Preface
With the development of massive search engines (such as Google and Yahoo!), genomic analysis (in DNA sequencing, RNA sequencing, and biomarker analysis), and social networks (such as Facebook and Twitter), the volumes of data being generated and processed have crossed the petabytes threshold. To satisfy these massive computational requirements, we need efficient, scalable, and parallel algorithms. One framework to tackle these problems is the MapReduce paradigm.
MapReduce is a software framework for processing large (giga-, tera-, or petabytes) data sets in a parallel and distributed fashion, and an execution framework for large-scale data processing on clusters of commodity servers. There are many ways to implement MapReduce, but in this book our primary focus will be Apache Spark and MapReduce/Hadoop. You will learn how to implement MapReduce in Spark and Hadoop through simple and concrete examples.
This book provides essential distributed algorithms (implemented in MapReduce, Hadoop, and Spark) in the following areas, and the chapters are organized accordingly:
-
Basic design patterns
-
Data mining and machine learning
-
Bioinformatics, genomics, and statistics
-
Optimization techniques
What Is MapReduce?
MapReduce is a programming paradigm that allows for massive scalability across hundreds or thousands of servers in a cluster environment. The term MapReduce originated from functional programming and was introduced by Google in a paper called “MapReduce: Simplified Data Processing on Large Clusters.” Google’s MapReduce[8] implementation is a proprietary solution and has not yet been released to the public.
A simple view of the MapReduce process is illustrated in Figure P-1. Simply put, MapReduce is about scalability. Using the MapReduce paradigm, you focus on writing two functions:
map()- Filters and aggregates data
reduce()- Reduces, groups, and summarizes by keys generated by
map()
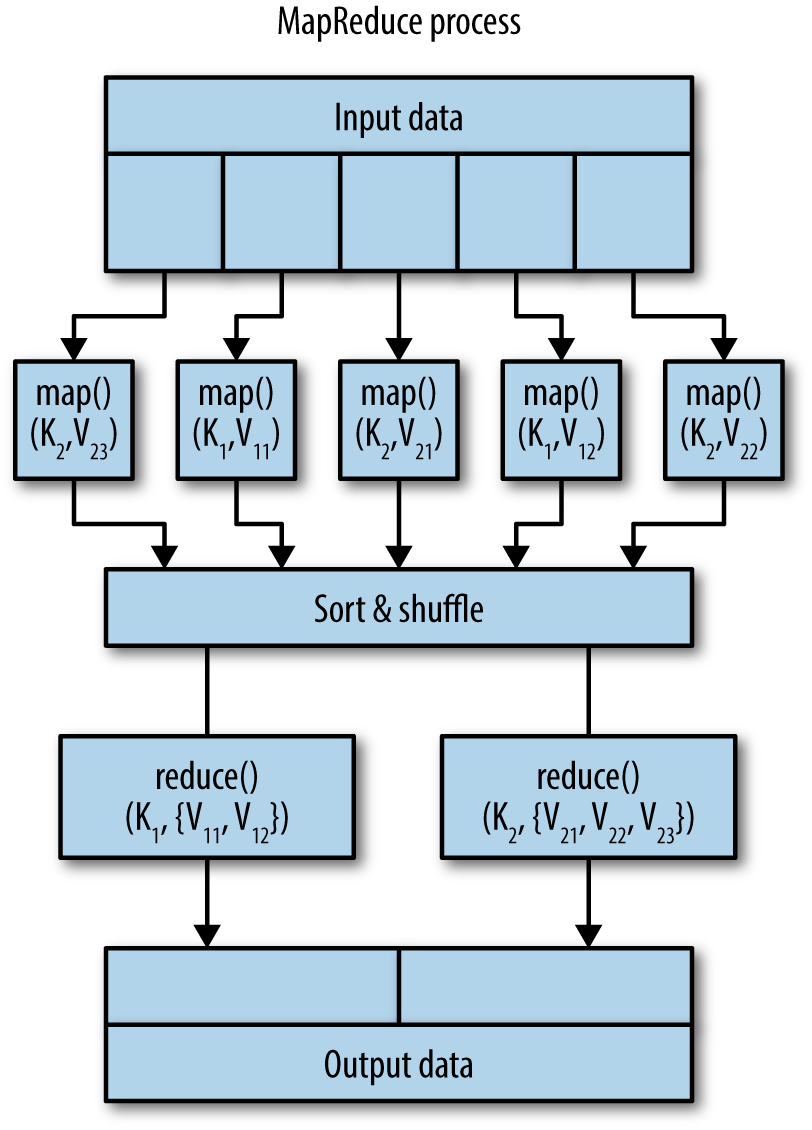
Figure P-1. The simple view of the MapReduce process
These two functions can be defined as follows:
map()function-
The master node takes the input, partitions it into smaller data chunks, and distributes them to worker (slave) nodes. The worker nodes apply the same transformation function to each data chunk, then pass the results back to the master node. In MapReduce, the programmer defines a mapper with the following signature:
map():(Key1,Value1)→[(Key2,Value2)] reduce()function-
The master node shuffles and clusters the received results based on unique key-value pairs; then, through another redistribution to the workers/slaves, these values are combined via another type of transformation function. In MapReduce, the programmer defines a reducer with the following signature:
