Chapter 1. Generative AI Use Cases, Fundamentals, and Project Life Cycle
In this chapter, you will see some generative AI tasks and use cases in action, gain an understanding of generative foundation models, and explore a typical generative AI project life cycle. The use cases and tasks you’ll see in this chapter include intelligent search, automated customer-support chatbot, dialog summarization, not-safe-for-work (NSFW) content moderation, personalized product videos, source code generation, and others.
You will also learn a few of the generative AI service and hardware options from Amazon Web Services (AWS) including Amazon Bedrock, Amazon SageMaker, Amazon CodeWhisperer, AWS Trainium, and AWS Inferentia. These service and hardware options provide great flexibility when building your end-to-end, context-aware, multimodal reasoning applications with generative AI on AWS.
Let’s explore some common use cases and tasks for generative AI.
Use Cases and Tasks
Similar to deep learning, generative AI is a general-purpose technology used for multiple purposes across many industries and customer segments. There are many types of multimodal generative AI tasks. We’ve included a list of the most common generative tasks and associated example use cases:
- Text summarization
-
Produce a shorter version of a piece of text while retaining the main ideas. Examples include summarizing a news article, legal document, or financial report into a smaller number of words or paragraphs for faster consumption. Often, summarization is used on customer support conversations to provide a quick overview of the interaction between a customer and support representative.
- Rewriting
-
Modify the wording of a piece of text to adapt to a different audience, formality, or tone. For example, you can convert a formal legal document into a less formal document using less legal terms to appeal to a nonlegal audience.
- Information extraction
-
Extract information from documents such as names, addresses, events, or numeric data or numbers. For example, converting an email into a purchase order in an enterprise resource planning (ERP) system like SAP.
- Question answering (QA) and visual question answering (VQA)
-
Ask questions directly against a set of documents, images, videos, or audio clips. For example, you can set up an internal, employee-facing chatbot to answer questions about human resources and benefits documents.
- Detecting toxic or harmful content
-
An extension to the question-answer task, you can ask a generative model if a set of text, images, videos, or audio clips contains any toxicity or harmful content.
- Classification and content moderation
-
Assign a category to a given piece of content such as a document, image, video, or audio clip. For example, deleting email spam, filtering out inappropriate images, or labeling incoming, text-based customer-support tickets.
- Conversational interface
-
Handle multiturn conversations to accomplish tasks through a chat-like interface. Examples include chatbots for self-service customer support or mental health therapy sessions.
- Translation
-
One of the earliest use cases for generative AI is language translation. Consider, for example, that the publisher of this book wants to release a German translation to help expand the book’s reach. Or perhaps you may want to convert the Python-based examples to Java to work within your existing Java-based enterprise application.
- Source code generation
-
Create source code from natural language code comments—or even a hand-drawn sketch, as shown in Figure 1-1. Here, an HTML- and JavaScript-based website is generated from a UI sketch scribbled on the back of a restaurant napkin.
