In the backpropagation method, neural networks are trained through the gradient descent technique, where the combined weights vector, W, is updated iteratively, as follows:
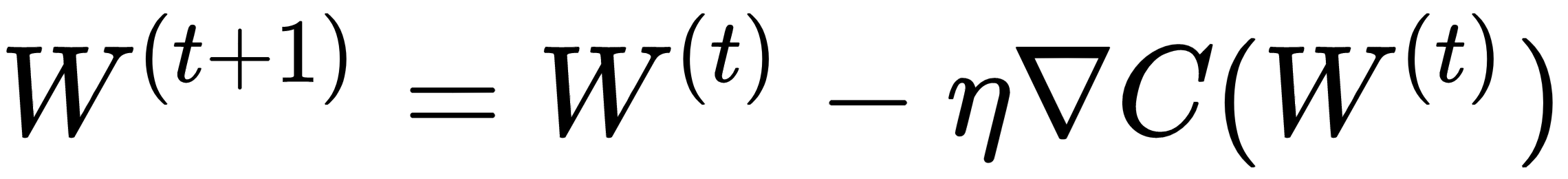
Here, η is the learning rate, W(t+1) and W(t) are the weight vectors at iterations (t+1) and (t), respectively, and ∇C(W(t)) is the gradient of the cost function or the error function, with respect to the weight vector, W, at iteration (t). The previous algorithm for an individual weight or bias generalized by w ∈ W can be represented as follows:
As you can gather from the previous expressions, the heart of the gradient ...