reduce():(Key2,[Value2])→[(Key3,Value3)]
Note
In informal presentations of themap() and reduce() functions throughout this book, I’ve used square brackets, [], to denote a list.In Figure P-1, input data is partitioned into small chunks (here we have five input partitions), and each chunk is sent to a mapper. Each mapper may generate any number of key-value pairs. The mappers’ output is illustrated by Table P-1.
| Key | Value |
|---|---|
| K1 | V11 |
| K2 | V21 |
| K1 | V12 |
| K2 | V22 |
| K2 | V23 |
In this example, all mappers generate only two unique keys: {K1, K2}. When all mappers are completed, the keys are sorted, shuffled, grouped, and sent to reducers. Finally, the reducers generate the desired outputs. For this example, we have two reducers identified by {K1, K2} keys (illustrated by Table P-2).
| Key | Value |
|---|---|
| K1 | {V11, V12} |
| K2 | {V21, V22, V23} |
Once all mappers are completed, the reducers start their execution process. Each reducer may create as an output any number—zero or more—of new key-value pairs.
When writing your map() and reduce() functions, you need to make sure that your solution is scalable. For example, if you are utilizing any data structure (such as List, Array, or HashMap) that will not easily fit into the memory of a commodity server, then your solution is not scalable. Note that your map() and reduce() functions will be executing in basic commodity servers, which might have 32 GB or 64 GB of RAM at most (note that this is just an example; today’s servers have 256 GB or 512 GB of RAM, and in the next few years basic servers might have even 1 TB of RAM). Scalability is therefore the heart of MapReduce. If your MapReduce solution does not scale well, you should not call it a MapReduce solution. Here, when we talk about scalability, we mean scaling out (the term scale out means to add more commodity nodes to a system). MapReduce is mainly about scaling out (as opposed to scaling up, which means adding resources such as memory and CPUs to a single node). For example, if DNA sequencing takes 60 hours with 3 servers, then scaling out to 50 similar servers might accomplish the same DNA sequencing in less than 2 hours.
The core concept behind MapReduce is mapping your input data set into a collection of key-value pairs, and then reducing over all pairs with the same key. Even though the overall concept is simple, it is actually quite expressive and powerful when you consider that:
-
Almost all data can be mapped into key-value pairs.
-
Your keys and values may be of any type:
Strings,Integers, FASTQ (for DNA sequencing), user-defined custom types, and, of course, key-value pairs themselves.
