Chapter 4. Service Resiliency
Remember that your services and applications will be communicating over unreliable networks. In the past, developers have often tried to use frameworks (EJBs, CORBA, RMI, etc.) to simply make network calls appear like local method invocations. This gave developers a false peace of mind. Without ensuring the application actively guarded against network failures, the entire system was susceptible to cascading failures. Therefore, you should never assume that a remote dependency that your application or microservice is accessing across a network is guaranteed to respond with a valid payload nor within a particular timeframe (or, at all; as Douglas Adams, author of The Hitchhiker’s Guide to the Galaxy, once said: “A common mistake that people make when trying to design something completely foolproof is to underestimate the ingenuity of complete fools”). You do not want the misbehavior of a single service to become a catastrophic failure that hamstrings your business objectives.
Istio comes with many capabilities for implementing resilience within applications, but just as we noted earlier, the actual enforcement of these capabilities happens in the sidecar. This means that the resilience features listed here are not targeted toward any specific programming language/runtime; they’re applicable regardless of library or framework you choose to write your service:
- Client-side load balancing
-
Istio augments Kubernetes out-of-the-box load balancing.
- Timeout
-
Wait only N seconds for a response and then give up.
- Retry
-
If one pod returns an error (e.g., 503), retry for another pod.
- Simple circuit breaker
-
Instead of overwhelming the degraded service, open the circuit and reject further requests.
- Pool ejection
-
This provides auto removal of error-prone pods from the load-balancing pool.
Let’s look at each capability with an example. Here, we use the same set of services of customer, preference, and recommendation as in the previous chapters.
Load Balancing
A core capability for increasing throughput and lowering latency is load balancing. A straightforward way to implement this is to have a centralized load balancer with which all clients communicate and that knows how to distribute load to any backend systems. This is a great approach, but it can become both a bottleneck as well as a single point of failure. Load-balancing capabilities can be distributed to clients with client-side load balancers. These client load balancers can use sophisticated, cluster-specific, load-balancing algorithms to increase availability, lower latency, and increase overall throughput. The Istio proxy has the capabilities to provide client-side load balancing through the following configurable algorithms:
- ROUND_ROBIN
-
This algorithm evenly distributes the load, in order, across the endpoints in the load-balancing pool.
- RANDOM
-
This evenly distributes the load across the endpoints in the load-balancing pool but without any order.
- LEAST_CONN
-
This algorithm picks two random hosts from the load-balancing pool and determines which host has fewer outstanding requests (of the two) and sends to that endpoint. This is an implementation of weighted least request load balancing.
In the previous chapters on routing, you saw the use of DestinationRules and VirtualServices to control how traffic is routed to specific pods. In this chapter, we show you how to control the behavior of communicating with a particular pod using DestinationRule rules. To begin, we discuss how to configure load balancing with Istio DestinationRule rules.
First, make sure there are no DestinationRules that might interfere with how traffic is load balanced across v1 and v2 of our recommendation service. You can delete all DestinationRules and VirtualServices like this:
oc delete virtualservice --all -n tutorial oc delete destinationrule --all -n tutorial
Next, you can scale up the recommendation service replicas to 3:
oc scale deployment recommendation-v2 --replicas=3 -n tutorial
Wait a moment for all containers to become healthy and ready for traffic. Now, send traffic to your cluster using the same script you used earlier:
#!/bin/bash while true do curl customer-tutorial.$(minishift ip).nip.io sleep .1 done
You should see a round-robin-style distribution of load based on the outputs:
customer => ... => recommendation v1 from '99634814': 1145 customer => ... => recommendation v2 from '6375428941': 1 customer => ... => recommendation v2 from '4876125439': 1 customer => ... => recommendation v2 from '2819441432': 181 customer => ... => recommendation v1 from '99634814': 1146 customer => ... => recommendation v2 from '6375428941': 2 customer => ... => recommendation v2 from '4876125439': 2 customer => ... => recommendation v2 from '2819441432': 182 customer => ... => recommendation v1 from '99634814': 1147
Now, change the load-balancing algorithm to RANDOM. Here’s what the Istio DestinationRule would look like for that:
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
name: recommendation
namespace: tutorial
spec:
host: recommendation
trafficPolicy:
loadBalancer:
simple: RANDOM
This destination policy configures traffic to the recommendation service to be sent using a random load-balancing algorithm.
