Chapter 4. Use Cases for Multi-Model
We have already discussed some of the key benefits multi-model databases bring to the table, and some problems and complexities that they address. In this next section, we discuss some common use cases for which multi-model really shines. These use cases will bring a better understanding of when and where to use a multi-model approach, and how multi-model databases help ensure an IT system’s longevity and usefulness.
Storing and Managing Multiple Heterogeneous Data Sources
Being able to store multiple forms of data in a single database is the core advantage offered by a multi-model database. But, there’s much more that a multi-model database does for us. For example, suppose that we needed to store RDF, JSON, and XML data for searching. Storing these three types of data in three separate systems would be a complex administrative task. On top of storing the data, you also want to offer the capabilities of a search engine, increasing the administrative complexity even more. A multi-model database that supports these three types of data would not only allow us to store and search all of the data, but also allow us to administer the data in a single integrated solution. To better explain what this can mean for you and how it can reduce the complexity and cost of administering multiple disparate systems, let’s take a look at some of the features that a multi-model database offers.
First, let’s consider some of the basic administrative tasks that would need to be performed in a typical IT system: data backups and redundancy, security and user access, indexing, and so on. Imagine having to manage these tasks for the RDF, JSON, and XML data stores. By storing this data in a multi-model database, we are required to set up and maintain these administrative tasks only once, for the multi-model database. We can set up data backups, clustering for data redundancy and security policies to manage data access. Doing it once, on a single backend, for all data stored in the multi-model database greatly reduces the time and complexity of these types of administrative tasks.
One more key feature that many multi-model databases support is the ability to transform data from one data type to another. For example, if you store your document data in JSON format but would like to serve the data as XML to meet the requirements of a specific use case, you can easily and seamlessly achieve this, all in one database.
Invisibly Extending Model Features from One Model to Another
For many requirements, a single data model won’t be enough. We’ll want to use features of one data model or format to supplement some of the shortcomings of another. Many multi-model databases allow us to extend the features of one model so that we can take advantage of the features of another model.
One example of this type of functionality is when we extend JSON data to allow for SQL querying. Imagine being able to bring in a JSON data source and exposing it as SQL. Let’s consider what would be required to achieve this type of functionality in a relational system. First, we would need several different component systems: a system for extract, transform, and load (ETL); a source system; a destination system to store transformed data; processes for either detecting or pushing updates from a source system to its destination; a data quality process; and so on. We can see how this quickly becomes a complex endeavor. Wouldn’t it be nice to simply take source data as is, without any processing, and place it in a destination to be queried or processed if necessary? Multi-model databases like Couchbase and MarkLogic allow us to do this type of extension easily, without any upfront work, and the results are pretty amazing. An example of how this is done in a multi-model database will be highlighted in “Offering SQL Without Relational Constraints”.
One more example, which we talked about in “Data Models”, is serving XML data as JSON, and vice versa. We are not required to physically transform our data from one format to another to achieve this. The multi-model database handles this for us, without modifying the underlying data source.
A Hybrid Approach to Analytical and Operational Data
Traditionally, organizations have separated their analytical systems data and operational data. For example, an organization’s operational data is stored in a transactional online transaction processing (OLTP) system. This data is then processed and transformed for storage in a system designed for analytics such as an online analytical processing (OLAP) or data warehouse. You end up with something like that illustrated in Figure 4-1.