How does MapReduce scale over a set of servers? The key to how MapReduce works is to take input as, conceptually, a list of records (each single record can be one or more lines of data). Then the input records are split and passed to the many servers in the cluster to be consumed by the map() function. The result of the map() computation is a list of key-value pairs. Then the reduce() function takes each set of values that have the same key and combines them into a single value (or set of values). In other words, the map() function takes a set of data chunks and produces key-value pairs, and reduce() merges the output of the data generated by map(), so that instead of a set of key-value pairs, you get your desired result.
One of the major benefits of MapReduce is its “shared-nothing” data-processing platform. This means that all mappers can work independently, and when mappers complete their tasks, reducers start to work independently (no data or critical region is shared among mappers or reducers; having a critical region will slow distributed computing). This shared-nothing paradigm enables us to write map() and reduce() functions easily and improves parallelism effectively and effortlessly.
Simple Explanation of MapReduce
What is a very simple explanation of MapReduce? Let’s say that we want to count the number of books in a library that has 1,000 shelves and report the final result to the librarian. Here are two possible MapReduce solutions:
-
Solution #1 (using
map()andreduce()):-
map(): Hire 1,000 workers; each worker counts one shelf. -
reduce(): All workers get together and add up their individual counts (by reporting the results to the librarian).
-
-
Solution #2 (using
map(),combine(), andreduce()):-
map(): Hire 1,110 workers (1,000 workers, 100 managers, 10 supervisors—each supervisor manages 10 managers, and each manager manages 10 workers); each worker counts one shelf, and reports its count to its manager. -
combine(): Every 10 managers add up their individual counts and report the total to a supervisor. -
reduce(): All supervisors get together and add up their individual counts (by reporting the results to the librarian).
-
When to Use MapReduce
Is MapReduce good for everything? The simple answer is no. When we have big data, if we can partition it and each partition can be processed independently, then we can start to think about MapReduce algorithms. For example, graph algorithms do not work very well with MapReduce due to their iterative approach. But if you are grouping or aggregating a lot of data, the MapReduce paradigm works pretty well. To process graphs using MapReduce, you should take a look at the Apache Giraph and Apache Spark GraphX projects.
Here are other scenarios where MapReduce should not be used:
-
If the computation of a value depends on previously computed values. One good example is the Fibonacci series, where each value is a summation of the previous two values:
F(k + 2) = F(k + 1) + F(k)
-
If the data set is small enough to be computed on a single machine. It is better to do this as a single
reduce(map(data))operation rather than going through the entire MapReduce process. -
If synchronization is required to access shared data.
-
If all of your input data fits in memory.
-
If one operation depends on other operations.
-
If basic computations are processor-intensive.
However, there are many cases where MapReduce is appropriate, such as:
-
When you have to handle lots of input data (e.g., aggregate or compute statistics over large amounts of data).
-
When you need to take advantage of parallel and distributed computing, data storage, and data locality.
-
When you can do many tasks independently without synchronization.
-
When you can take advantage of sorting and shuffling.
-
When you need fault tolerance and you cannot afford job failures.
What MapReduce Isn’t
MapReduce is a groundbreaking technology for distributed computing, but there are a lot of myths about it, some of which are debunked here:
-
MapReduce is not a programming language, but rather a framework to develop distributed applications using Java, Scala, and other programming languages.
-
MapReduce’s distributed filesystem is not a replacement for a relational database management system (such as MySQL or Oracle). Typically, the input to MapReduce is plain-text files (a mapper input record can be one or many lines).
-
The MapReduce framework is designed mainly for batch processing, so we should not expect to get the results in under two seconds; however, with proper use of clusters you may achieve near-real-time response.
-
MapReduce is not a solution for all software problems.
Why Use MapReduce?
As we’ve discussed, MapReduce works on the premise of “scaling out” by adding more commodity servers. This is in contrast to “scaling up,” by adding more resources, such as memory and CPUs, to a single node in a system); this can be very costly, and at some point you won’t be able to add more resources due to cost and software or hardware limits. Many times, there are promising main memory–based algorithms available for solving data problems, but they lack scalability because the main memory is a bottleneck. For example, in DNA sequencing analysis, you might need over 512 GB of RAM, which is very costly and not scalable.