Let’s create this DestinationRule:
oc -n tutorial create -f \ istiofiles/destination-rule-recommendation_lb_policy_app.yml
You should now see a more random distribution when you call your service:
customer => ... => recommendation v2 from '2819441432': 183 customer => ... => recommendation v2 from '6375428941': 3 customer => ... => recommendation v2 from '2819441432': 184 customer => ... => recommendation v1 from '99634814': 1153 customer => ... => recommendation v1 from '99634814': 1154 customer => ... => recommendation v2 from '2819441432': 185 customer => ... => recommendation v2 from '6375428941': 4 customer => ... => recommendation v2 from '6375428941': 5 customer => ... => recommendation v2 from '2819441432': 186 customer => ... => recommendation v2 from '4876125439': 3
Because you’ll be creating more DestinationRules throughout the remainder of this chapter, now is a good time to clean up:
oc -n tutorial delete -f \ istiofiles/destination-rule-recommendation_lb_policy_app.yml oc scale deployment recommendation-v2 --replicas=1 -n tutorial
Timeout
Timeouts are a crucial component for making systems resilient and available. Calls to services over a network can result in lots of unpredictable behavior, but the worst behavior is latency. Did the service fail? Is it just slow? Is it not even available? Unbounded latency means any of those things could have happened. But what does your service do? Just sit around and wait? Waiting is not a good solution if there is a customer on the other end of the request. Waiting also uses resources, causes other systems to potentially wait, and is usually a significant contributor to cascading failures. Your network traffic should always have timeouts in place, and you can use Istio service mesh to do this.
If you look at your recommendation service, find the RecommendationVerticle.java class and uncomment the line that introduces a delay in the service.
public void start() throws Exception {
Router router = Router.router(vertx);
router.get("/").handler(this::timeout); // adds 3 secs
router.get("/").handler(this::logging);
router.get("/").handler(this::getRecommendations);
router.get("/misbehave").handler(this::misbehave);
router.get("/behave").handler(this::behave);
vertx.createHttpServer().requestHandler(router::accept)
.listen(LISTEN_ON);
}
You should save your changes before continuing and then build the service and deploy it:
cd recommendation/java/vertx mvn clean package docker build -t example/recommendation:v2 . oc delete pod -l app=recommendation,version=v2 -n tutorial
The last step here is to restart the v2 pod with the latest image of your recommendation service. Now, if you call your customer service endpoint, you should experience the delay when the call hits the registration v2 service:
time curl customer-tutorial.$(minishift ip).nip.io
customer => preference => recommendation v2 from
'2819441432': 202
real 0m3.054s
user 0m0.003s
sys 0m0.003s
You might need to make the call a few times for it to route to the v2 service. The v1 version of recommendation does not have the delay as it is based on the v1 variant of the code.
Let’s look at your VirtualService that introduces a rule that imposes a timeout when making calls to the recommendation service:
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
creationTimestamp: null
name: recommendation
namespace: tutorial
spec:
hosts:
- recommendation
http:
- route:
- destination:
host: recommendation
timeout: 1.000s
You create this VirtualService with the following command:
oc -n tutorial create -f \ istiofiles/virtual-service-recommendation-timeout.yml
Now when you send traffic to your customer service, you should see either a successful request (if it was routed to v1 of recommendation) or a 504 upstream request timeout error if routed to v2:
time curl customer-tutorial.$(minishift ip).nip.io customer => 503 preference => 504 upstream request timeout real 0m1.151s user 0m0.003s sys 0m0.003s
You can clean up by deleting the VirtualService:
oc delete virtualservice recommendation -n tutorial
Retry
Because you know the network is not reliable you might experience transient, intermittent errors. This can be even more pronounced with distributed microservices rapidly deploying several times a week or even a day. The service or pod might have gone down only briefly. With Istio’s retry capability, you can make a few more attempts before having to truly deal with the error, potentially falling back to default logic. Here, we show you how to configure Istio to do this.
