Chapter 1. Introduction to Continuous Delivery
Continuous Delivery is one of the most valuable approaches to software development to emerge in recent years. At its core, Continuous Delivery is a set of practices and disciplines that enable organizations to reach and maintain a high-speed, predictable, steady, and safe stream of valuable software changes irrespective of the kind of software being developed. Continuous Delivery works not just for web-based software, but also mobile apps, on-premise hosted desktop software, device firmware, and so on.
In 2010, Jez Humble and Dave Farley wrote the book Continuous Delivery [HumbleFarley] based on their experiences building and releasing software for clients around the world. Their book is a hugely valuable collection of techniques, advice, and suggestions for software delivery and provides the de facto definition of Continuous Delivery.
What Continuous Delivery Is Not
Many people confuse Continuous Delivery with Continuous Deployment, but the two are quite different in purpose and execution. As seen in Figure 1-1, Continuous Delivery aims to enable regular, rapid, reliable software releases through a set of sound practices, giving the people who “own” the software product the power to decide when to release changes. Continuous Delivery is a so-called pull-based approach, because software is “pulled” through the delivery mechanism when needed, and applies to all kinds of software (web, desktop, embedded, etc.).
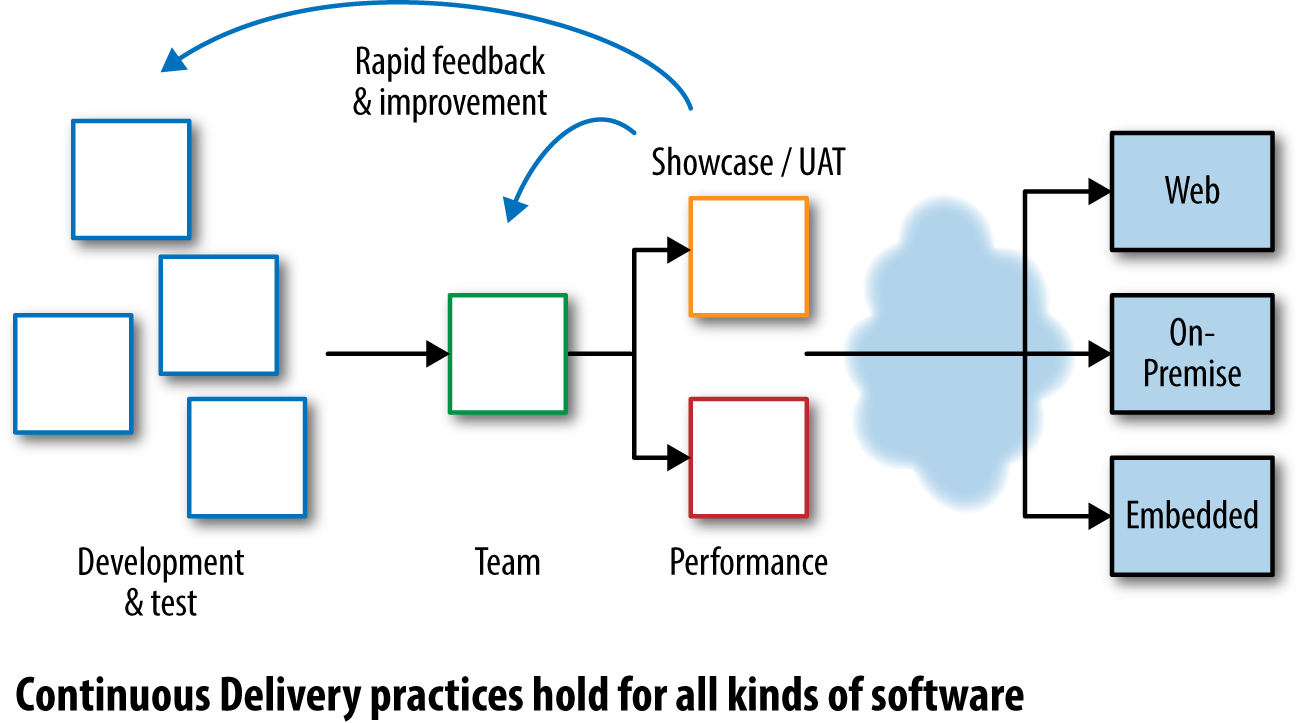
Figure 1-1. Continuous Delivery feedback
In contrast, as shown in Figure 1-2, Continuous Deployment is a push-based approach: when software developers commit a new feature to version control, it is pushed toward the Live systems automatically after successfully passing through a series of automated tests and checks. This results in many Production deployments a day.