If you need to increase your computational power, you’ll need to distribute it across more than one machine. For example, to do DNA sequencing of 500 GB of sample data, it would take one server over four days to complete just the alignment phase; using 60 servers with MapReduce can cut this time to less than two hours. To process large volumes of data, you must be able to split up the data into chunks for processing, which are then recombined later. MapReduce/Hadoop and Spark/Hadoop enable you to increase your computational power by writing just two functions: map() and reduce(). So it’s clear that data analytics has a powerful new tool with the MapReduce paradigm, which has recently surged in popularity thanks to open source solutions such as Hadoop.
In a nutshell, MapReduce provides the following benefits:
-
Programming model + infrastructure
-
The ability to write programs that run on hundreds/thousands of machines
-
Automatic parallelization and distribution
-
Fault tolerance (if a server dies, the job will be completed by other servers)
-
Program/job scheduling, status checking, and monitoring
Hadoop and Spark
Hadoop is the de facto standard for implementation of MapReduce applications. It is composed of one or more master nodes and any number of slave nodes. Hadoop simplifies distributed applications by saying that “the data center is the computer,” and by providing map() and reduce() functions (defined by the programmer) that allow application developers or programmers to utilize those data centers. Hadoop implements the MapReduce paradigm efficiently and is quite simple to learn; it is a powerful tool for processing large amounts of data in the range of terabytes and petabytes.
In this book, most of the MapReduce algorithms are presented in a cookbook format (compiled, complete, and working solutions) and implemented in Java/MapReduce/Hadoop and/or Java/Spark/Hadoop. Both the Hadoop and Spark frameworks are open source and enable us to perform a huge volume of computations and data processing in distributed environments.
These frameworks enable scaling by providing “scale-out” methodology. They can be set up to run intensive computations in the MapReduce paradigm on thousands of servers. Spark’s API has a higher-level abstraction than Hadoop’s API; for this reason, we are able to express Spark solutions in a single Java driver class.
Hadoop and Spark are two different distributed software frameworks. Hadoop is a MapReduce framework on which you may run jobs supporting the map(), combine(), and reduce() functions. The MapReduce paradigm works well at one-pass computation (first map(), then reduce()), but is inefficient for multipass algorithms. Spark is not a MapReduce framework, but can be easily used to support a MapReduce framework’s functionality; it has the proper API to handle map() and reduce() functionality. Spark is not tied to a map phase and then a reduce phase. A Spark job can be an arbitrary DAG (directed acyclic graph) of map and/or reduce/shuffle phases. Spark programs may run with or without Hadoop, and Spark may use HDFS (Hadoop Distributed File System) or other persistent storage for input/output. In a nutshell, for a given Spark program or job, the Spark engine creates a DAG of task stages to be performed on the cluster, while Hadoop/MapReduce, on the other hand, creates a DAG with two predefined stages, map and reduce. Note that DAGs created by Spark can contain any number of stages. This allows most Spark jobs to complete faster than they would in Hadoop/MapReduce, with simple jobs completing after just one stage and more complex tasks completing in a single run of many stages, rather than having to be split into multiple jobs. As mentioned, Spark’s API is a higher-level abstraction than MapReduce/Hadoop. For example, a few lines of code in Spark might be equivalent to 30–40 lines of code in MapReduce/Hadoop.
Even though frameworks such as Hadoop and Spark are built on a “shared-nothing” paradigm, they do support sharing immutable data structures among all cluster nodes. In Hadoop, you may pass these values to mappers and reducers via Hadoop’s Configuration object; in Spark, you may share data structures among mappers and reducers by using Broadcast objects. In addition to Broadcast read-only objects, Spark supports write-only accumulators. Hadoop and Spark provide the following benefits for big data processing:
- Reliability
- Hadoop and Spark are fault-tolerant (any node can go down without losing the result of the desired computation).
- Scalability
- Hadoop and Spark support large clusters of servers.
