Alright, let's look at another example of using Spark in MLlib, and this time we're going to look at k-means clustering, and just like we did with decision trees, we're going to take the same example that we did using scikit-learn and we're going to do it in Spark instead, so it can actually scale up to a massive Dataset. So, again, I've made sure to close out of everything else, and I'm going to go into my book materials and open up the SparkKMeans Python script, and let's study what's going on in.
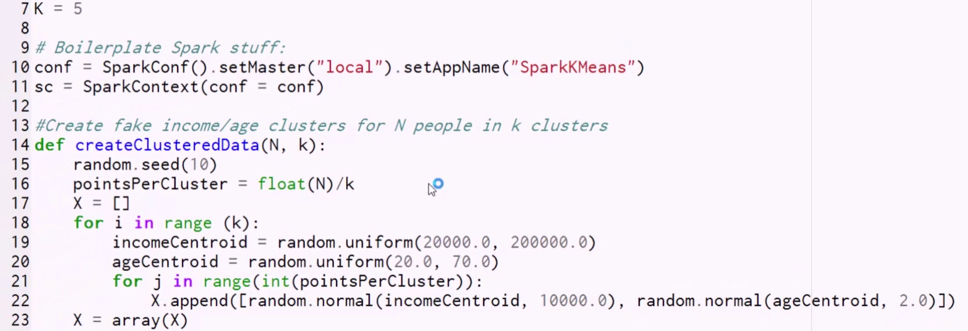
Alright, so again, we begin with some boilerplate stuff.
from pyspark.mllib.clustering import KMeans from numpy import ...

