Statistical Experiments and Significance Testing
The design of experiments is a cornerstone of the practice of statistics, with applications in virtually all areas of research. The goal is to design an experiment in order to confirm or reject a hypothesis. Data scientists are faced with the need to conduct continual experiments, particularly regarding user interface and product marketing. This lesson reviews traditional experimental design and discusses issues commonly faced in data science. It also covers some oft-cited concepts in statistical inference and explains their meaning and relevance (or lack of relevance) to data science.
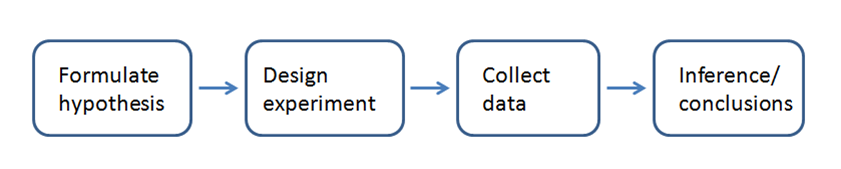
Whenever you see reference to statistical significance, t-tests, or p-values, it is typically in the context of the classical statistical inference âpipeline.â This process starts with a hypothesis (âdrug A is better than the existing standard drug,â âprice A is more profitable than the existing price Bâ). An experiment (it might be an A-B test) is designed to test the hypothesisâdesigned in such a way that, hopefully, the results will be conclusive. Data are collected and analyzed, then a conclusion is drawn. The term inference reflects the intention to apply the experiment results, which involve a limited set of data, to a larger process or population.
A-B Testing
An A-B test is an experiment with two groups to establish which of ...
Get Improve the outcome of your data experiments with A-B testing now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

