January 2019
Intermediate to advanced
390 pages
9h 16m
English
Can we use this single neuron and make it learn? The answer is yes, the process of learning involves adapting the weights such that a predefined loss function (L) reduces. If we update the weights in the direction opposite to the gradient of the loss function with respect to weights, it will ensure that loss function decreases with each update. This algorithm is called the gradient descent algorithm, and is at the heart of all DL models. Mathematically, if L is the loss function and η the learning rate, then the weight wij is updated and represented as:
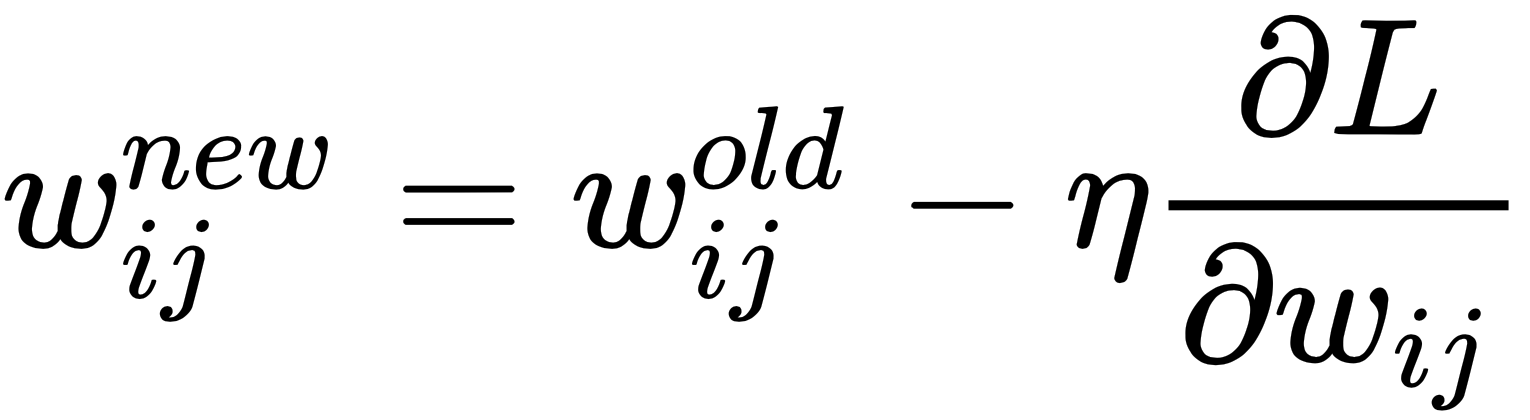
If we have to model the single artificial neuron, ...
Read now
Unlock full access