The first thing you need to do is simulate transient network errors. In the recommendation service example, you find a special endpoint that simply sets a flag; this flag indicates that the return value of getRecommendations should always be a 503. To change the misbehave flag to true, exec into the v2 pod and invoke its localhost:8080/misbehave endpoint:
oc exec -it $(oc get pods|grep recommendation-v2 \
|awk '{ print $1 }'|head -1) -c recommendation /bin/bash
curl localhost:8080/misbehave
Now when you send traffic to the customer service, you should see some 503 errors:
#!/bin/bash while true do curl customer-tutorial.$(minishift ip).nip.io sleep .1 done customer => preference => recommendation v1 from '99634814': 200 customer => 503 preference => 503 misbehavior from '2819441432'
Let’s look at a VirtualService that specifies the retry configuration:
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: recommendation
namespace: tutorial
spec:
hosts:
- recommendation
http:
- route:
- destination:
host: recommendation
retries:
attempts: 3
perTryTimeout: 2s
This rule sets your retry attempts to 3 and will use a 2s timeout for each retry. The cumulative timeout is therefore 6 seconds plus the time of the original call.
Let’s create your retry rule and try the traffic again:
oc -n tutorial create -f \ istiofiles/virtual-service-recommendation-v2_retry.yml
Now when you send traffic, you shouldn’t see any errors. This means that even though you are experiencing 503s, Istio is automatically retrying the request, as shown here:
customer => preference => recommendation v1 from '99634814': 35 customer => preference => recommendation v1 from '99634814': 36 customer => preference => recommendation v1 from '99634814': 37 customer => preference => recommendation v1 from '99634814': 38
Now you can clean up all the rules you’ve installed:
oc delete destinationrules --all -n tutorial oc delete virtualservices --all -n tutorial
And bounce/restart the recommendation-v2 pod so that the misbehave flag is reset to false:
oc delete pod -l app=recommendation,version=v2
Circuit Breaker
Much like the electrical safety mechanism in the modern home (we used to have fuse boxes, and “blew a fuse” is still part of our vernacular), the circuit breaker ensures that any specific appliance does not overdraw electrical current through a particular outlet. If you’ve ever lived with someone who plugged their radio, hair dryer, and perhaps a portable heater into the same circuit, you have likely seen this in action. The overdraw of current creates a dangerous situation because you can overheat the wire, which can result in a fire. The circuit breaker opens and disconnects the electrical current flow.
Note
The concepts of the circuit breaker and bulkhead for software systems were first proposed in the book by Michael Nygard titled Release It! (Pragmatic Bookshelf), now in its second edition.
The patterns of circuit breaker and bulkhead were popularized with the release of Netflix’s Hystrix library in 2012. The Netflix libraries such as Eureka (service discovery), Ribbon (load balancing), and Hystrix (circuit breaker and bulkhead) rapidly became very popular as many folks in the industry also began to focus on microservices and cloud native architecture. Netflix OSS was built before there was a Kubernetes/OpenShift, and it does have some downsides: one, it is Java-only, and two, it requires the application developer to use the embedded library correctly. Figure 4-1 provides a timeline, from when the software industry attempted to break up monolithic application development teams and massive multimonth waterfall workflows, to the birth of Netflix OSS and the coining of the term microservices.
