Chapter 2. Big Data: The Ultimate Computing Platform
Introduction to Platforms
A platform is a collection of sub-systems or components that must operate like one thing. A Formula One racing vehicle (which drivers refer to as their platform) is the automobile equivalent of a supercomputer. It has every aspect of its design fully optimized not simply for performance, but performance per liter of gas or kilogram of curb weight. A 2-litre engine that creates 320HP instead of 140HP does so because it is more efficient.
The engine with higher horsepower does have better absolute performance, but performance really means efficiency—like HP/KG and miles/gallon, or with computing platforms, jobs executed/watt. Performance is always measured as a ratio of something being accomplished for the effort expended.
The descendant of Honda’s F1 technology is now found in other cars because optimized technology derived from the racing program enabled Honda to design more powerful vehicles for consumers.
A Honda Civic is just as much a platform as the F1. The engine, brakes, steering, and suspension are designed so it feels like you’re driving a car, not a collection of complex sub-components. Platforms can span rivers, serve ads for shoes, and reserve seats on another notable platform—the kind with wings.
Come Fly with Me
The design and development of a new commercial aircraft is complex, costly, and tangled in regulations, making the process justifiably slow since design flaws can leave bodies scattered across the infield.
Platforms that must be manufactured out of physical components require more planning than platforms that are manufactured out of nothing—such as software—because a new set of engines can’t be downloaded every week.
However, modern aircraft designers understand the value of that flexible software stuff. First introduced in military fighters, “fly-by-wire” technology refers to flying by electrical wire, not mechanical wire (like bicycle brake cables).
In traditional aircraft, the stick and pedals were mechanically connected to the control surfaces on the wings, so mechanical linkages controlled those surfaces. In a fly-by-wire aircraft, the controls in the cockpit are inputs to a computer, which controls motorized actuators that move the surfaces on the wings and tail.
Fly-by-wire software is also used to prevent fighter pilots from flying into unconsciousness. Pilots can bank into turns so steep that they could black out, but software detects those conditions and limits turns to keep pilots conscious and alive.
Similar features apply to commercial aircraft and sport sedans, making those platforms safer and more efficient. Unfortunately, if the fly-by-wire software (which is very easy to change and “improve”) has bugs or design flaws, this can still result in that mess on the infield that they prefer to avoid.
Computing Platforms
In the 1960s, Bank of America and IBM built one of the first credit card processing systems. Although those early mainframes processed just a fraction of the data compared to that of eBay or Amazon, the engineering was complex for the day. Once credit cards became popular, processing systems had to be built to handle the load and, more importantly, handle the growth without constant re-engineering.
These early platforms were built around mainframes, peripheral equipment (networks and storage), and software, all from a single vendor.
IBM also built a massive database system as a one-off project for NASA during the Apollo program, which later evolved into a product called IMS. Because IBM developed these solutions to specific problems that large customers faced, the resulting systems were not products yet. They were custom-built, highly integrated, and very expensive platforms, which would later evolve into a viable business for IBM.
These solutions, with all their interconnected hardware and software components, were built as a single system, usually by a small, dedicated team of specialists. Small teams cross-pollinated their expertise so an expert in storage, networks, or databases acquired enough general, working knowledge in other areas.
These solutions often required development of new hardware and software technologies, so prolonged cross-pollination of expertise was critical to the success of the project. Team members’ close proximity allowed a body of working knowledge to emerge that was critical to the success of the platform. Each team’s job was not complete until they delivered a finished, integrated working platform to the customer as a fully functional solution to the business problem.
The End of an Era
In the 1970s, IBM’s monopoly was curtailed enough for other startups such as Amdahl, DEC, and Oracle to emerge and begin providing IBM customers with alternatives. DEC built minicomputers that provided superior price/performance to IBM mainframes, but without compatibility. Amdahl (whose namesake, Gene, designed the IBM 390) provided a compatible alternative that was cheaper than an IBM mainframe. Companies could develop and sell their own products or services and thrive in the post-monopoly world.