- Distributed processing
- In Spark and Hadoop, input data and processing are distributed (they support big data from the ground up).
- Parallelism
- Computations are executed on a cluster of nodes in parallel.
Hadoop is designed mainly for batch processing, while with enough memory/RAM, Spark may be used for near real-time processing. To understand basic usage of Spark RDDs (resilient distributed data sets), see Appendix B.
So what are the core components of MapReduce/Hadoop?
-
Input/output data consists of key-value pairs. Typically, keys are integers, longs, and strings, while values can be almost any data type (string, integer, long, sentence, special-format data, etc.).
-
Data is partitioned over commodity nodes, filling racks in a data center.
-
The software handles failures, restarts, and other interruptions. Known as fault tolerance, this is an important feature of Hadoop.
Hadoop and Spark provide more than map() and reduce() functionality: they provide plug-in model for custom record reading, secondary data sorting, and much more.
A high-level view of the relationship between Spark, YARN, and Hadoop’s HDFS is illustrated in Figure P-2.

Figure P-2. Relationship between MapReduce, Spark, and HDFS
This relationship shows that there are many ways to run MapReduce and Spark using HDFS (and non-HDFS filesystems). In this book, I will use the following keywords and terminology:
-
MapReduce refers to the general MapReduce framework paradigm.
-
MapReduce/Hadoop refers to a specific implementation of the MapReduce framework using Hadoop.
-
Spark refers to a specific implementation of Spark using HDFS as a persistent storage or a compute engine (note that Spark can run against any data store, but here we focus mostly on Hadoop’s):
-
Spark can run without Hadoop using standalone cluster mode (which may use HDFS, NFS, or another medium as a persistent data store).
-
Spark can run with Hadoop using Hadoop’s YARN or MapReduce framework.
-
Using this book, you will learn step by step the algorithms and tools you need to build MapReduce applications with Hadoop. MapReduce/Hadoop has become the programming model of choice for processing large data sets (such as log data, genome sequences, statistical applications, and social graphs). MapReduce can be used for any application that does not require tightly coupled parallel processing. Keep in mind that Hadoop is designed for MapReduce batch processing and is not an ideal solution for real-time processing. Do not expect to get your answers from Hadoop in 2 to 5 seconds; the smallest jobs might take 20+ seconds. Spark is a top-level Apache project that is well suited for near real-time processing, and will perform better with more RAM. With Spark, it is very possible to run a job (such as biomarker analysis or Cox regression) that processes 200 million records in 25 to 35 seconds by just using a cluster of 100 nodes. Typically, Hadoop jobs have a latency of 15 to 20 seconds, but this depends on the size and configuration of the Hadoop cluster.
An implementation of MapReduce (such as Hadoop) runs on a large cluster of commodity machines and is highly scalable. For example, a typical MapReduce computation processes many petabytes or terabytes of data on hundreds or thousands of machines. Programmers find MapReduce easy to use because it hides the messy details of parallelization, fault tolerance, data distribution, and load balancing, letting the programmers focus on writing the two key functions, map() and reduce().
The following are some of the major applications of MapReduce/Hadoop/Spark:
-
Query log processing
-
Crawling, indexing, and search
-
Analytics, text processing, and sentiment analysis
-
Machine learning (such as Markov chains and the Naive Bayes classifier)
-
Recommendation systems
-
Document clustering and classification
-
Bioinformatics (alignment, recalibration, germline ingestion, and DNA/RNA sequencing)
-
Genome analysis (biomarker analysis, and regression algorithms such as linear and Cox)
What Is in This Book?
