April 2015
Beginner
328 pages
7h 18m
English
A lot of people say there’s a fine line between genius and insanity. I don’t think there’s a fine line, I actually think there’s a yawning gulf.
Bill Bailey
In Chapter 1, we briefly looked at the problem of trying to predict which DataSciencester users paid for premium accounts. Here we’ll revisit that problem.
We have an anonymized data set of about 200 users, containing each user’s salary, her years of experience as a data scientist, and whether she paid for a premium account (Figure 16-1). As is usual with categorical variables, we represent the dependent variable as either 0 (no premium account) or 1 (premium account).
As usual, our data is in a matrix where each row is a list
[experience, salary, paid_account]. Let’s turn it into the format we need:
x=[[1]+row[:2]forrowindata]# each element is [1, experience, salary]y=[row[2]forrowindata]# each element is paid_account
An obvious first attempt is to use linear regression and find the best model:
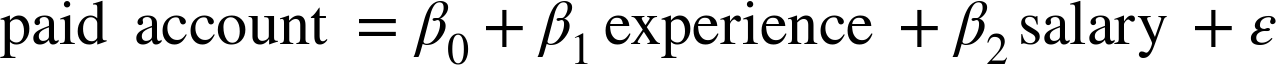
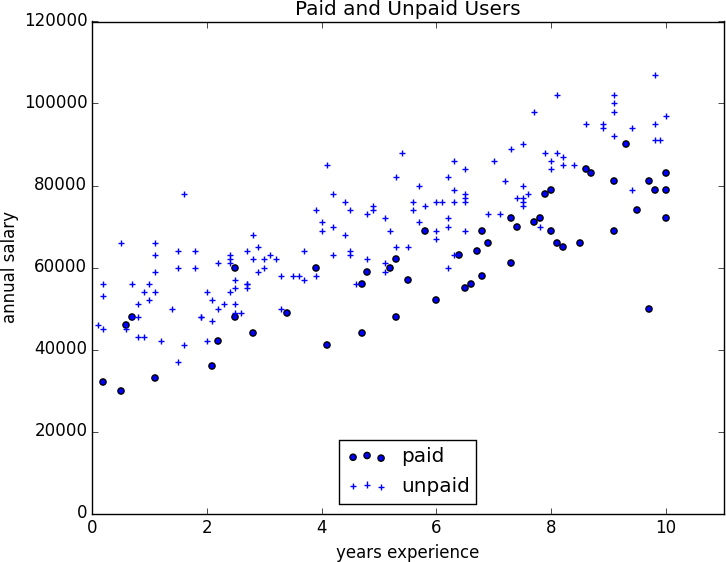
And certainly, there’s nothing preventing us from modeling the problem this way. The results are shown in Figure 16-2:
rescaled_x=rescale(x)beta=estimate_beta(rescaled_x,y)# [0.26, 0.43, -0.43]predictions=[predict(x_i,beta ...
Read now
Unlock full access