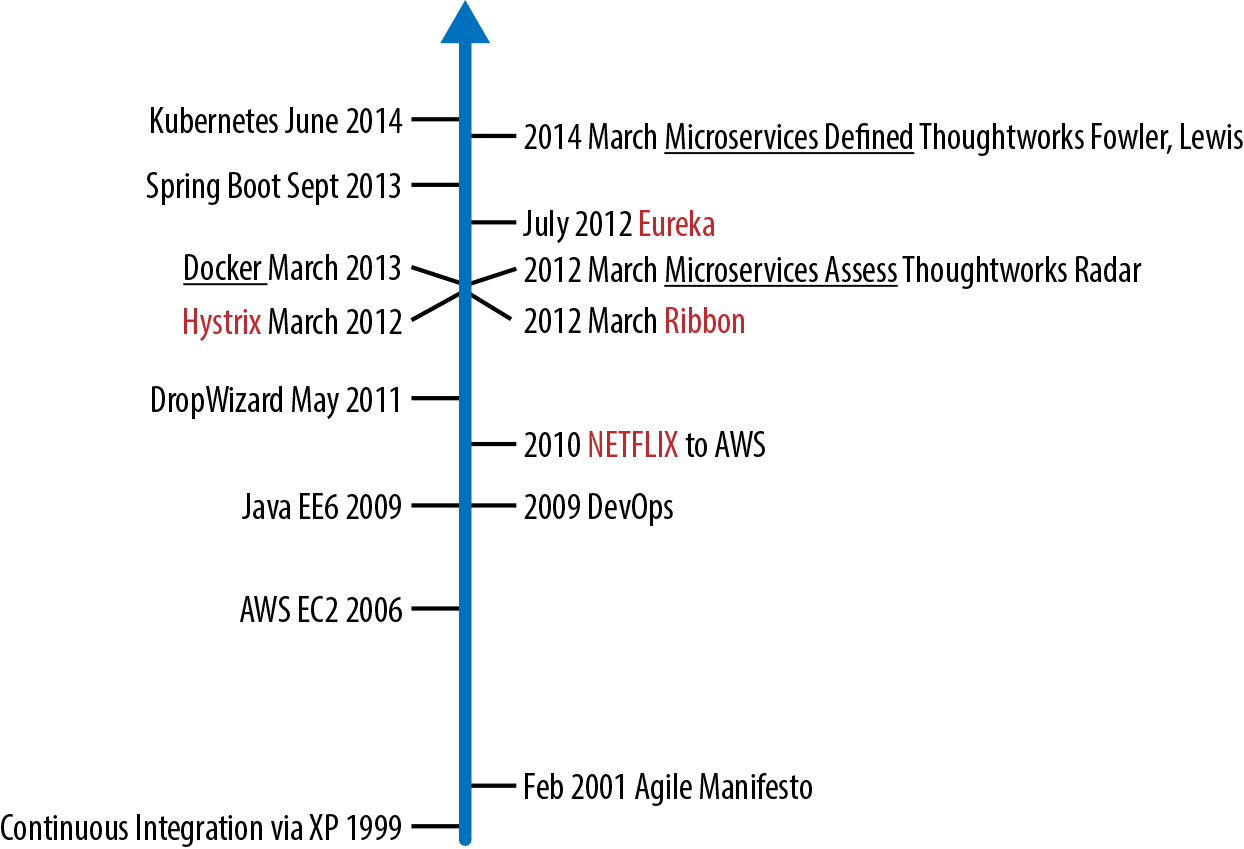
Figure 4-1. Microservices timeline
Istio puts more of the resilience implementation into the infrastructure so that you can focus more of your valuable time and energy on code that differentiates your business from the ever-growing competitive field.
Istio implements circuit breaking at the connection-pool level and at the load-balancing host level. We’ll show you examples of both.
To explore the connection-pool circuit breaking, prepare by ensuring the recommendation v2 service has the 3s timeout enabled (from the previous section). The RecommendationVerticle.java file should look similar to this:
Router router = Router.router(vertx);
router.get("/").handler(this::logging);
router.get("/").handler(this::timeout); // adds 3 secs
router.get("/").handler(this::getRecommendations);
router.get("/misbehave").handler(this::misbehave);
router.get("/behave").handler(this::behave);
You will route traffic to both v1 and v2 of recommendation using this Istio DestinationRule:
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
creationTimestamp: null
name: recommendation
namespace: tutorial
spec:
host: recommendation
subsets:
- labels:
version: v1
name: version-v1
- labels:
version: v2
name: version-v2
Create this v1 and v2 DestinationRule with the following command:
oc -n tutorial create -f \ istiofiles/destination-rule-recommendation-v1-v2.yml
And create the VirtualService with:
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
creationTimestamp: null
name: recommendation
namespace: tutorial
spec:
hosts:
- recommendation
http:
- route:
- destination:
host: recommendation
subset: version-v1
weight: 50
- destination:
host: recommendation
subset: version-v2
weight: 50
Create the 50/50 VirtualService with the following command:
oc -n tutorial create -f \ istiofiles/virtual-service-recommendation-v1_and_v2_50_50.yml
From the initial installation instructions, we recommend you install the Siege command-line tool. You can use this for load testing with a simple command-line interface (CLI).