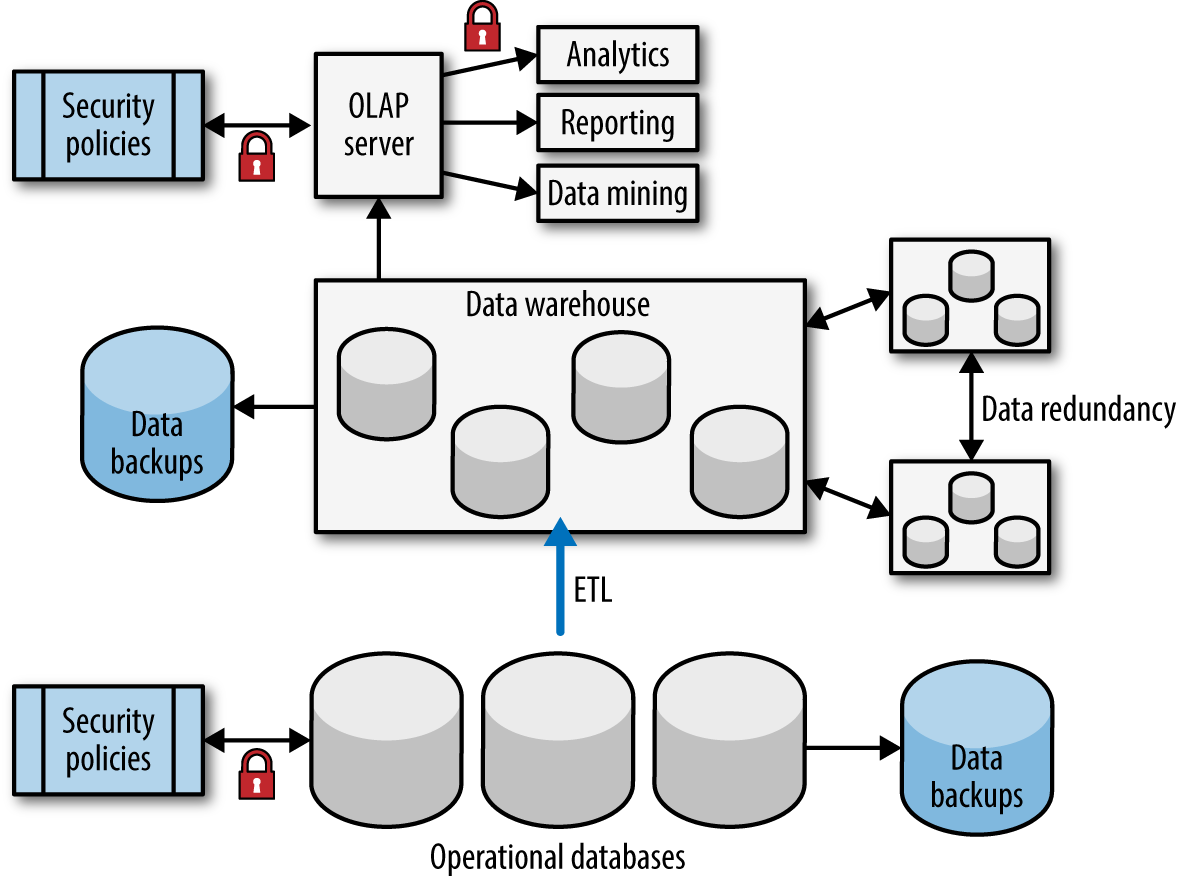
Figure 4-1. Data analytics system setup
Figure 4-1 represents a typical strategy used to leverage operational data for analytics. As you can see, we have several operational databases: a potentially complex ETL system, a number of databases used within a data warehouse, and an OLAP server used for analytics. The administrative overhead of a system like this can be substantial. You would also be required to model the data going into the operational databases, implement logic for extracting and transforming data, and model how you might want the data structured in the analytical database.
As analytics requirements and use cases change, you would need to modify many or all of the components in order to support the new needs. Using a multi-model database as an operational data hub that supports both operational and analytical data, you eliminate the majority of this complexity and maintenance overhead. For example, each of the components in Figure 4-1 might require data backups, administration of security policies, and data redundancy support. With the multi-model database, as we have discussed, you are able to take advantage of administrative efforts to support all aspects of the system. Figure 4-2 shows how a multi-model database could simplify things.
