48Obstacles and Maneuvers
The formulaic methods for scaled data in Parts II, III, and IV assume that sample data itself is normally distributed, or fairly close to it. And while this assumption is often warranted, sometimes it is not. The statistical scenario—unruly data is a case in point. That data harbors two nonnormal traits that are common obstacles to using the statistical analysis methods we've seen so far for scaled data.
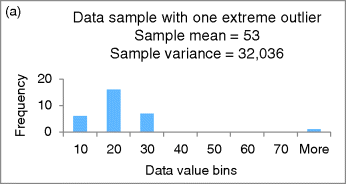
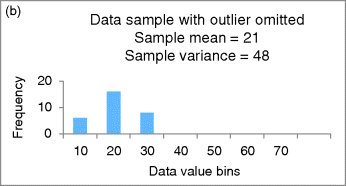
The first obstacle, as you know, are outliers. Figure 48.2a shows the impact of one extreme outlier in a sample of size 30 (the outlier value of 1000 shows up as a little nub in the “More” slot). Figure 48.2b shows the data with the outlier removed. Notice the large impact the outlier has on the sample mean and the even larger impact it has on the sample variance that in turn will wreak havoc on various other sample statistics, confidence intervals, and significance tests.
Statistical ...
Get Illuminating Statistical Analysis Using Scenarios and Simulations now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