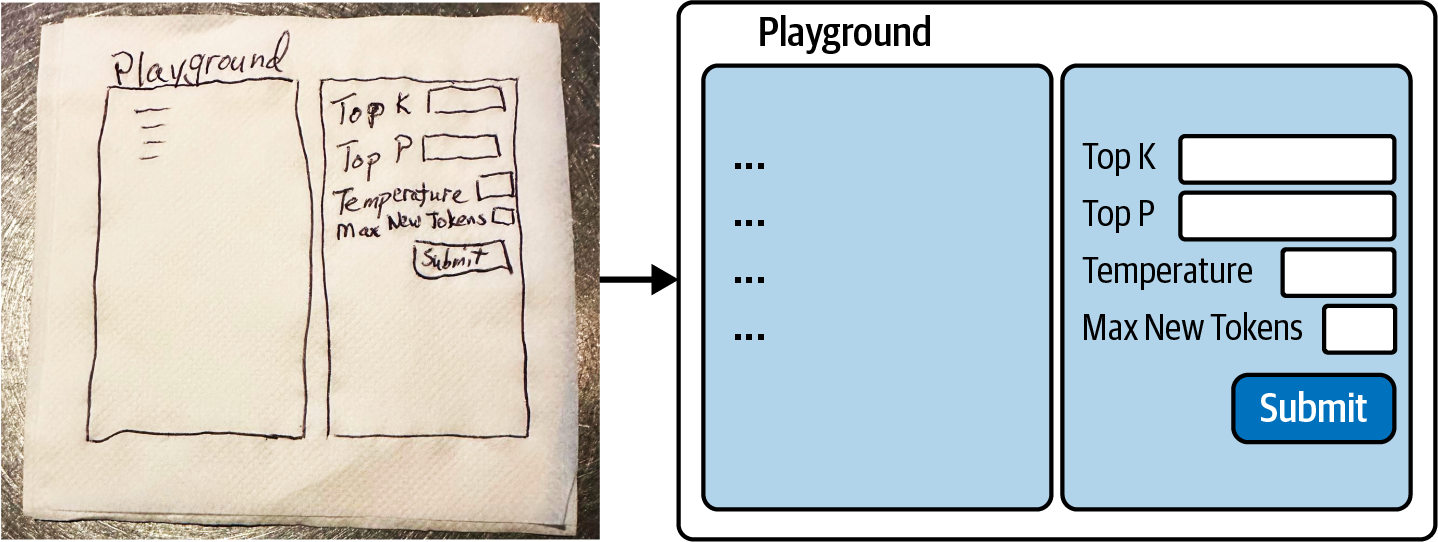
Figure 1-1. Generating UI code from hand-drawn sketch
- Reasoning
-
Reason through a problem to discover potential new solutions, trade-offs, or latent details. For example, consider a CFO who provides an audio-based quarterly financial report to investors as well as a more-detailed written report. By reasoning through these different media formats together, the model may discover some conclusions about the company’s health not directly mentioned in the audio or stated in the text.
- Mask personally identifiable information (PII)
-
You can use generative models to mask personally identifiable information from a given corpus of text. This is useful for many use cases where you are working with sensitive data and wish to remove PII data from your workflows.
- Personalized marketing and ads
-
Generate personalized product descriptions, videos, or ads based on user profile features. Consider an ecommerce website that wants to generate a personalized description for each product based on the logged-in user’s age or family situation. You could also generate personalized product images that include mature adults, adults with children, or children themselves to better appeal to the logged-in user’s demographic, as shown in Figure 1-2.

Figure 1-2. Personalized marketing
In this case, each user of the service would potentially see a unique and highly personalized image and description for the same product. This could ultimately lead to more product clicks and higher sales.
In each of these generative use cases and tasks, a model creates content that approximates a human’s understanding of language. This is truly amazing and is made possible by a neural network architecture called the transformer, which you will learn in Chapter 3.
In the next section, you will learn how to access foundation models through model hubs.
Foundation Models and Model Hubs
Foundation models are very large and complex neural network models consisting of billions of parameters (a.k.a. weights). The model parameters are learned during the training phase—often called pretraining. Foundation models are trained on massive amounts of training data—typically over a period of many weeks and months using large, distributed clusters of CPUs and graphics processing units (GPUs). After learning billions of parameters, these foundation models can represent complex entities such as human language, images, videos, and audio clips.
In most cases, you will start your generative AI projects with an existing foundation model from a model hub such as Hugging Face Model Hub, PyTorch Hub, or Amazon SageMaker JumpStart. A model hub is a collection of models that typically contains detailed model descriptions including the use cases that they address.
Throughout this book, we will use Hugging Face Model Hub and SageMaker JumpStart to access foundation models like Llama 2 from Meta (Facebook) and Falcon from the Technology Innovation Institute (TII) and FLAN-T5 from Google. You will dive deeper into model hubs and foundation models in Chapter 3.
Next, you’ll see a typical generative AI project life cycle that roughly follows the outline of the rest of this book.
Generative AI Project Life Cycle
While there is no definitive project life cycle for generative AI projects, the framework shown in Figure 1-3 can help guide you through the most important parts of your generative AI application journey. Throughout the book, you will gain intuition, learn to avoid potential difficulties, and improve your decision making at each step in the journey.