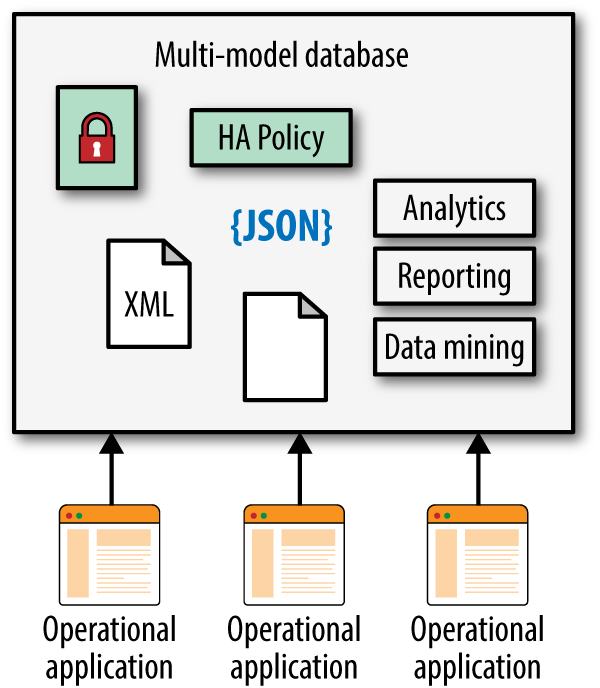
Figure 4-2. A simplified setup using multi-model database
Overall, the approach illustrated in Figure 4-2 using a multi-model database allows you to do the following:
-
Reduce the amount of ETL required
-
Reduce the amount of data duplicated across a system, which will result in higher levels of data quality
-
Reduce or eliminate the need for data silos, increasing the likelihood of sharing data across organizations
-
Reduce the effort required to administer the overall system’s security, data backups, and so on.
Data Consolidation
Oftentimes in organizations, we see barriers between data sources. These barriers, whether they are physical, political, or something else, hinder an organization’s ability to fully utilize its data. Being able to have all of an organization’s data in a single system is a great strategic advantage. Possessing the ability to use all of an organization’s data to uncover valuable insights is something that a multi-model database enables. To use a multi-model database to consolidate your data, you simply bring the data in “as is.” After you have your data in the multi-model database, you can choose how you want to aggregate your data as use cases are uncovered.
Enhancing User Search Experience
This use case might be obvious, but we’ll still take a look at it at a more detailed level. Let’s use the example of a media repository. We are going to need to create a search application that will allow customers to search for media in which they are interested. We will also need to incorporate some type of recommendation engine. This recommendation engine recommends books, movies, and songs related to a search the user has performed. It uses actors, authors, singers, and so on to determine whether it should recommend a piece of media. Here is a description of the data available to the system:
-
Metadata relating to media which is in the form of graphs/triples
-
Metadata providing information such as genre, author, actors, singers, and time period
-
Documents containing data such as song, book and movie descriptions, descriptions of authors, and actors. These documents also contain embedded triples that point to a specific piece of media.
Figure 4-3 shows us how the multi-model database allows us to enhance the user’s search experience.