These pockets of alternative value eventually led to silos of vendors and silos of expertise within IT departments that were aligned with the vendors. Like Amdahl, Oracle directly benefited from technology that IBM developed but never productized. Larry Ellison’s genius was to take IBM’s relational database technology and place it on the seminal VAX and create one of the first enterprise software companies in the post-mainframe era.
When products within silos or niches were sold to customers, putting the system together was no longer any single supplier’s responsibility; it became the customers’ job.
Today there are so many vendors for every imaginable silo—network switches, storage switches, storage arrays, servers, operating systems, databases, language compilers, applications—and all the complication and cost that comes with the responsibility.

Big systems integrators like Accenture and Wipro attempt to fill this gap, but they also operate within the constraints of IT departments and the same organizational silos established by vendors.
Silos are the price paid for the post-mainframe alternatives to IBM. Silos obfuscate the true nature of computing platforms as a single system of interconnected hardware and software.
Back to the Future
Oracle profited from being a post-mainframe silo for decades as customers bought their database technology and ran it on Sun, HP, and EMC hardware. As applications became more complex, constructing platforms with silos became even more difficult, and enterprises attempting to use Oracle’s clustering technology, RAC, found it nearly impossible to set up.
Since this failure could be a result of their customers’ own poor platform engineering (which exposed more bugs), Oracle designed an engineered platform that combined all the components and product engineering expertise, which made successful experiences possible.
The resulting product, Exadata, was originally designed for the data warehouse market, but found more success with mainstream Oracle RAC customers running applications like SAP.
Since Oracle was not a hardware company, the initial release of Exadata was based on HP hardware, but Exadata was successful enough that Oracle decided to source the hardware components themselves, which partially motivated their acquisition of Sun. By sourcing all the hardware and software components in Exadata, Oracle resurrected the one-stop shop mainframe model.
This one-stop shop model is also known as “one throat to choke.” On its surface, it sounds appealing, but it assumes the throat can be choked. Large customers such as Amgen, Citibank, and AT&T purchase so much equipment and services that they can choke any vendor they like when things go south.
However, for the vast majority of customers, because they are too large to manage their own databases without support from Oracle and too small to demand good or timely support from Oracle, one-stop shopping often reduces customers’ leverage with vendors.
Like Exadata, big data supercomputers need to be constructed as engineered platforms, and this construction requires an engineering approach where all the hardware and software components are treated as a single system. That’s the platform way—the way it was before these components were sold by silos of vendors.
High Divers and Fire Fighters
Today, architects who would be responsible for building these new platforms are mostly found in their respective IT departments where they work as subject matter experts in their particular silo. Yet platform architects, like building architects, must have an extensive working knowledge of the entire platform, including the computer science bits, the physical plant aspects, and the business value of the entire platform.
Because any component of the platform can be triaged, repaired, or optimized, platform architects must be well-versed enough to carry on a conversation with data center electricians, network designers, Linux or Java programmers, UI designers, and business owners and controllers.
Platform architects must be able and agile enough to dive into the details deep-end with the electrician, and then climb out to dive into another pool full of accountants. Too much knowledge or over-familiarity with details in one area can distort the overall platform perspective. Having the ability to selectively filter out details is required because details come in all shapes and sizes and their relative importance constantly shifts.
The cliché “the devil is in the details” is not quite accurate; the devil is usually in a handful of a zillion details and that handful may change daily. Prioritizing the important details and ignoring irrelevant details is one of the most important skills a platform architect can possess.
Designing systems as platforms is a craft not taught, so those who do pick it up stumble on it by accident, necessity, or desperation. This adventure rarely comes with help or encouragement from coworkers, employers, or vendors. It is a thankless learning process that can easily alienate colleagues in other groups because it appears that platform architects are trying to do everybody else’s job for them.
The truth is that platform architects are trying to a job nobody knows how to do or is willing to do. As a result, most practitioners do not work within IT organizations, but freelance around the rough edges where things don’t work or scale or recover.
Freelance platform architects are typically hired to triage problems that have customers at their wit’s end. Once fires have been put out, there is a narrow window of opportunity to educate customers about their own platform.