Each chapter of this book presents a problem and solves it through a set of MapReduce algorithms. MapReduce algorithms/solutions are complete recipes (including the MapReduce driver, mapper, combiner, and reducer programs). You can use the code directly in your projects (although sometimes you may need to cut and paste the sections you need). This book does not cover the theory behind the MapReduce framework, but rather offers practical algorithms and examples using MapReduce/Hadoop and Spark to solve tough big data problems. Topics covered include:
-
Market Basket Analysis for a large set of transactions
-
Data mining algorithms (K-Means, kNN, and Naive Bayes)
-
DNA sequencing and RNA sequencing using huge genomic data
-
Naive Bayes classification and Markov chains for data and market prediction
-
Recommendation algorithms and pairwise document similarity
-
Linear regression, Cox regression, and Pearson correlation
-
Allelic frequency and mining DNA
-
Social network analysis (recommendation systems, counting triangles, sentiment analysis)
You may cut and paste the provided solutions from this book to build your own MapReduce applications and solutions using Hadoop and Spark. All the solutions have been compiled and tested. This book is ideal for anyone who knows some Java (i.e., can read and write basic Java programs) and wants to write and deploy MapReduce algorithms using Java/Hadoop/Spark. The general topic of MapReduce has been discussed in detail in an excellent book by Jimmy Lin and Chris Dyer[16]; again, the goal of this book is to provide concrete MapReduce algorithms and solutions using Hadoop and Spark. Likewise, this book will not discuss Hadoop itself in detail; Tom White’s excellent book[31] does that very well.
This book will not cover how to install Hadoop or Spark; I am going to assume you already have these installed. Also, any Hadoop commands are executed relative to the directory where Hadoop is installed (the $HADOOP_HOME environment variable). This book is explicitly about presenting distributed algorithms using MapReduce/Hadoop and Spark. For example, I discuss APIs, cover command-line invocations for running jobs, and provide complete working programs (including the driver, mapper, combiner, and reducer).
What Is the Focus of This Book?
The focus of this book is to embrace the MapReduce paradigm and provide concrete problems that can be solved using MapReduce/Hadoop algorithms. For each problem presented, we will detail the map(), combine(), and reduce() functions and provide a complete solution, which has:
-
A client, which calls the driver with proper input and output parameters.
-
A driver, which identifies
map()andreduce()functions, and identifies input and output. -
A mapper class, which implements the
map()function. -
A combiner class (when possible), which implements the
combine()function. We will discuss when it is possible to use a combiner. -
A reducer class, which implements the
reduce()function.
One goal of this book is to provide step-by-step instructions for using Spark and Hadoop as a solution for MapReduce algorithms. Another is to show how an output of one MapReduce job can be used as an input to another (this is called chaining or pipelining MapReduce jobs).
Who Is This Book For?
This book is for software engineers, software architects, data scientists, and application developers who know the basics of Java and want to develop MapReduce algorithms (in data mining, machine learning, bioinformatics, genomics, and statistics) and solutions using Hadoop and Spark. As I’ve noted, I assume you know the basics of the Java programming language (e.g., writing a class, defining a new class from an existing class, and using basic control structures such as the while loop and if-then-else).
More specifically, this book is targeted to the following readers:
-
Data science engineers and professionals who want to do analytics (classification, regression algorithms) on big data. The book shows the basic steps, in the format of a cookbook, to apply classification and regression algorithms using big data. The book details the
map()andreduce()functions by demonstrating how they are applied to real data, and shows where to apply basic design patterns to solve MapReduce problems. These MapReduce algorithms can be easily adapted across professions with some minor changes (for example, by changing the input format). All solutions have been implemented in Apache Hadoop/Spark so that these examples can be adapted in real-world situations. -
Software engineers and software architects who want to design machine learning algorithms such as Naive Bayes and Markov chain algorithms. The book shows how to build the model and then apply it to a new data set using MapReduce design patterns.
-
Software engineers and software architects who want to use data mining algorithms (such as K-Means clustering and k-Nearest Neighbors) with MapReduce. Detailed examples are given to guide professionals in implementing similar algorithms.
-
Data science engineers who want to apply MapReduce algorithms to clinical and biological data (such as DNA sequencing and RNA sequencing). This book clearly explains practical algorithms suitable for bioinformaticians and clinicians. It presents the most relevant regression/analytical algorithms used for different biological data types. The majority of these algorithms have been deployed in real-world production systems.