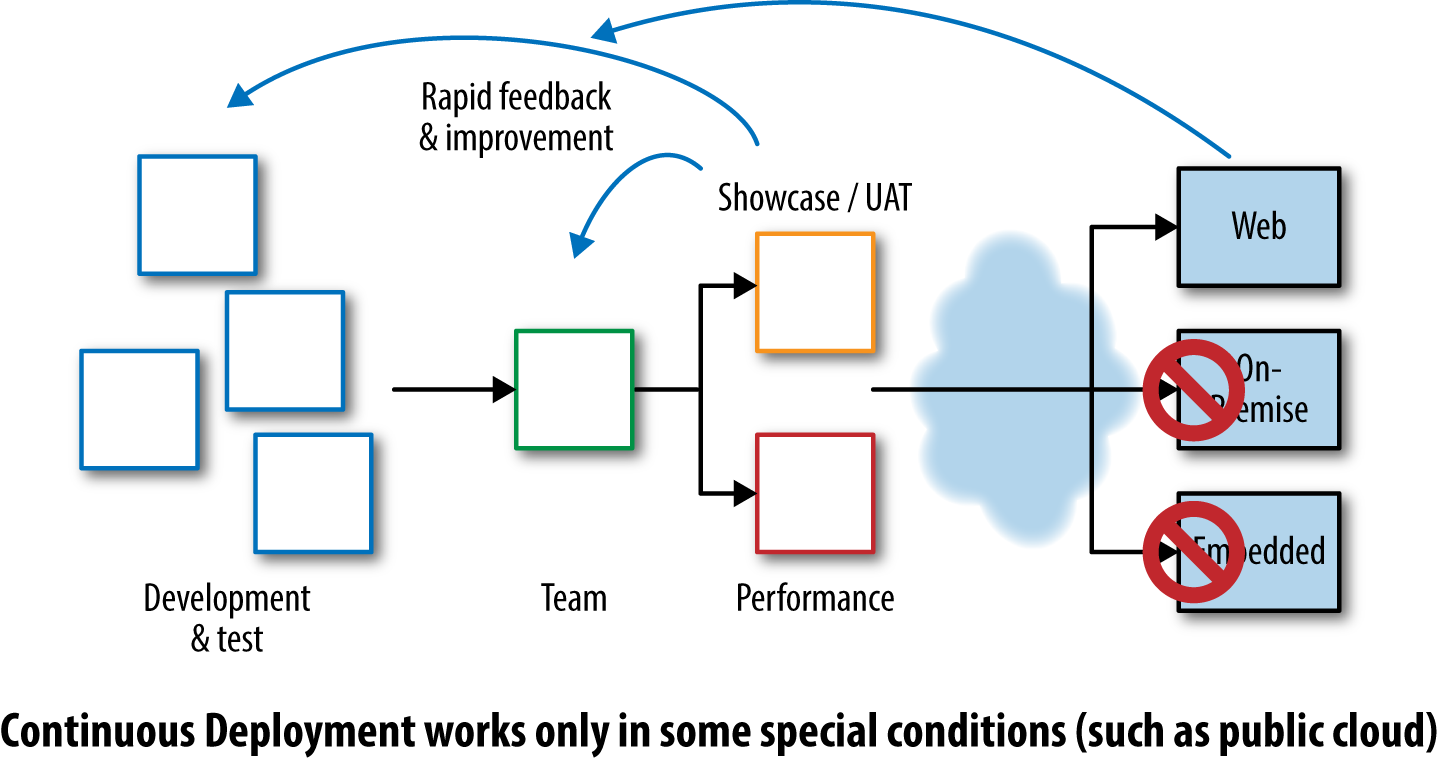
Figure 1-2. Continuous Deployment feedback
From our experience, Continuous Deployment is a niche practice useful for web-based systems in small, highly focused development teams. Continuous Delivery suits a much wider range of software scenarios and is a much more effective approach with management: “we’re giving you the power to choose when to release new features” is quite an eye-opener for many in senior management!