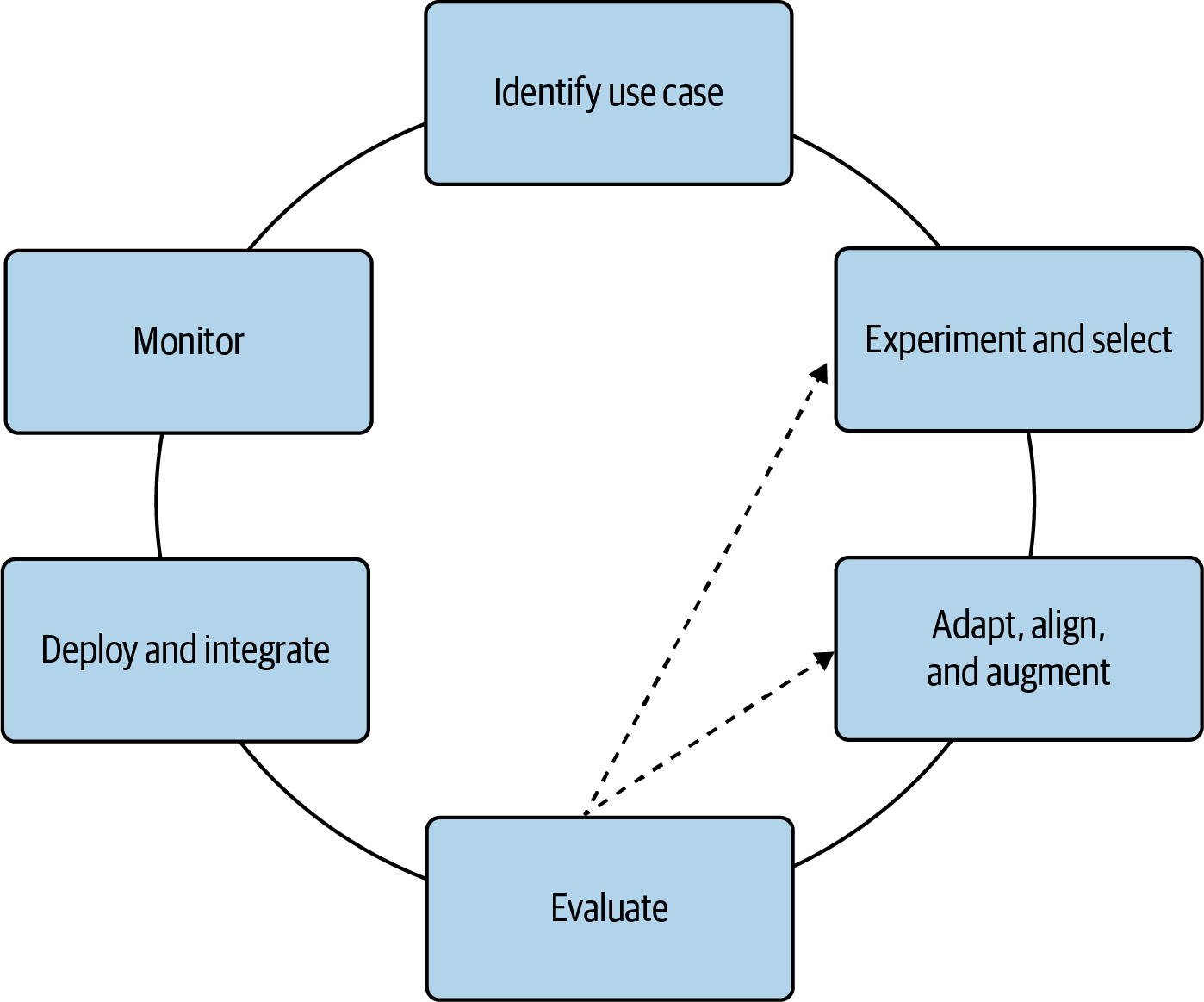
Figure 1-3. Generative AI project life cycle framework
Let’s dive into each component of the life cycle shown in Figure 1-3:
- Identify use case.
