Chapter 12
k-Centers clustering
12.1 Introduction
The clustering task was presented in Section 1.5 as the combination of cluster formation, which identifies similarity-based groups in the training set, and cluster modeling, which creates a model for cluster membership prediction. Dissimilarity-based clustering algorithms address both of these subtasks using measures of instance dissimilarity or similarity. The family of ![]() -centers clustering algorithms represents not only the conceptually simplest but also the most popular approach to dissimilarity-based clustering. Of all algorithms using explicit similarity or dissimilarity measures,
-centers clustering algorithms represents not only the conceptually simplest but also the most popular approach to dissimilarity-based clustering. Of all algorithms using explicit similarity or dissimilarity measures, ![]() -centers algorithms employ these measures in the most direct and straightforward way to determine cluster membership.
-centers algorithms employ these measures in the most direct and straightforward way to determine cluster membership.
12.1.1 Basic principle
Algorithms from the ![]() -centers family share the same basic operation principle that can be outlined as follows:
-centers family share the same basic operation principle that can be outlined as follows:
- 1. the number of clusters is predetermined and referred to as
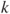 (hence the “
(hence the “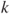 -” in algorithm names),
-” in algorithm names),
Get Data Mining Algorithms: Explained Using R now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

