February 2018
Intermediate to advanced
262 pages
6h 59m
English
In most of the deep learning algorithms we have seen for computer vision models, we either pick up a convolution layer with a filter size of 1 x 1, 3 x 3, 5 x 5, 7 x 7, or a map pooling layer. The Inception module combines convolutions of different filter sizes and concatenates all the outputs together. The following image makes the Inception model clearer:
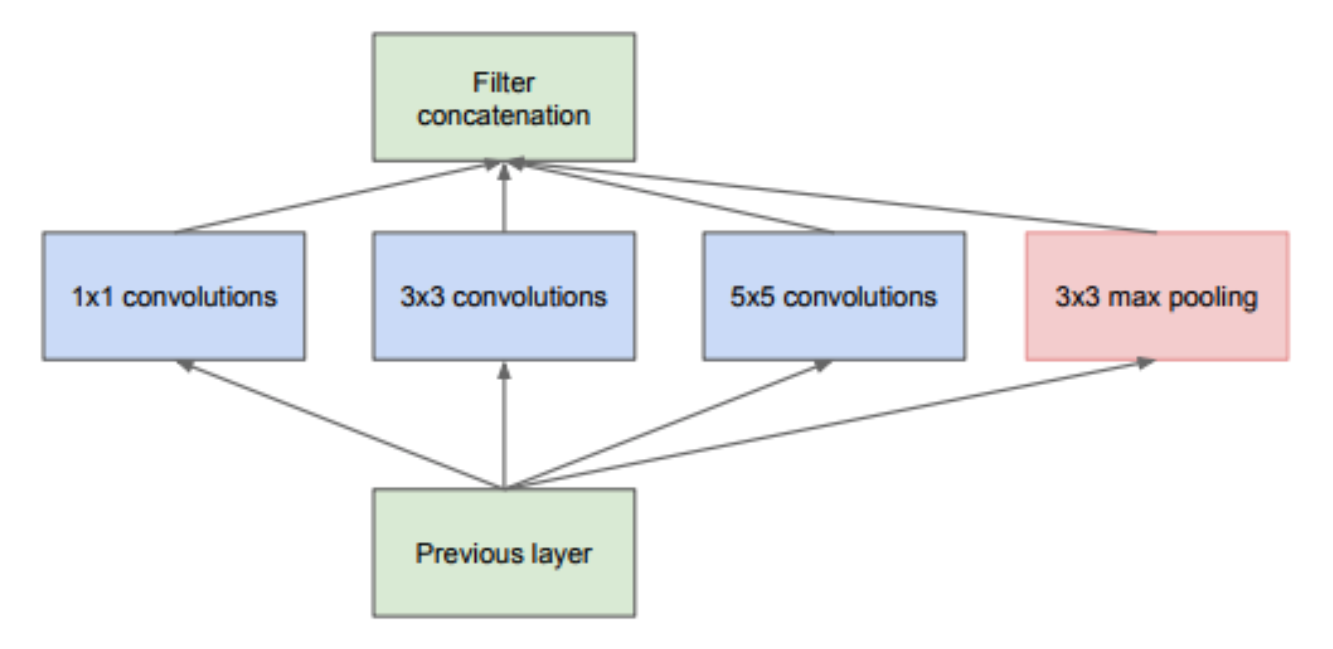
In this Inception block image, the convolution of different sizes is applied to the input, and the outputs of all these layers are concatenated. This is the simplest version of an Inception module. There is another variant of an ...
Read now
Unlock full access