-
As with any project, you first want to define your scope, including the specific generative use case and task that you plan to address with your generative AI application. We recommend that you start with a single, well-documented generative use case. This will help you get familiar with the environment and understand the power—and limitations—of these models without trying to optimize the model for different tasks at the same time. While these models are capable of carrying out multiple tasks, it’s a bit more difficult to evaluate and optimize the model across multiple tasks to start.
- Experiment and select.
-
Generative AI models are capable of carrying out many different tasks with great success. However, you will need to decide if an existing foundation model is suitable for your application needs. In Chapter 2, you will learn how to work with these existing foundation models right out of the box using techniques called prompt engineering and in-context learning.
Most commonly, you will start from an existing foundation model (as you will see in Chapter 3). This will greatly improve your time-to-market since you will avoid the pretraining step, which is extremely resource intensive and often requires trillions of words, images, videos, or audio clips to get started. Operating at this scale requires a lot of time, patience, and compute—often millions of GPU hours are required when pretraining from scratch.
You also want to consider the size of the foundation model you decide to work with as this will impact the hardware—and cost—needed to train and serve your models. While larger models tend to generalize better to more tasks, this is not always the case and depends on the dataset used during training and tuning.
We recommend that you try different models for your generative use case and task. Start with an existing, well-documented, relatively small (e.g., 7 billion-parameter) foundation model to iterate quickly and learn the unique ways of interacting with these generative AI models with a relatively small amount of hardware (compared to the larger 175+ billion-parameter models).
During development, you would typically start with a playground environment within either Amazon SageMaker JumpStart or Amazon Bedrock. This lets you try different prompts and models quickly, as you will see in Chapter 2. Next, you might use a Jupyter notebook or Python script using an integrated development environment (IDE) like Visual Studio Code (VS Code) or Amazon SageMaker Studio notebooks to prepare your custom datasets to use when experimenting with these generative models. Once you are ready to scale your efforts to a larger distributed cluster, you would then migrate to SageMaker distributed training jobs to scale to a larger compute cluster using accelerators like the NVIDIA GPU or AWS Trainium, as you will see in Chapter 4.
While you may be able to avoid accelerators initially, you will very likely need to use them for longer-term development and deployment of more complex models. The sooner you learn the unique—and sometimes obscure—aspects of developing with accelerators like NVIDIA GPUs or AWS Trainium chips, the better. Fortunately, a lot of the complexity has been abstracted by the hardware provider through the NVIDIA CUDA library and AWS Neuron SDK, respectively.
- Adapt, align, and augment.
-
It’s important to adapt generative models to your specific domain, use case, and task. Chapters 5, 6, 7, and 11 are dedicated to fine-tuning your multimodal generative AI models with your custom datasets to meet your business goals.
-
Additionally, as these generative models become more and more humanlike, it is important that they align with human values and preferences—and, in general, behave well. Chapters 7 and 11 explore a technique called reinforcement learning from human feedback (RLHF) to align your multimodal generative models to be more helpful, honest, and harmless (HHH). RLHF is a key component of the much-broader field of responsible AI.
-
While generative models contain an enormous amount of information and knowledge, they often need to be augmented with current news or proprietary data for your business. In Chapter 9, you will explore ways to augment your generative models with external data sources or APIs.
- Evaluate.
-
To properly implement generative AI applications, you need to iterate heavily. Therefore, it’s important to establish well-defined evaluation metrics and benchmarks to help measure the effectiveness of fine-tuning. You will learn about model evaluation in Chapter 5. While not as straightforward as traditional machine learning, model evaluation helps measure improvements to your models during the adaptation and alignment phase—specifically, how well the model aligns to your business goals and human preferences.
- Deploy and integrate.
-
When you finally have a well-tuned and aligned generative model, it’s time to deploy your model for inference and integrate the model into your application. In Chapter 8, you will see how to optimize the model for inference and better utilize your compute resources, reduce inference latency, and delight your users.
-
You will also see how to deploy your models with the AWS Inferentia family of compute instances optimized for generative inference using Amazon SageMaker endpoints. SageMaker endpoints are a great option for serving generative models as they are highly scalable, fault tolerant, and customizable. They offer flexible deployment and scaling options like A/B testing, shadow deployments, and autoscaling, as you will learn in Chapter 8.
