We will now look at a popular reinforcement learning algorithm, called Q-learning. Q-learning is used to determine an optimal action selection policy for a given finite Markov decision process. A Markov decision process is defined by a state space, S; an action space, A; an immediate rewards set, R; a probability of the next state, S(t+1), given the current state, S(t); a current action, a(t); P(S(t+1)/S(t);r(t)); and a discount factor, 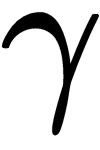 . The following diagram illustrates a Markov decision process, where the next state is dependent on the current state and any actions taken in the current state:
. The following diagram illustrates a Markov decision process, where the next state is dependent on the current state and any actions taken in the current state:
Figure 1.16: A Markov decision process ...

