While training these sets of RNN-type architectures, we use gradient descent and backprogagation through time, which introduced some successes for lots of sequence-based learning tasks. But because of the nature of the gradient and due to using fast training strategies, it could be shown that the gradient values will tend to be too small and vanish. This process introduced the vanishing gradient problem that many practitioners fall into. Later on in this chapter, we will discuss how researchers approached these kind of problems and produced variations of the vanilla RNNs to overcome this problem:
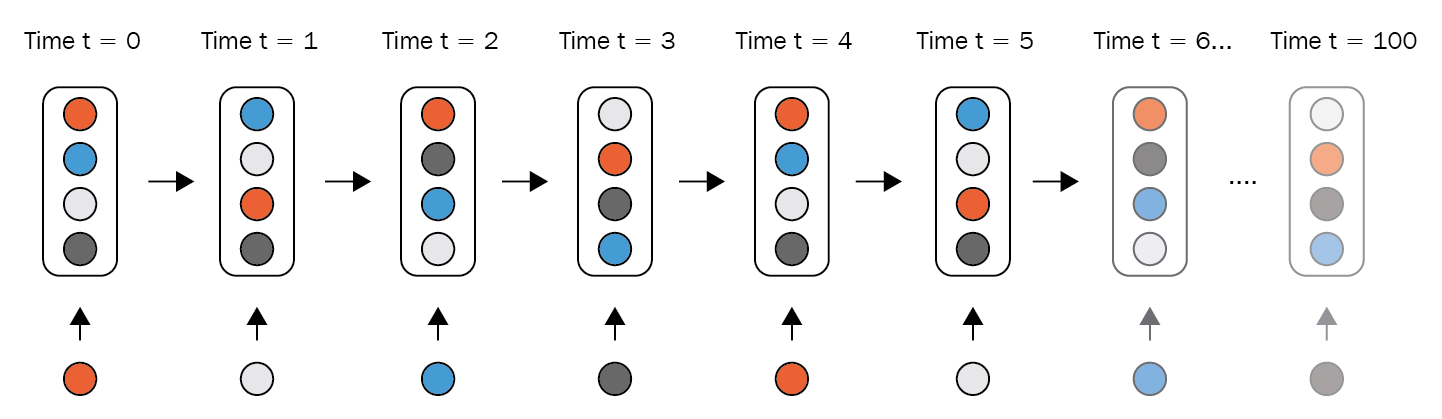
Figure 5: Vanishing ...

