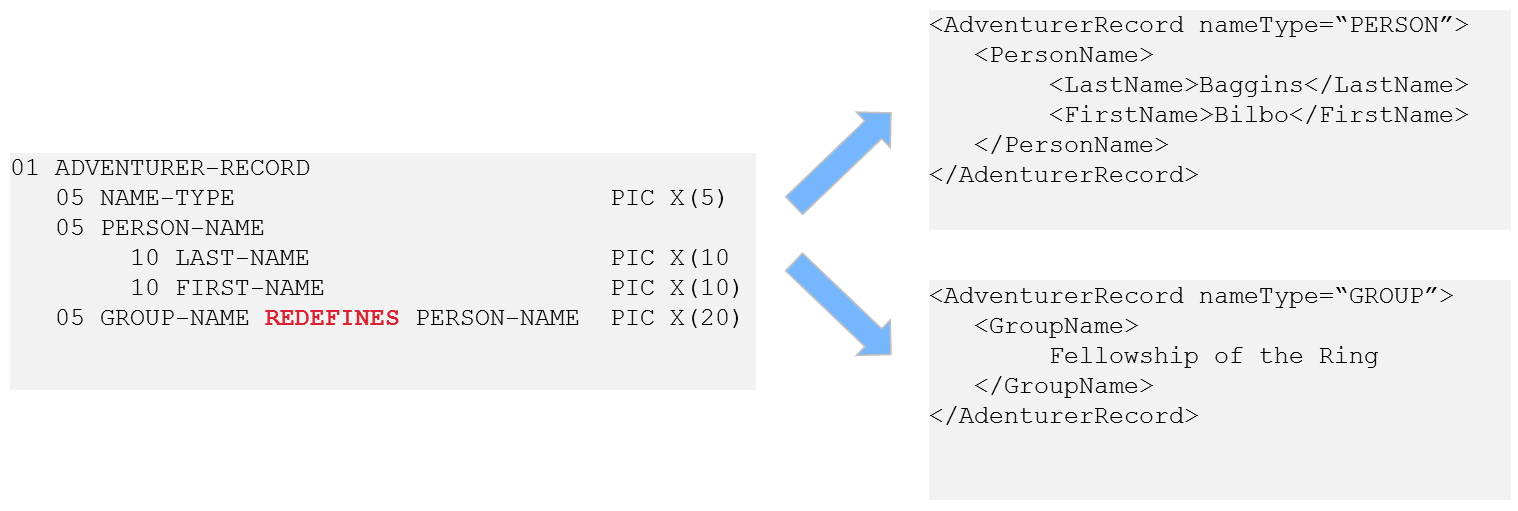
Figure 4-3. COBOL REDFINES clause simpler to manage as XML
Along with COBOL, we might find VSAM files along our mainframe data integration path. These are generally exported from their source mainframe as fixed-width text files. You’ll receive the data in one set of files, and then a specification file that lets you know the offsets for the data for each row in a data file (characters 1–10 are the customer_id, 11–21 are first_name, 22–34 are last_name, etc.). These are generally parsed using Java and saved in XML or JSON within a multi-model or document database.
We mention this here because, again, in using multi-model for data integration, we’ll be concerned with capturing entities and relationships. These are often already defined within their source systems, and those source systems might be mainframes from which we import COBOL copybooks and VSAM files. On their own, these formats are binary, so processing into a document format for search and reuse will be required. But after you’ve done that, they will be immediately available for search and reuse along with all your other data in a multi-model database. And this is what we see organizations are doing today. Many large organizations modernizing their architectures to replace and remove legacy mainframes are bypassing relational databases and jumping straight to NoSQL and multi-model ones.
Indexing Relationships
As previously mentioned, a multi-model database can use triples to represent relationships between entities. As a reminder, a triple is called a triple because it consists of three things: a subject, a predicate, and an object. In other words, it models two “things” and the relationship between them. This creates very granular facts.
Unlike primary/foreign key relationships in a relational database, these facts have meaning because we can infer new data based on the semantic meaning inherent in the facts we already had. In other words, triples don’t just need to relate entities to other entities; they can relate entities to concepts, and even concepts to other concepts.
We can even store a data dictionary or ontology right in the database along with the data, so the meaning of the relationships can be preserved in both human- and machine-readable form.
To scale, a multi-model database should automatically index relationships between entities so that they can be joined, queried, combined with other triples, and used to build inferences.
If all indexes know the same document ID, we can compose queries against this single integrated index.
The net result is multiple data models, but one integrated index.
Note
Take care when dealing with vendors who have implemented their multi-model solutions by stitching together multiple disparate products (a multiproduct, multi-model database). Each product has its own queries and indexes, and there exists the potential for inconsistencies between data. Each purpose-built data store requires an API into each repository. On the development side, the burden is on the coder to write code that queries each data store, and then splices and joins the two separate results together in an application tier. More lines of code equal more points of failure in an application and more risk. Further, this type of query can never be performant; it’s a join that can be performed only one way.
Scaling multiproduct, multi-model systems will also introduce more complexity, which can be difficult to overcome. Different systems require different indexes and have different scalability requirements. If developers write code to bring together a document store with a search engine and a triple store and call this multi-model, a lot of orchestration and infrastructure work must be implemented at the beginning of the project, and the system will only ever be as fast as the slowest application. All that orchestration code will also now require continued maintenance by your development staff.
A multi-model product that’s delivered as a single application to include support for documents, graphs, and search will scale more effectively and perform better than a multiproduct, multi-model approach every time. Because the focus on plumbing disparate components isn’t required, with a true multi-model system, developers can load data as is and begin building applications to deliver data immediately without having to handle the upfront cost of plumbing disparate systems together for the same purposes. We’ll examine this further in upcoming chapters.
By looking at the schema-agnostic, schema-aware, and flexible indexing characteristics of a multi-model database, we’ve addressed the agility a multi-model database provides us in managing our conceptual and physical data models in the system as well as managing those documents as JSON, XML, binary, or text. We now need to take a closer look at how we access and interact with this data.
Get Building on Multi-Model Databases now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