I’ll Take Silos for $1000, Alex
One of the surprises awaiting enterprises is that big data is DIY supercomputing. Whatever big data cluster they stand up, it comes from the factory without applications or data. In order to populate the cluster, data must be emancipated from their own technical and organizational silos.
Big data matters because of the business value it promises. Data scientists and data wranglers will need to develop new methods to analyze both the legacy data and the vast amounts of new data flooding in.
Both Development and Operations will be responsible for the success of an enterprise’s big data initiative. The walls between the business, data, organizations, and platform cannot exist at global scale.
Similar to your nervous system, a big data cluster is a highly interconnected platform built from a collection of commodity parts. Neurons in the human brain are the building blocks of the nervous system, but are very simple parts. The neurons in a jellyfish are also made from these very simple parts.
Just like you are far more than the sum of your jellyfish parts (your brilliant personality being the nervous system’s ultimate big data job), a big data cluster operates as a complex, interconnected form of computing intelligence—almost human, almost Watson.
Engineering Big Data Platforms
Big data platforms must operate and process data at a scale that leaves little room for error. Like a Boeing 737, big data clusters must be built for speed, scale, and efficiency. Many enterprises venturing into big data don’t have experience building and operating supercomputers, but many are now faced with that prospect. Platform awareness will increase their chances of success with big data.
Legacy silos—whether they’re infrastructure, organizational, or vendor silos—must be replaced with a platform-centric perspective. In the past, enterprises and agencies were satisfied with purchasing a SQL prompt and building their own applications.
Today, those groups don’t want to read raw data science output; they need to visualize it or they can’t derive the business value they’re looking for. They need pictures, not numbers.
Unlike the legacy infrastructure stack, silos can’t exist in the data visualization stack. Implemented successfully, big data infrastructure delivers the data to the right place (the analytics layer) at the right time for the right cost.
If the infrastructure can aggregate a richer set of data such as tweets, videos, PDFs, JPGs, and SQL, then the analytics layer has a better chance of delivering actionable intelligence for the business.
The Art and Craft of Platform Engineering at Global Scale
Platform engineering can be a great, yet hair-raising, adventure. In order to build a platform you have never built before and to discover things that your business never thought to look for, it will take a lot of lab work and many experiments that need to fail early and often to make sure the platform will deliver at scale.
Many enterprise IT departments and their corresponding vendor silos continue to impair platform awareness. Many customers struggle with big data because they want to apply enterprise-grade practices to global-scale problems.
Disaster recovery (DR) is a good example of how the silo perspective rarely produces a strategy that effectively and efficiently recovers a platform. Building a silo-centric DR plan forces precise coordination across every single silo, which is organizationally complex and expensive.
Usually when the Storage group implements DR strategies, they only do it for storage and when the Application Server team implements DR, it’s limited to their application servers. Although many companies get by with a silo approach to enterprise-scale disaster recovery, it’s rarely optimal. At global scale, it doesn’t work at all.
Thinking about computing systems in a holistic, organic, and integrative way may be considered crazy or not worth the bother; especially when many systems built within organizations seem to operate successfully as silos, just not at peak performance or efficiency.
The silo approach achieves operational economies of scale because that is what is being measured. Measuring a platform’s efficiency might be almost as hard as building an efficient platform in the first place.
Although the tenets of platform engineering apply to both enterprise- and global-scale computing, the difference is that at enterprise scale, the mantras are optional. At global scale, they’re mandatory. Platform engineering for big data demands three critical tenets: avoid complexity, prototype perpetually, and optimize everything.
KISS Me Kate
There are advantages to avoiding complexity at enterprise scale, but with big data, “Keep It Simple, Sunshine” are words to live by. Even a modest cluster with 20 racks, 400 nodes, and 4,800 disks contains a lot of moving parts and is a complex organism and complexity contributes to two major failure categories: software bugs and operator error.
