September 2013
Intermediate to advanced
398 pages
10h 52m
English
The emergence and the fast growth of the web performance optimization (WPO) industry within the past few years is a telltale sign of the growing importance and demand for speed and faster user experiences by the users. And this is not simply a psychological need for speed in our ever accelerating and connected world, but a requirement driven by empirical results, as measured with respect to the bottom-line performance of the many online businesses:
Faster sites lead to better user engagement.
Faster sites lead to better user retention.
Faster sites lead to higher conversions.
Simply put, speed is a feature. And to deliver it, we need to understand the many factors and fundamental limitations that are at play. In this chapter, we will focus on the two critical components that dictate the performance of all network traffic: latency and bandwidth (Figure 1-1).
The time from the source sending a packet to the destination receiving it
Maximum throughput of a logical or physical communication path
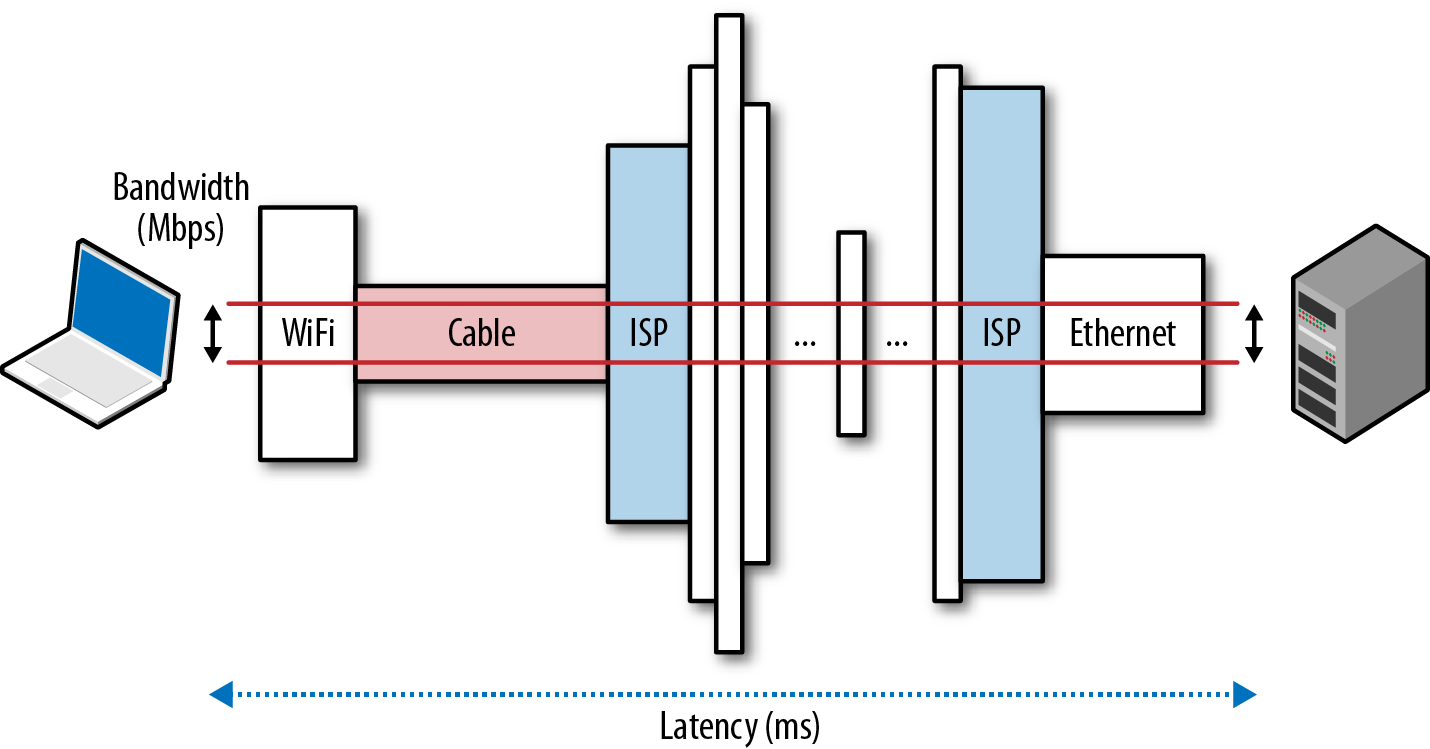
Armed with a better understanding of how bandwidth and latency work together, we will then have the tools to dive deeper into the internals and performance characteristics of TCP, UDP, and all application protocols above them.
Read now
Unlock full access