We will use 20 clients sending two requests each (concurrently). Use the following command to do so:
siege -r 2 -c 20 -v customer-tutorial.$(minishift ip).nip.io
You should see output similar to this:
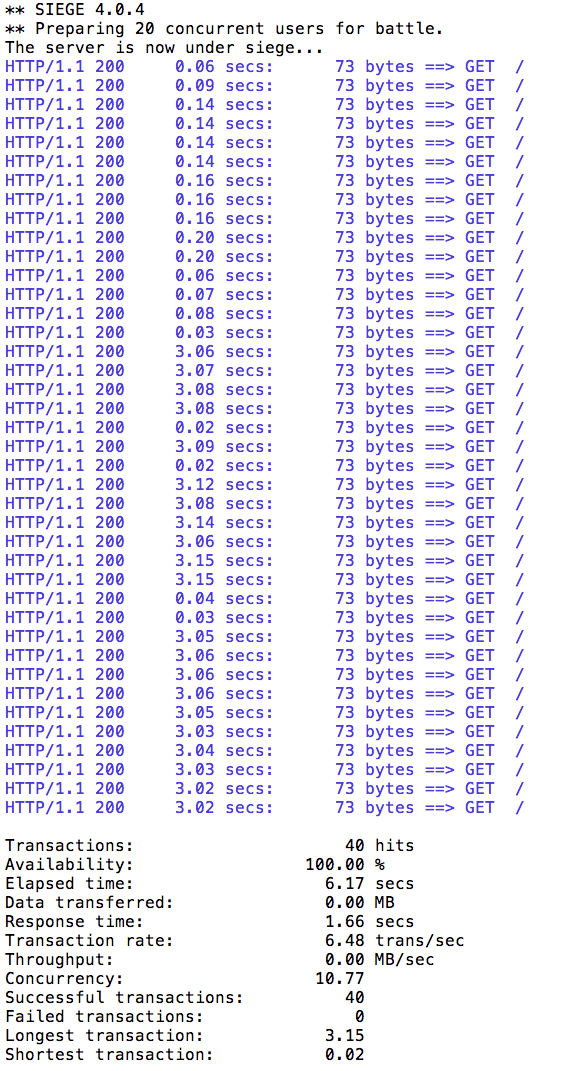
All the requests to the application were successful, but it took some time to run the test because the v2 pod was a slow performer.
Suppose that in a production system this 3-second delay was caused by too many concurrent requests to the same instance or pod. You don’t want multiple requests getting queued or making that instance or pod even slower. So, we’ll add a circuit breaker that will open whenever you have more than one request being handled by any instance or pod.