-
Software architects who want to apply the most important optimizations in a MapReduce/distributed environment.
This book assumes you have a basic understanding of Java and Hadoop’s HDFS. If you need to become familiar with Hadoop and Spark, the following books will offer you the background information you will need:
-
Hadoop: The Definitive Guide by Tom White (O’Reilly)
-
Hadoop in Action by Chuck Lam (Manning Publications)
-
Hadoop in Practice by Alex Holmes (Manning Publications)
-
Learning Spark by Holden Karau, Andy Konwinski, Patrick Wendell, and Matei Zaharia (O’Reilly)
Online Resources
Two websites accompany this book:
- https://github.com/mahmoudparsian/data-algorithms-book/
At this GitHub site, you will find links to the source code (organized by chapter), shell scripts (for running MapReduce/Hadoop and Spark programs), sample input files for testing, and some extra content that isn’t in the book, including a couple of bonus chapters.
- http://mapreduce4hackers.com
At this site, you will find links to extra source files (not mentioned in the book) plus some additional content that is not in the book. Expect more coverage of MapReduce/Hadoop/Spark topics in the future.
What Software Is Used in This Book?
When developing solutions and examples for this book, I used the software and programming environments listed in Table P-3.
| Software | Version |
|---|---|
| Java programming language (JDK7) | 1.7.0_67 |
| Operating system: Linux CentOS | 6.3 |
| Operating system: Mac OS X | 10.9 |
| Apache Hadoop | 2.5.0, 2.6.0 |
| Apache Spark | 1.1.0, 1.3.0, 1.4.0 |
| Eclipse IDE | Luna |
All programs in this book were tested with Java/JDK7, Hadoop 2.5.0, and Spark (1.1.0, 1.3.0, 1.4.0). Examples are given in mixed operating system environments (Linux and OS X). For all examples and solutions, I engaged basic text editors (such as vi, vim, and TextWrangler) and compiled them using the Java command-line compiler (javac).
In this book, shell scripts (such as bash scripts) are used to run sample MapReduce/Hadoop and Spark programs. Lines that begin with a $ or # character indicate that the commands must be entered at a terminal prompt (such as bash).
Conventions Used in This Book
The following typographical conventions are used in this book:
- Italic
-
Indicates new terms, URLs, email addresses, filenames, and file extensions.
Constant width-
Used for program listings, as well as within paragraphs to refer to program elements such as variable or function names, databases, data types, environment variables, statements, and keywords.
Note
This element signifies a general note.
Using Code Examples
As mentioned previously, supplemental material (code examples, exercises, etc.) is available for download at https://github.com/mahmoudparsian/data-algorithms-book/ and http://www.mapreduce4hackers.com.
This book is here to help you get your job done. In general, if example code is offered with this book, you may use it in your programs and documentation. You do not need to contact us for permission unless you’re reproducing a significant portion of the code. For example, writing a program that uses several chunks of code from this book does not require permission. Selling or distributing a CD-ROM of examples from O’Reilly books does require permission. Answering a question by citing this book and quoting example code does not require permission. Incorporating a significant amount of example code from this book into your product’s documentation does require permission.
We appreciate, but do not require, attribution. An attribution usually includes the title, author, publisher, and ISBN. For example: “Data Algorithms by Mahmoud Parsian (O’Reilly). Copyright 2015 Mahmoud Parsian, 978-1-491-90618-7.”
If you feel your use of code examples falls outside fair use or the permission given above, feel free to contact us at permissions@oreilly.com.
Safari® Books Online
Safari Books Online is an on-demand digital library that delivers expert content in both book and video form from the world’s leading authors in technology and business.
Technology professionals, software developers, web designers, and business and creative professionals use Safari Books Online as their primary resource for research, problem solving, learning, and certification training.
Safari Books Online offers a range of plans and pricing for enterprise, government, education, and individuals.
