Designing the high-level architecture
The high-level architecture of the system that we are planning to build contains two parts. The first part is the model, which we will build using the historical transaction data. Once this model has been created, we will use it in the second part with new data to determine whether a particular transaction falls in a cluster of suspicious transactions.
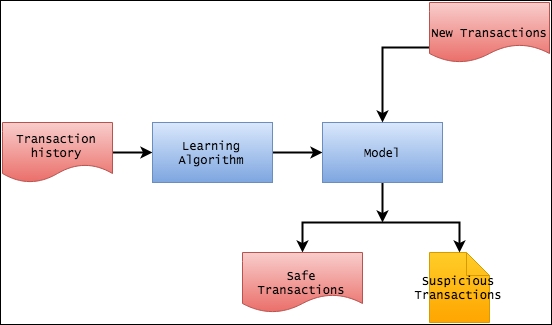
Figure 1 Design of a fraud detection system
In the previous section, we have already cleansed the transaction history file to make it suitable for the machine learning algorithm. For building the model, we will use Apache Spark.
Introducing Apache Spark
Apache Spark ...
Get Hadoop Blueprints now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