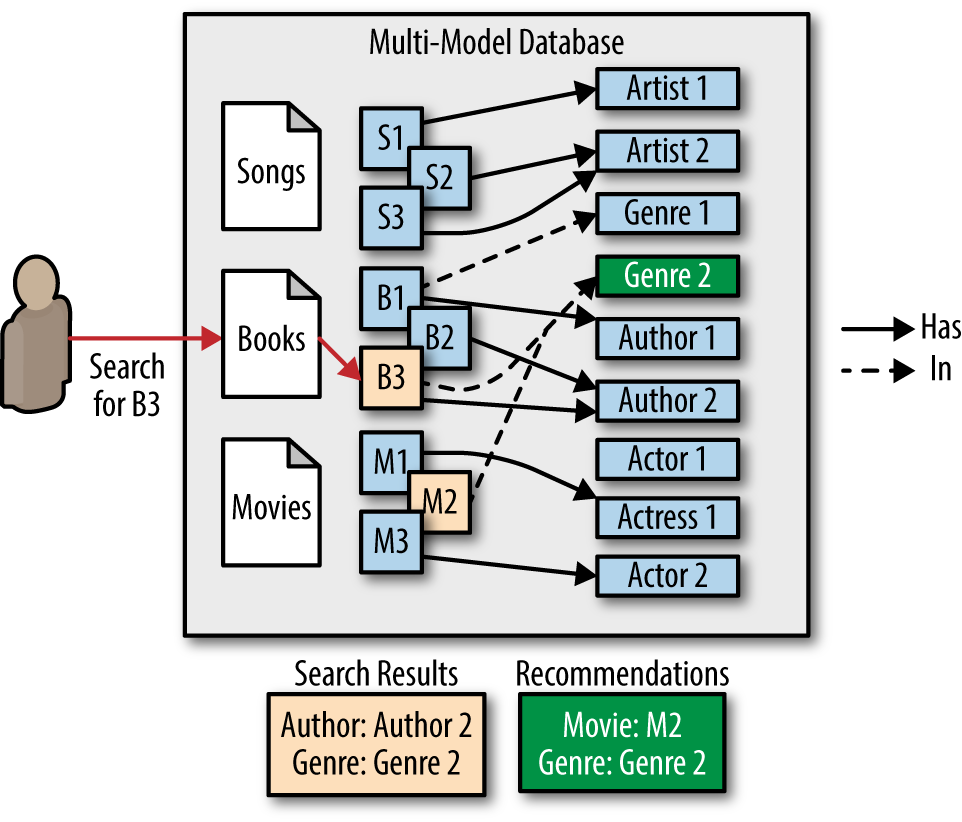
Figure 4-3. Enhanced search using triples
The user searched for a book called B3. This search was executed against document data. This document data had embedded triples pointing to an ontology containing media-related metadata such as artists, authors, and genres. Because M2 is in the same genre as B3, M2 is returned as a recommendation. This type of use case shows us that we can use all forms of data that are stored in the multi-model database, do it in a single query, and return applicable results and use metadata/triples to enhance those results.
Adding Search to Big Data
Hadoop has become a popular choice for enterprises needing to process large amounts of disparate data and data models. Hadoop is great at quickly and cost-effectively receiving, transforming, and storing many different types of data. However, one thing it lacks is search capability. Replacing or combining Hadoop with a multi-model database can be a powerful strategy for creating a robust and scalable data system. By allowing Hadoop to do some of the heavy lifting of receiving and processing data and then pushing that data into a multi-model database, you take advantage of its processing power and the multi-model database’s strength of search—and governance! (For more information on this, see the report Cleaning Up the Data Lake with an Operational Data Hub (O’Reilly) by Gerhard Ungerer.)
Querying Across Data Models
The following scenario shows us how we might take advantage of multiple models and data structures in a single database. It demonstrates the power you can gain by having this consolidated multi-model system, as opposed to having multiple integrated systems.
Suppose that we have an XML document against which we want to query. We then want to take the results of the document query, extract a piece of data from a document in the results, and use that piece of data to query for triples in some graph data we have. We now have a response containing triples, but we want to return it to the user as JSON. So, we have XML, graph data, and JSON data all in a single call. Figure 4-4 depicts how this could look using XQuery and some of the multi-model features provided by MarkLogic.