Big data platforms must be designed to scale and continue to work in the face of failure. Because the law of averages for failures will inevitably happen, the software must provide the ability to scale and keep a 400-node cluster continuously available in the face of component failures. The software supports high availability (HA) by providing both redundancy of service through multiple pathways and self-correcting techniques that reinstates data loss due to failures.
In traditional enterprise-scale software, HA capabilities are not valued as features because HA does nothing new or improved–it just keeps things working. But in supercomputer clusters with thousands of interconnected components, HA is as important as scalability.
Historically, HA software features were designed to address hardware failures, but what happens when the HA software fails? Verifying software robustness is a difficult exercise in end-case testing that requires a ruthless and costly devotion to negative testing. And even if vendors are ruthless, the environment they use is rarely end-case identical to their customers’ environment.
No two platforms are alike unless they are built to extremely repeatable specifications. For this very reason, big data pioneers have gone to great lengths to minimize platform variance in an attempt to avoid conditions that might trigger the end-case, high-complexity software failures that are very nasty to triage.
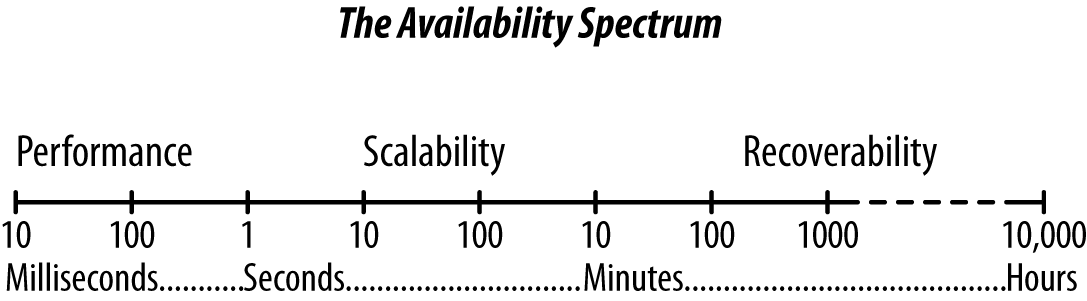
The Response Time Continuum
High availability has mostly been concerned with avoiding outages. When customers book an airline reservation, the entire platform must be available and responsive to make this possible. When parts of a platform are not available (like the reservation database), another copy of the database must be brought online so customers can continue to book flights.
Database teams pride themselves on designing disaster recovery strategies that make this continued availability possible, but if the rest of the platform isn’t designed to the same level of availability, the customer experience suffers. HA isn’t just about keeping databases or storage up and running; it’s about keeping everything up and running, from the user’s browser to the air conditioners in the datacenter.
Engineering for HA is not just about avoiding long outages—it is about any outage, even the ones that last just a few seconds. When customers are waiting for the platform to return a selection of airline flights that match their search criteria, a few seconds of unavailability in the reservation system might as well be forever, especially if their reservation is lost.
Availability is about the responsiveness of the system, so the response time continuum encompasses the seconds or minutes customers must wait for their reservation to complete as well as the hours or days it might take the system to recover from a major disaster.
The responsiveness and degree of unavailability is determined both by expectations and the perception of time. Some online systems display messages (don’t move away from this screen until your reservation is complete) or dials (working…working…working…) to manage users’ expectations of responsiveness. It might be OK with customers to wait a minute or two longer to ensure that their airline tickets are booked correctly and paid for only once, but currency traders feel that a wait of 500 milliseconds is unbearable.
Performance, scalability, and recovery have always been perceived as separate topics of platform design, but they’re all just sub-topics of availability engineering.
Perpetual Prototyping
Product development principles are a bit of a mixed bag and can sometimes backfire. Although it might be noble to preserve design principles that ensure product stability, the price paid for this is a sclerotic software product lifecycle.
Many enterprises now find themselves under such immense competitive pressure to add features to their computing plant that traditional approaches to product development might not produce better results than the old approach when IT projects were treated as projects, not products.
Rapidly evolving requirements seem to break both the one-off project approach and the bureaucratic software product lifecycle. In this new world, development, testing, and migration all begin to blur together as a single continuous activity.
