Chapter 1. IBM Tivoli Netcool Service Quality Manager 7
necessary conversion and calculation of the source data into performance
indicator information.
Data mediation is typically an extraction transformation and loading (ETL)
process. It extracts data from the source, transforms it into the target format, and
loads the data into a persistent storage (database). A data mediation gateway
collects information from a vendor specific device manager and gets raw data.
The raw data is formatted into a vendor neutral PIF format and then transformed
into the final CSV format as required by the adapter. The PIF files are temporary
files that are used in the intermediate processing stages within the gateway.
1.4.1 Extract Transform Load process
The overall process is an ETL process. This section describes the individual
stages.
Extract
The first part of an ETL process is to extract the data from the source. Most data
mediation projects consolidate data from several different sources. Each source
may have different data formats. Extraction converts the data into a format for
transformation processing.
An intrinsic part of the extraction is parsing of the extracted data, where the data
is checked to see if it meets the expected pattern or structure; if not, the data can
be rejected at this point.
The extract of the data is the beginning of the ETL process. This is where data is
read and retrieved from source systems to a temporary transitional location, or a
final location for further processing. A transfer may take place using different
methods, such as a copy from a local server or through a transfer protocol (ftp,
rcp, or scp) from a remote server.
There are two forms of how extraction could occur:
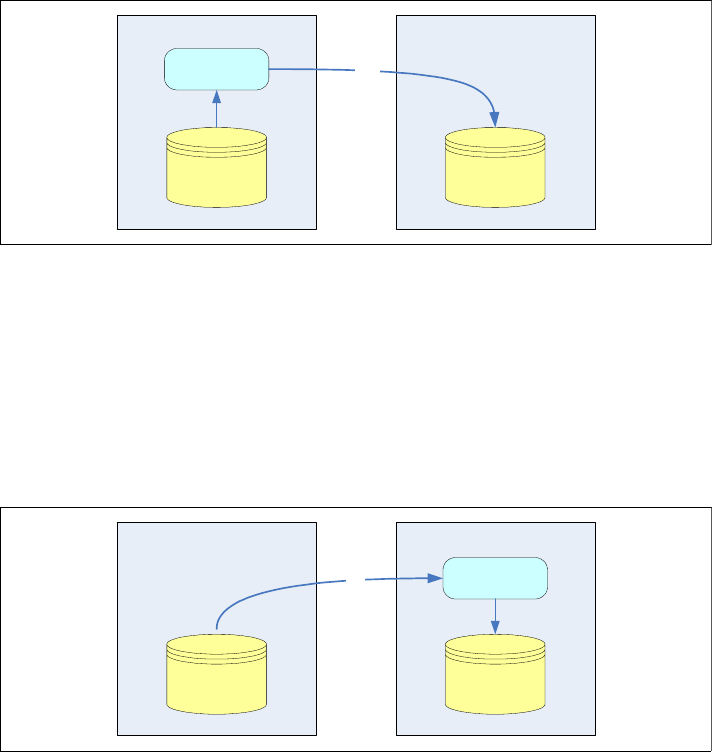
Push
The data at the source location is extracted usually at the source server and
transferred to the destination location. In this case, the process that performs
the extract is running on the source server. Normally this happens in a
situation when access to the source location is not permitted or to prevent
additional server load at the destination.
8 IBM Tivoli Netcool Service Quality Manager Data Mediation Gateway Development
Figure 1-3 shows the general idea of a push extract mechanism.
Figure 1-3 Push extraction
Pull
For a pull extraction, the data extract mechanism take place at the destination
location and is downloaded from the destination location. The process
performing the extract runs on the destination server instead. Generally, a pull
extraction is ideal when a single point of reference for management is
preferred. Figure 1-4 shows an illustration of how a pull extraction mechanism
occurs.
Figure 1-4 Pull extraction
Transform
With the data extracted from the source, the next phase is to modify the source
data format and manipulate it depending on the specific requirements of the
target application. To achieve this process, we perform data transformation.
The transform stage applies a series of rules or functions to the extracted data to
derive data that will be loaded in the end format. Some data sets may require
little or no manipulation. In other cases, one or more of the following
transformation types may be needed to meet the business requirements or
Data source server
Data source
Destination server
Destination
location
Push
extraction
Push
Data source server
Data source
Destination server
Destination
location
Pull
extraction
Pull
Get IBM Tivoli Netcool Service Quality Manager Data Mediation Gateway Development now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