- Monitor.
-
As with any production system, you should set up proper metrics collection and monitoring systems for all components of your generative AI application. In Chapters 8 and 12, you will learn how to utilize Amazon CloudWatch and CloudTrail to monitor your generative AI applications running on AWS. These services are highly customizable, accessible from the AWS console or AWS software development kit (SDK), and integrated with every AWS service including Amazon Bedrock, a managed service for generative AI, which you will explore in Chapter 12.
Generative AI on AWS
This section will outline the AWS stack of purpose-built generative AI services and features, as shown in Figure 1-4, as well as discuss some of the benefits of using AWS for generative AI.

Figure 1-4. AWS services and features supporting generative AI
Model providers include those that are building or pretraining foundation models requiring access to powerful, and cost performant, compute and storage resources. For this, AWS offers a range of frameworks and infrastructure to build foundation models. This includes optimized compute instances for generative AI with self-managed options such as Amazon EC2 as well as managed options like Amazon SageMaker for model training and model deployment. In addition, AWS offers its own accelerators optimized for training (AWS Trainium) and deploying generative models (AWS Inferentia).
AWS Trainium is an accelerator that is purpose-built for high-performance, low-cost training workloads. Similarly, AWS Inferentia is purpose-built for high-throughput, low-cost inference. The infrastructure options on AWS that are optimized for generative AI are used by model providers but also model tuners.
Model tuners include those that are adapting or aligning foundation models to their specific domain, use case, and task. This typically requires access to not only storage and compute resources but also tooling that helps enable these tasks through easy access to a range of foundation models while removing the need to manage underlying infrastructure. In addition to the range of optimized infrastructure available on AWS, tuners also have access to a broad range of popular foundation models as well as tooling to adapt or align foundation models, including capabilities built into Amazon Bedrock and Amazon SageMaker JumpStart.
Amazon Bedrock is a fully managed service that provides access to models from Amazon (e.g., Titan) and popular third-party providers (e.g., AI21 Labs, Anthropic, Cohere, and Stability AI). This allows you to quickly get started experimenting with available foundation models. Bedrock also allows you to privately customize foundation models with your own data as well as integrate and deploy those models into generative AI applications. Agents for Bedrock are fully managed and allow for additional customization with the integration of proprietary external data sources and the ability to complete tasks.
Amazon SageMaker JumpStart provides access to both public and proprietary foundation models through a model hub that includes the ability to easily deploy a foundation model to Amazon SageMaker model deployment real-time endpoints. Additionally, SageMaker JumpStart provides the ability to fine-tune available models utilizing SageMaker model training. SageMaker JumpStart automatically generates notebooks with code for deploying and fine-tuning models available on the model hub.
Amazon SageMaker provides additional extensibility, through managed environments in Amazon SageMaker Studio notebooks, to work with any available foundation model, regardless of whether it’s available in SageMaker JumpStart. As a result, you have the ability to work with any models accessible to you and are never limited in the models you can work with in Amazon SageMaker.
Adapting a model to a specific use case, task, or domain often includes augmenting the model with additional data. AWS also provides multiple implementation options for vector stores that store vector embeddings. Vector stores and embeddings are used for retrieval-augmented generation (RAG) to efficiently retrieve relevant information from external data sources to augment the data used with a generative model.
The options available include vector engine for Amazon OpenSearch Serverless as well as the k-NN plugin available for use with Amazon OpenSearch Service. In addition, both Amazon Aurora PostgreSQL and Amazon Relational Database Services (RDS) for PostgreSQL include vector stores capabilities through built-in pgvector support.
If you are looking for a fully managed semantic search experience on domain-specific data, you can use Amazon Kendra, which creates and manages the embeddings for you.
AWS offers multiple options if you want to access generative models through end-to-end generative AI applications. On AWS, you can build your own custom generative AI applications using the breadth and depth of services available; you can also take advantage of packaged, fully managed, services.
For example, Amazon CodeWhisperer provides generative coding capabilities across multiple coding languages, supporting productivity enhancements such as code generation, proactively scanning for vulnerabilities and suggesting code remediations, with automatic suggestions for code attribution.