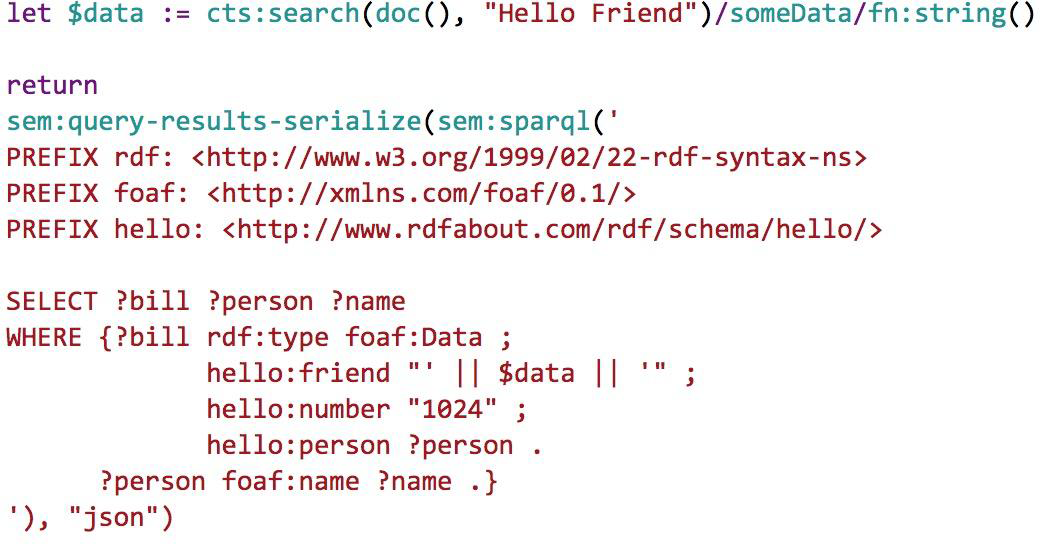
Figure 4-4. Querying across data models
First, we’re querying for a document that contains “Hello Friend”. Using the response from that query, we’re building up a SPARQL query. We are then querying our graph data and returning the response as JSON.
Offering SQL Without Relational Constraints
Multi-model databases like MarkLogic and Couchbase offer the capability to expose data via SQL or SQL-like queries. These multi-model databases essentially place a “lens” over your data without changing the underlying structure. As the underlying data is modified, this SQL view of your data is automatically updated. MarkLogic takes it one step further and allows you to create templates that define what data you want to expose as SQL. This functionality, called template-driven extraction, generates indexes behind the scene so that queries are responsive and efficient. By offering SQL views of your data, users who require SQL capabilities can still access their data, and at the same time, you are not required to support a relational database. You can even extend these views to support triple generation. Figure 4-5 illustrates how it works at a high level.
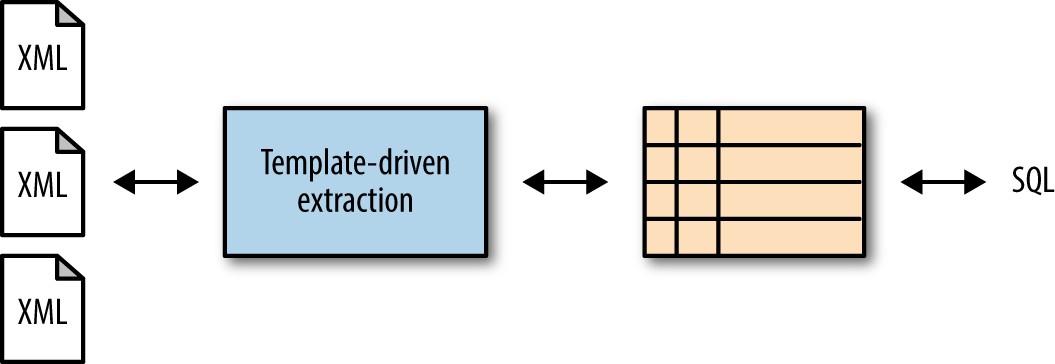
Figure 4-5. Template-driven extraction exposing data with SQL
Multi-Model Database Storage Types
We have talked about some common use cases for the multi-model database. In this section, we list out some multi-model databases. The following list contains some of the available multi-model databases and the types of data they can store:
- ArangoDB
-
JSON, graph, key–value
- Couchbase
-
JSON, key–value
- DataStax
-
Key–value, tabular, graph
- MarkLogic
-
XML, JSON, graph, text, geospatial, binary, SQL
- Oracle
-
XML, JSON, graph, text, geospatial, binary, SQL
Get Gaining Data Agility with Multi-Model Databases now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