In the old software development model, there were meetings to discuss the market requirements, and then more meetings to discuss and negotiate the product requirements that would eventually appear in the next release. Finally, the actual development of new features could take years.
By the time the features appeared using the old method, competitors using the new approach would have released several versions that were more capable and less stable in the short run, but more capable and stable far faster than with the old model.
A long product development cycle can result in an expensive, late, or uncompetitive product. It also can lead to company failure. The traditional process is simply not responsive enough for big data.
Because adding features quickly can destabilize any software system, achieving equilibrium between innovation and stability is important. To shift to a higher rate of release and still provide features that are stable, many organizations that work at massive scale develop their products using an approach called perpetual prototyping (PP), which blurs together the formerly discrete steps of prototyping, development, testing, and release into a continuous loop. The features are created and delivered so quickly that the released product (or big data platform) is a highly functional prototype.
Companies using a PP style of development have pushed testing and integration phases into sections of their production environment. Their production environments (aka colos) are so vast that it is more cost effective to use a small slice of users spread across the entire set of colos than it is to construct a separate test colo.
This users-as-guinea-pigs model can obviously have negative effects on any users who are subjected to untested code, but the simulation is extremely realistic, and steps are taken to make sure the new features are not so broken that it creates havoc.
The open source world has strategies that are similar to PP, where early versions of code are pushed out to users with “tech preview” status. In addition to branches that barely compile, as well as more stable production versions, tech preview operates like warning labels: “It should work as advertised; if it doesn’t, give us a shout” or “This code might even be production-ready, but it’s had limited exposure to production environments.”
Relative to traditional methods, open source development also trades rapid evolution (feature time to market) for stability. In early stages of development, the product improves quickly, but with quality sometimes going sideways more often than in a traditional closed-source model.
As products or projects stabilize and fewer features are added, developers lose interest and work on the next shiny bright thing and the rate of change drops off. Even open source products eventually stop changing or become stable enough that the loss of these developers is really a sign of maturity.
Epic Fail Insurance
Design doctrines for enterprise-grade platforms are based on established principles that make sense for critical enterprise-scale computing systems, such as payroll. To be considered enterprise-grade, many people think big data must embrace enterprise-scale doctrines. But enterprise-grade practices are neither affordable nor designed for use at global scale.
Enterprise big data requires new doctrines that combine the robustness of enterprise-grade practices with affordability that is necessary to handle hundreds of millions of users. A good example is the system redundancy strategy of no single point of failure (noSPOF). System redundancy is a design principle applied to platforms to allow them to function in the presence of abnormal operating conditions.
For example, in the past, Ethernet hardware interfaces used to be so unreliable they needed protection through redundancy. As those parts became integrated into servers, their reliability improved to the point where the software protecting against their failure was less reliable than the hardware it was designed to protect.
At enterprise scale, it is often easy to implement the noSPOF policy because the cost and complexity are tolerable. At global scale, HA for computing platforms that often span multiple datacenters requires more affordable strategies.
At internet scale, not all single points of failure are created equal, so applying the principle across all potential points of failure is difficult to implement, complex to manage, and very expensive. The top three categories of system failure are physical plant, operator error, and software bugs. In an attempt to reduce failures, the noSPOF policy becomes overused, which introduces so much complexity that it ends up reducing reliability.
At global scale, these negative effects are greatly magnified. Enterprise-scale systems are typically not highly distributed and are more susceptible to just a few critical pathways of failure. Distributed systems also contain critical pathways, but have fewer of them in addition to having many parallel service pathways.
All systems contain critical pathways, which if they fail, would create some form of unavailability. When trying to figure out which points of failure are critical, the first question is often “what happens if it fails?” but the more important question is “what happens when it fails?”
The first question assumes deterministic failure and is often expressed as Murphy’s Law: if it can fail, it will. In reality, everything doesn’t fail. There are parts that might fail but not all parts do fail, so it is important to assess the probability of a part failing. The next question to ask is “what is the outcome of the failure”?