AWS HealthScribe is another packaged generative AI service targeted toward the healthcare industry to allow for the automatic generation of clinical notes based on patient-clinician conversations.
Finally, Amazon QuickSight Q includes built-in generative capabilities allowing users to ask questions about data in natural language and receive answers as well as generated visualizations that allow users to gain more insights into their data.
This book will largely focus on the personas and tasks involved in the section “Generative AI Project Life Cycle”—as well as building generative AI applications. Many of the services highlighted in this section, such as Amazon SageMaker JumpStart and Amazon Bedrock, will be referenced throughout this book as you dive into specific areas of the generative AI project life cycle.
Now that we’ve introduced some core AWS services for generative AI, let’s look at some of the benefits of using AWS to build generative AI applications.
Why Generative AI on AWS?
Key benefits of utilizing AWS for your generative AI workloads include increased flexibility and choice, enterprise-grade security and governance capabilities, state-of-the art generative AI capabilities, low operational overhead through fully managed services, the ability to quickly get started with ready-to-use solutions and services, and a strong history of continuous innovation. Let’s dive a bit further into each of these with some specific examples:
- Increased flexibility and choice
-
AWS provides flexibility not only in the ability to utilize a range of services and features to meet the needs of each use case, but also in terms of choice in generative models. This provides you with the ability to not only choose the right model for a use case, but to also change and continually evaluate new models to take advantage of new capabilities.
- Enterprise-grade security and governance capabilities
-
AWS services are built with security and governance capabilities that are important to the most regulated industries. For example, SageMaker model training, SageMaker model deployment, and Amazon Bedrock support key capabilities around data protection, network isolation, controlled access and authorization, as well as threat detection.
- State-of-the-art generative AI capabilities
-
AWS offers choice in generative AI models, from Amazon models as well as third-party provider models in Amazon Bedrock to open source and proprietary models offered through Amazon SageMaker JumpStart. Additionally, AWS has also invested in infrastructure like AWS Trainium and AWS Inferentia for training and deploying generative models at scale.
- Low operational overhead
-
As previously discussed, many of the AWS services and features targeted toward generative AI are offered through managed infrastructure, serverless offerings, or packaged solutions. This allows you to focus on generative AI models and applications instead of managing infrastructure and to quickly get started with ready-to-use solutions and services.
- Strong history of continuous innovation
-
AWS has an established history of rapid innovation built on years of experience in not only cloud infrastructure but artificial intelligence.
The AWS stack of services and features for supporting generative AI covers the breadth, depth, and extensibility to support every use case, whether you’re a model provider, a tuner, or a consumer. In addition to the generative AI capabilities on AWS, a broader set of AWS services also supports the ability to build custom generative AI applications, which will be covered in the next section.
Building Generative AI Applications on AWS
A generative AI application includes more than generative models. It requires multiple components to build reliable, scalable, and secure applications that are then offered to consumers of that application, whether they are end users or other systems, as shown in Figure 1-5.
