Chapter 3. Serialization
Big data systems spend a great deal of time and resources moving data around. Take, for example, a typical process that looks at logs. That process might collect logs from a few servers, moving those logs to HDFS, perform some sort of analysis to build a handful of reports, then move those reports to some sort of dashboard your users can see. At each step in that process, you’re moving data, in some cases multiple times, between systems, off hard drives and into memory. See Figure 3-1.
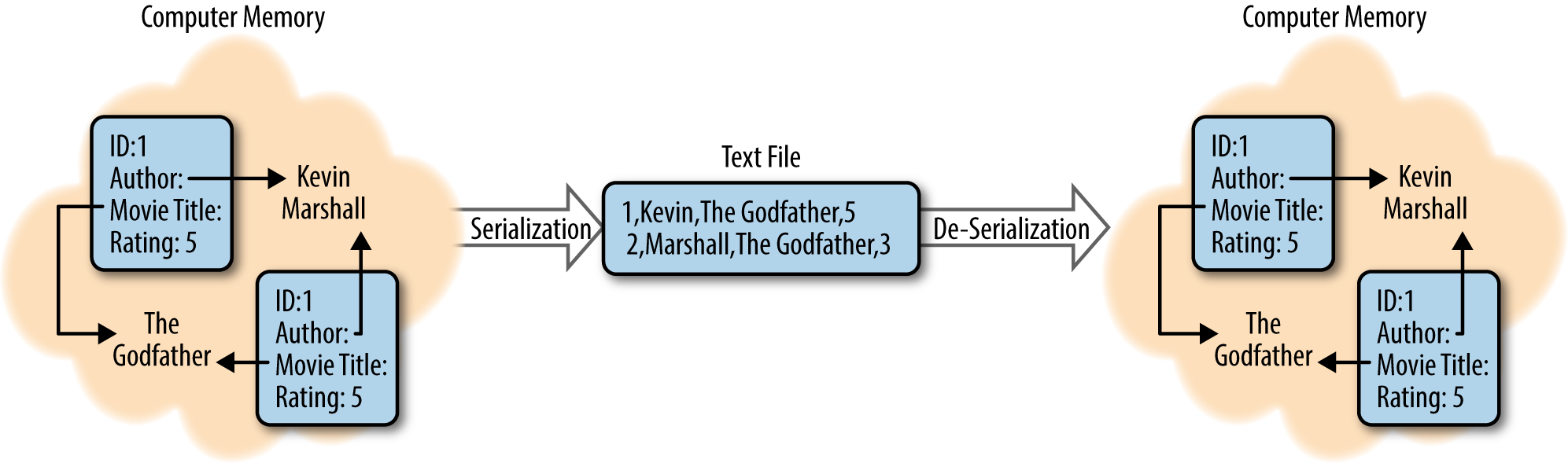
Figure 3-1. Serialization and deserialization of a movie review
When modern computers work with data, it’s often held in all manner of complex formats, full of internal relationships and references. When you want to write this data down, whether to share it or to store it for later, you need to find a way to break down those relationships, explain the references, and build a representation of the data that can be read from start to finish. This process is called serialization.
Similarly, have you ever read a great description of a place or event and found that you could picture it perfectly in your head? This process of reading something that’s been written down (serialized) and rebuilding all the complex references and relationships is known as de-serialization.
There is a wide variety of data serialization tools and frameworks available to help manage what your data looks ...
Get Field Guide to Hadoop now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