A critical pathway is defined both by its probability of occurring and its severity of outcome. They all have a pathway severity index (PSI), which is a combination of the probability and outcome (or reduction in availability) from the failure of each pathway.
Any pathway—whether in hardware or software—with a high PSI requires a redundancy strategy. The noSPOF strategy is overused at enterprise-scale because it is often easier to apply it everywhere than it is to determine which pathways have a high severity index.
The strategy of over-deploying noSPOF compromises reliability because the complexity ends up increasing the PSI for the pathway. Distributed systems have many more pathways, which spread out and reduce the risk of critical pathway failures that could result in complete platform failure.
Because these platforms are highly distributed, the effect of the distribution replaces just a few high PSI pathways with hundreds of low PSI pathways. And low PSI pathways do not require noSPOF.
At either enterprise or global scale, rough estimates of PSI can help prioritize where redundancy bets should be placed. Locating aspects of design within the gap between recklessness and risk aversion will result in a more optimized platform.
The noSPOF doctrine is enterprise-scale availability engineering. The global-scale version must be solved and optimized within the economic, architectural, and operational dimensions that constrain any platform.
Avoiding epic failure at global scale mandates the need to understand how distributed systems optimize for availability by keeping it simple and keeping it easy because that keeps it reliable.
Optimize Absolutely Everything
Platforms must operate at such a high level of performance, complexity, and cost that their solution space must always be optimized at the intersection of operations, economics, and architecture. These three dimensions are fundamental to any form of platform design, whether the platform is a supercomputer cluster or a Honda Civic. Platforms can still be successful without being optimized in all dimensions, but the more optimized, the more efficient.
Determining whether a platform is as optimized as it should be is as difficult and subjective as designing the platform in the first place. Enterprises that want to fully realize the benefits of big data will also find themselves with global-scale expectations of their platforms, staff, and vendors.
Big data platforms are monster computers. A single Hadoop cluster with serious punch consists of hundreds of racks of servers and switches. These racks do not include the surrounding infrastructure used to get the bales of data onto the cluster.
Many enterprises can set up hundreds of racks of gear, but few can stand them up as a single supercomputing platform. Getting a Hadoop cluster up and running is hard enough, but optimizing it in all dimensions is a whole other pool of fish. Optimization is about maximizing productivity and making the most of your precious resources, whether they are myelin, metal, or baked from sand.
Optimizing a platform means spending money more wisely, not just spending less on what might appear to be the same value. Any organization can reduce costs by not spending money, but that’s not optimization—that’s just spending less money while assuming that quality remains constant; as if laying off employees never affects the remaining staff.
These kinds of “productivity improvements” are often misconstrued as optimization. Cutting costs always makes a business more profitable, but not necessarily more efficient or strategically positioned.
Every part of a platform that contributes to economic activity can be optimized and all forms of activity have value or utility. “Bang for the buck” is another way to say optimize everything; the bang comes from anywhere, anything, or anyone. It can mean either spending fewer bucks for a given bang, or squeezing more bang from a single buck.
A simple optimization strategy for data circuits running between Texas and Montana could include improving the software engineering used to route data, or buying a cheaper set of switches that provide just the required capabilities, or renegotiating service level agreements with the carrier. The strategy to optimize everything is an operational example of perpetual prototyping.
Mind the Gap
In order to optimize aspects of any business, more accurate risk analysis is required. And in order to optimize aspects of any platform, more accurate risk analysis is required. There is a continuum of risk between aversion and recklessness. Some businesses can afford to be risk averse, but most cannot.
To mitigate risk, corporations employ many strategies that require some degree of calculated risk. Sometimes it is calculated very accurately with numbers and sometimes employees just have to make educated guesses.
In preparation for big data, enterprises and agencies need to optimize some of the computing systems that are now the heart and lungs of their business. Accurately analyzing the risk of failure within any platform—including the hardware, software, humans, or competitors—is a key to optimizing the efficiency of those platforms. It might seem odd to consider the competitive landscape or a group of employees to be platforms, but all behave like interconnected systems.
Get Disruptive Possibilities: How Big Data Changes Everything now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