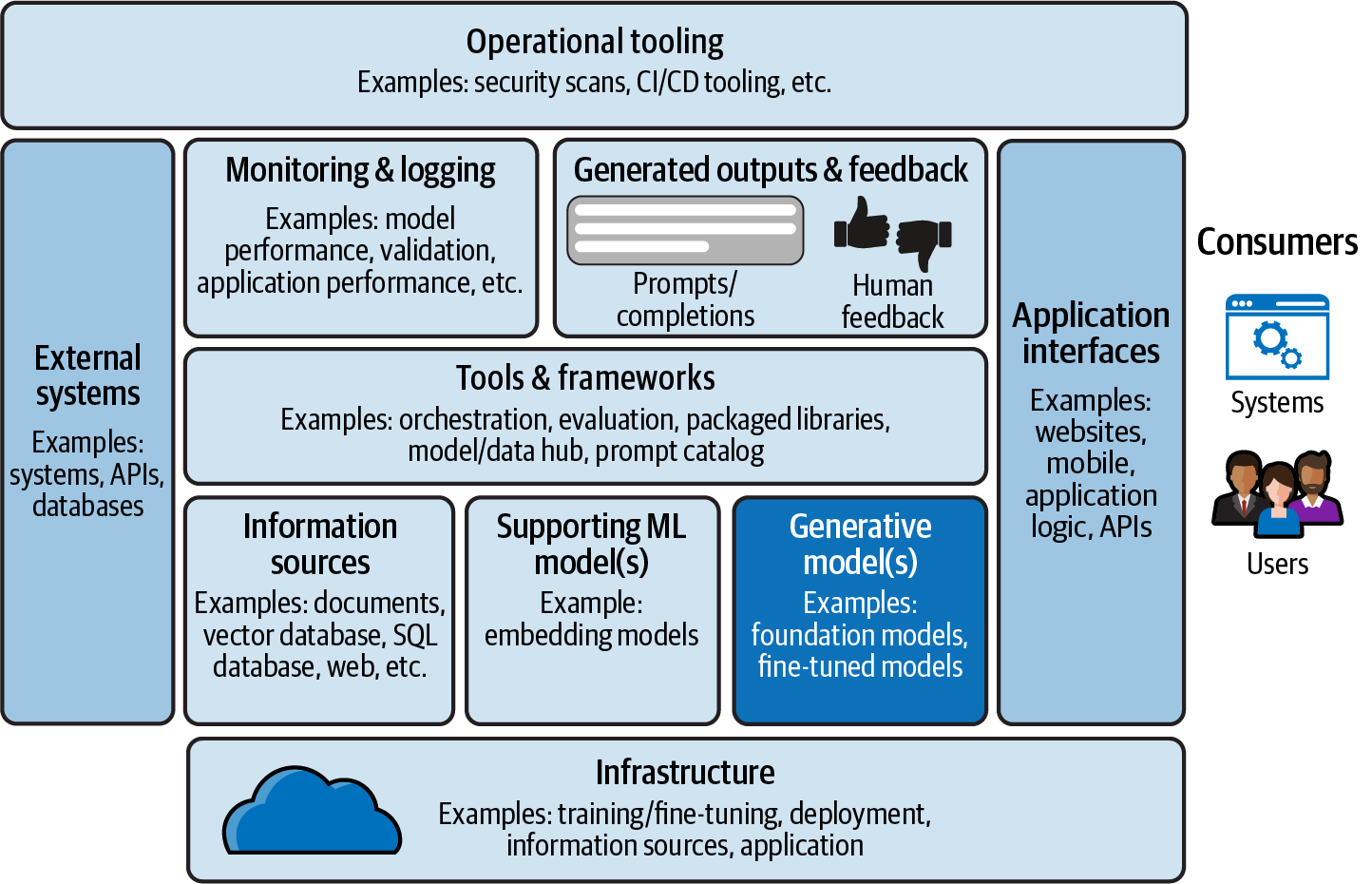
Figure 1-5. Generative AI applications include more than foundation models
When using a packaged generative AI service such as Amazon CodeWhisperer, all of this is completely abstracted and provided to the end user. However, building custom generative AI applications typically requires a range of services. AWS provides the breadth of services that are often required to build an end-to-end generative AI application. Figure 1-6 shows an example of AWS services that may be used as part of a broader generative AI application.
