June 2018
Intermediate to advanced
318 pages
9h 24m
English
Now we will look at another policy optimization algorithm called Proximal Policy Optimization (PPO). It acts as an improvement to TRPO and has become the default RL algorithm of choice in solving many complex RL problems due to its performance. It was proposed by researchers at OpenAI for overcoming the shortcomings of TRPO. Recall the surrogate objective function of TRPO. It is a constraint optimization problem where we impose a constraint—that average KL divergence between the old and new policy should be less than 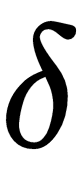 . But the problem with TRPO is that it requires a lot of computing power for computing conjugate ...
. But the problem with TRPO is that it requires a lot of computing power for computing conjugate ...
Read now
Unlock full access