The Importance of Automation for Continuous Delivery
In Continuous Delivery, we aim to automate all the repetitive, error-prone activities that humans do that can lead to inconsistent, unreliable, or unrepeatable processes and outputs:
-
Software compilation and unit testing (“builds”)
-
Software testing (component, service, integration, and UI)
-
Deployment of software and infrastructure through all environments, including Production
-
Configuration of applications and infrastructure (including networks, DNS, virtual machines [VMs], and load balancers)
-
Database changes (reference data, schema changes, and data migrations)
-
Approval of everyday IT changes (“standard changes”)
-
The tracking and tracing of change history and authorizations
-
Testing of Production systems
Note
We use the word “Production” to refer to the environment where your software is serving customers. This is sometimes called “Live,” but we feel this is a loaded term likely to cause confusion.
These are all areas where we can get computers to do a much better job than humans: more consistent, more repeatable, more reliable. Areas that we leave for human input are limited to those areas where humans add a huge amount of value: software development itself, test strategy and approaches, exploratory testing [Hendrickson], performance test analysis, and deployment and rollback decisions.
Why Is Continuous Delivery Needed?
Developing and operating modern software successfully requires a combination of good tools, well-trained and well-socialized people, good team discipline, a clear and shared purpose, and well-aligned financial and organizational goals. Too many organizations believe that they can do without one or more of these ingredients, but the result is that software is expensive, late, or faulty, and often all three.
By adopting Continuous Delivery, organizations can lay the foundations for highly effective software delivery and operations, consistently producing high-quality software that works well in Production and delights clients and customers.
Why Windows Needs Special Treatment
Many of the tools commonly used for Continuous Delivery are not available natively for the Windows platform, so we need to find Windows-native approaches that achieve the same ends.
In particular, package management (in the form of NuGet and Chocolatey) has only been available on the Windows platform since 2010, whereas operating systems such as Linux and BSD (and more recently Mac) have used package management for software distribution and installation since at least 1997. Other good approaches being adopted on Windows are:
-
Plain text files for configuration of applications and services (rather than the Windows Registry or databases)
-
Controlling application behavior from the command line (rather than a GUI)
-
A multivendor, open source–friendly approach to software in the Windows ecosystem
-
Easily scriptable package management with declarative dependencies
Many of the new and forthcoming features in Windows Server 2016 and Visual Studio 2015/Visual Studio Online (VSO) are designed with Continuous Delivery in mind.
Note
PowerShell provides a command-line interface to Windows for controlling application and system behavior and configuration. As a result, PowerShell is now the primary means of automating Windows components and .NET software.
The tips and advice in this book will help you navigate the route to Continuous Delivery on the Windows/.NET platform. Real-world case studies with Windows/.NET software show that successful companies around the world are using the techniques.
Terminology Used in This Book
We’ll use these terms throughout the book:
- Artifact
-
Immutable, versioned files or collections of files that are used for deployments
- Continuous Delivery (CD)
-
Reliable software releases through build, test, and deployment automation
- Continuous Integration (CI)
-
Integrating work from developers as soon as possible, many times a day
- Cycle time
-
The time spent by the team working on an item until the item is delivered (in a Continuous Delivery context)
- DBA
-
Database administrator
- DSC
-
Desired State Configuration
- DSL
-
Domain-specific language
- IIS
-
Internet Information Services
- Infrastructure
-
Servers, networks, storage, DNS, virtualization—things that support the platform
- Infrastructure configuration management (or just config management)
-
See Infrastructure as code
- Infrastructure as code
-
Treating infrastructure as if it were software, and using software development techniques (such as test-driven development) when developing infrastructure code
- LDAP
-
Lightweight Directory Access Protocol
- On-premise
-
Self-hosted systems, managed internally by the organization—the opposite of SaaS-hosted systems
- Package management
-
Software and established practices for dependency management via named collections of files with specific version numbers
- Production
-
The environment where the software runs and serves customers, also known as Live
- SCCM
-
System Center Configuration Manager
- Software-as-a-Service (SaaS)
-
Hosted software services—the opposite of on-premise or self-hosted systems
- SysAdmin
-
System administrator
- Test-driven development (TDD)
-
Evolving software in a safe, stepwise way, emphasizing maintainability and clarity of purpose
- User interface (UI)
-
Also known as graphical user interface (GUI)
- Version control system (VCS)
-
Sometimes called source code control or revision control
Get Continuous Delivery with Windows and .NET now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