Members have access to thousands of books, training videos, and prepublication manuscripts in one fully searchable database from publishers like O’Reilly Media, Prentice Hall Professional, Addison-Wesley Professional, Microsoft Press, Sams, Que, Peachpit Press, Focal Press, Cisco Press, John Wiley & Sons, Syngress, Morgan Kaufmann, IBM Redbooks, Packt, Adobe Press, FT Press, Apress, Manning, New Riders, McGraw-Hill, Jones & Bartlett, Course Technology, and hundreds more. For more information about Safari Books Online, please visit us online.
How to Contact Us
Please address comments and questions concerning this book to the publisher:
- O’Reilly Media, Inc.
- 1005 Gravenstein Highway North
- Sebastopol, CA 95472
- 800-998-9938 (in the United States or Canada)
- 707-829-0515 (international or local)
- 707-829-0104 (fax)
We have a web page for this book, where we list errata, examples, and any additional information. You can access this page at http://bit.ly/data_algorithms.
To comment or ask technical questions about this book, send email to bookquestions@oreilly.com.
For more information about our books, courses, conferences, and news, see our website at http://www.oreilly.com.
Find us on Facebook: http://facebook.com/oreilly
Follow us on Twitter: http://twitter.com/oreillymedia
Watch us on YouTube: http://www.youtube.com/oreillymedia
Acknowledgments
To each reader: a big thank you for reading my book. I hope that this book is useful and serves you well.
Thank you to my editor at O’Reilly, Ann Spencer, for believing in my book project, supporting me in reorganizing the chapters, and suggesting a new title (originally, I proposed a title of MapReduce for Hackers). Also, I want to thank Mike Loukides (VP of Content Strategy for O’Reilly Media) for believing in and supporting my book project.
Thank you so much to my editor, Marie Beaugureau, data and development editor at O’Reilly, who has worked with me patiently for a long time and supported me during every phase of this project. Marie’s comments and suggestions have been very useful and helpful.
A big thank you to Rachel Monaghan, copyeditor, for her superb knowledge of book editing and her valuable comments and suggestions. This book is more readable because of her. Also, I want to say a big thank you to Matthew Hacker, production editor, who has done a great job in getting this book through production. Thanks to Rebecca Demarest (O’Reilly’s illustrator) and Dan Fauxsmith (Director of Publishing Services for O’Reilly) for polishing the artwork. Also, I want to say thank you to Rachel Head (as proofreader), Judith McConville (as indexer), David Futato (as interior designer), and Ellie Volckhausen (as cover designer).
Thanks to my technical reviewers, Cody Koeninger, Kun Lu, Neera Vats, Dr. Phanendra Babu, Willy Bruns, and Mohan Reddy. Your comments were useful, and I have incorporated your suggestions as much as possible. Special thanks to Cody for providing detailed feedback.
A big thank you to Jay Flatley (CEO of Illumina), who has provided a tremendous opportunity and environment in which to unlock the power of the genome. Thank you to my dear friends Saeid Akhtari (CEO, NextBio) and Dr. Satnam Alag (VP of Engineering at Illumina) for believing in me and supporting me for the past five years.
Thanks to my longtime dear friend, Dr. Ramachandran Krishnaswamy (my Ph.D. advisor), for his excellent guidance and for providing me with the environment to work on computer science.
Thanks to my dear parents (mother Monireh Azemoun and father Bagher Parsian) for making education their number one priority. They have supported me tremendously. Thanks to my brother, Dr. Ahmad Parsian, for helping me to understand mathematics. Thanks to my sister, Nayer Azam Parsian, for helping me to understand compassion.
Last, but not least, thanks to my dear family—Behnaz, Maral, and Yaseen—whose encouragement and support throughout the writing process means more than I can say.
Comments and Questions for This Book
I am always interested in your feedback and comments regarding the problems and solutions described in this book. Please email comments and questions for this book to mahmoud.parsian@yahoo.com. You can also find me at http://www.mapreduce4hackers.com.
Get Data Algorithms now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

