Chapter 9. Hash Tables, Maps, and Skip Lists
Contents
9.1 Maps | 368 |
9.1.1 The Map ADT | 369 |
9.1.2 A C++ Map Interface | 371 |
9.1.3 The STL map Class | 372 |
9.1.4 A Simple List-Based Map Implementation | 374 |
9.2 Hash Tables | 375 |
9.2.1 Bucket Arrays | 375 |
9.2.2 Hash Functions | 376 |
9.2.3 Hash Codes | 376 |
9.2.4 Compression Functions | 380 |
9.2.5 Collision-Handling Schemes | 382 |
9.2.6 Load Factors and Rehashing | 386 |
9.2.7 A C++ Hash Table Implementation | 387 |
9.3 Ordered Maps | 394 |
9.3.1 Ordered Search Tables and Binary Search | 395 |
9.3.2 Two Applications of Ordered Maps | 399 |
9.4 Skip Lists | 402 |
9.4.1 Search and Update Operations in a Skip List | 404 |
9.4.2 A Probabilistic Analysis of Skip Lists * | 408 |
9.5 Dictionaries | 411 |
9.5.1 The Dictionary ADT | 411 |
9.5.2 A C++ Dictionary Implementation | 413 |
9.5.3 Implementations with Location-Aware Entries | 415 |
9.6 Exercises | 417 |
Maps
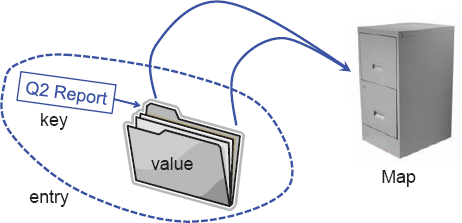
Figure 9.1. A conceptual illustration of the map ADT. Keys (labels) are assigned to values (folders) by a user. The resulting entries (labeled folders) are inserted into the map (file cabinet). The keys can be used later to retrieve or remove values.
A map allows us to store elements so they can be located quickly using keys. The motivation for such searches is that each element typically stores additional useful information besides its search key, but the only way to get at that information is to use the search ...
Get Data Structures and Algorithms in C++, Second Edition now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