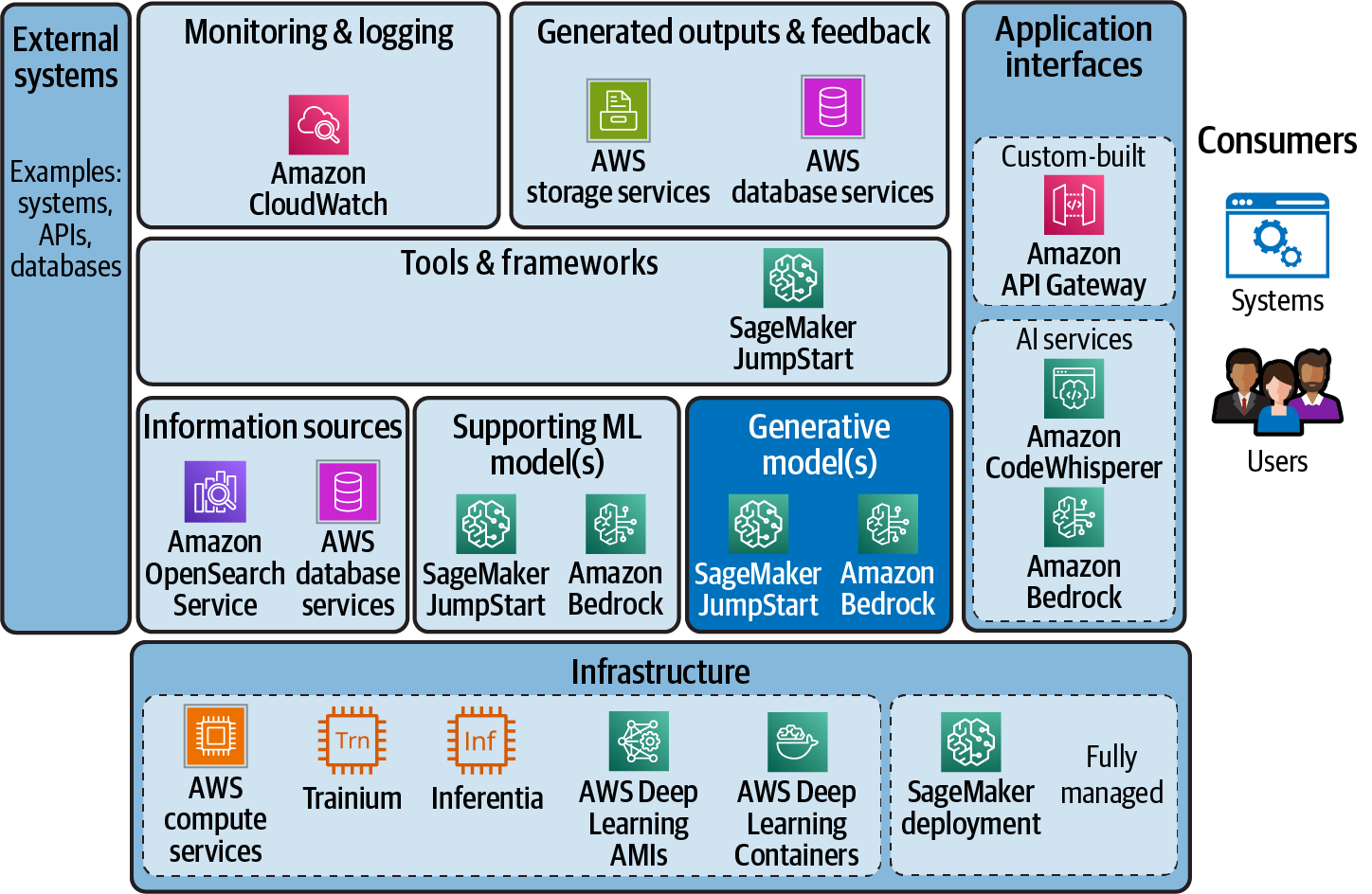
Figure 1-6. AWS breadth of service to enable customers to build generative AI applications
Summary
In this chapter, you explored some common generative AI use cases and learned some generative AI fundamentals. You also saw an example of a typical generative AI project life cycle that includes various stages, including defining a use case, prompt engineering (Chapter 2), selecting a foundation model (Chapter 3), fine-tuning (Chapters 5 and 6), aligning with human values (Chapter 7), deploying your model (Chapter 8), and integrating with external data sources and agents (Chapter 9).
The compute-intensive parts of the life cycle—including fine-tuning and human alignment—will benefit from an understanding of quantization and distributed-computing algorithms (Chapter 4). These optimizations and algorithms will speed up the iterative development cycle that is critical when developing generative AI models.
In Chapter 2, you will learn some prompt engineering tips and best practices. These are useful for prompting both language-only foundation models (Chapter 3) and multimodal foundation models (Chapters 10 and 11) using either Amazon SageMaker JumpStart model hub (Chapter 3) or the Amazon Bedrock managed generative AI service (Chapter 12).
Get Generative AI on AWS now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

