Clustering
Spark MLlib has implemented the K-means clustering algorithm. The model training and prediction interfaces are similar to other machine learning algorithms. Let's see how it works by going through an example.
Let's use a sample data that has two dimensions: x and y. The plot of the points looks like the following screenshot:
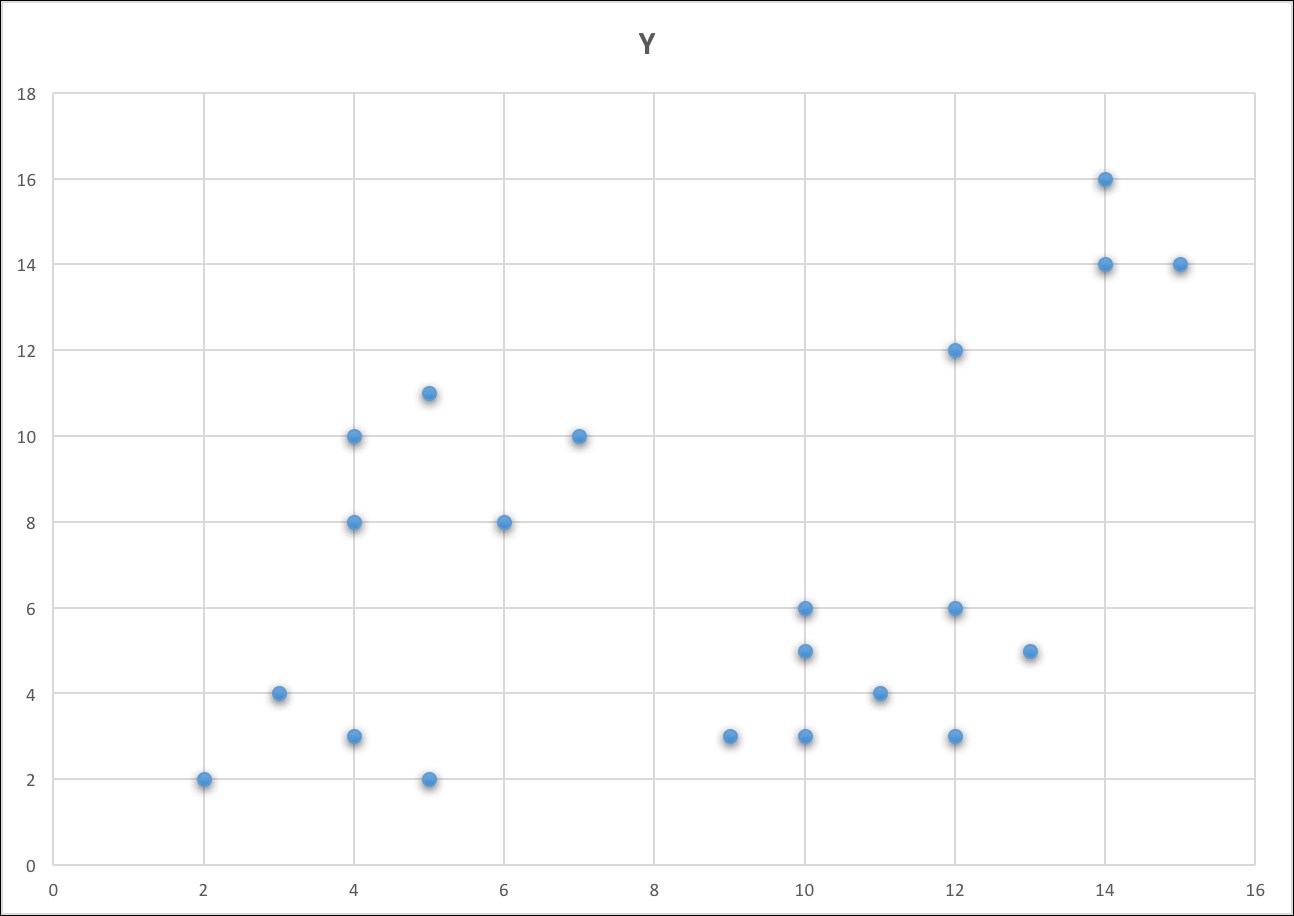
From the preceding graph, we can see that four clusters form one solution. Let's try k = 2 and k=4. Let's see how the Spark clustering algorithm handles this Dataset and the groupings.
Loading data
By now, we know very well how to load data using the read.csv() method. The following code file is ML03v2.scala:
We run ...
Get Fast Data Processing with Spark 2 - Third Edition now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