To create circuit breaker functionality for our services, we use an Istio DestinationRule that looks like this:
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
creationTimestamp: null
name: recommendation
namespace: tutorial
spec:
host: recommendation
subsets:
- name: version-v1
labels:
version: v1
- name: version-v2
labels:
version: v2
trafficPolicy:
connectionPool:
http:
http1MaxPendingRequests: 1
maxRequestsPerConnection: 1
tcp:
maxConnections: 1
outlierDetection:
baseEjectionTime: 120.000s
consecutiveErrors: 1
interval: 1.000s
maxEjectionPercent: 100
Here, you’re configuring the circuit breaker for any client calling into v2 of the recommendation service. Remember in the previous VirtualService that you are splitting (50%) traffic between both v1 and v2, so this DestinationRule should be in effect for half the traffic. You are limiting the number of connections and number of pending requests to one. (We discuss the other settings in “Pool Ejection”, in which we look at outlier detection.) Let’s create this circuit breaker policy:
oc -n tutorial replace -f \
istiofiles/destination-rule-recommendation_cb_policy_
version_v2.yml
Now try the siege load generator one more time:
siege -r 2 -c 20 -v customer-tutorial.$(minishift ip).nip.io
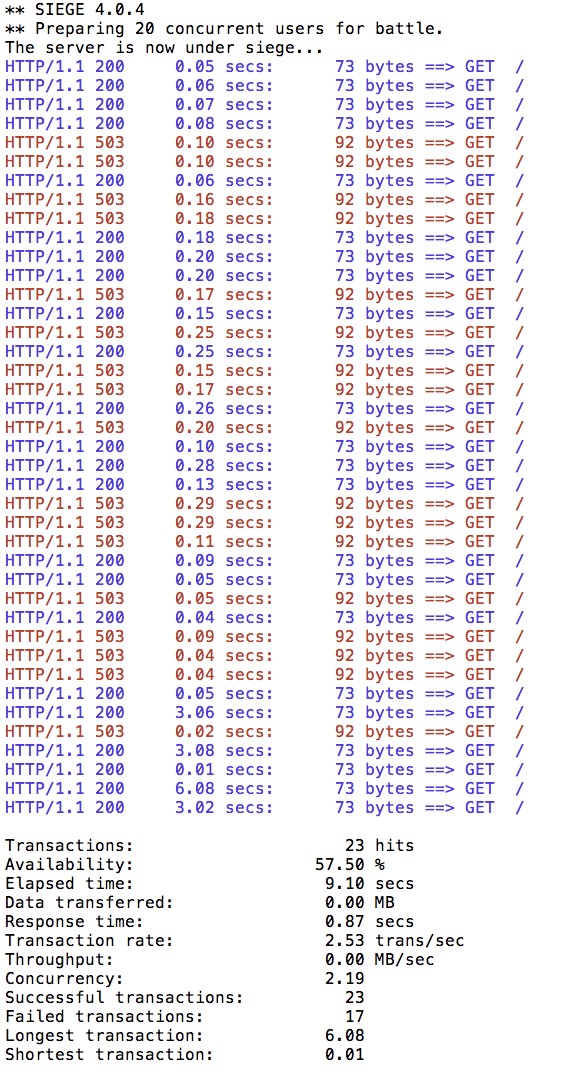
You can now see that almost all calls completed in less than a second with either a success or a failure. You can try this a few times to see that this behavior is consistent. The circuit breaker will short circuit any pending requests or connections that exceed the specified threshold (in this case, an artificially low number, 1, to demonstrate these capabilities). The goal of the circuit breaker is to fail fast.
You can clean up these Istio rules with a simple “oc delete”:
oc delete virtualservice recommendation -n tutorial oc delete destinationrule recommendation -n tutorial
Pool Ejection
The last of the resilience capabilities that we discuss has to do with identifying badly behaving cluster hosts and not sending any more traffic to them for a cool-off period (essentially kicking the bad-behaving pod out of the load-balancing pool). Because the Istio proxy is based on Envoy and Envoy calls this implementation outlier detection, we’ll use the same terminology for discussing Istio.
In a scenario where your software development teams are deploying their components into production, perhaps multiple times per week, during the middle of the workday, being able to kick out misbehaving pods adds to overall resiliency. Pool ejection or outlier detection is a resilience strategy that is valuable whenever you have a group of pods (multiple replicas) to serve a client request? If the request is forwarded to a certain instance and it fails (e.g., returns a 50x error code), Istio will eject this instance from the pool for a certain sleep window. In our example, the sleep window is configured to be 15s. This increases the overall availability by making sure that only healthy pods participate in the pool of instances.
First, you need to ensure that you have a DestinationRule and VirtualService in place. Let’s use a 50/50 split of traffic:
oc -n tutorial create -f \ istiofiles/destination-rule-recommendation-v1-v2.yml oc -n tutorial create -f \ istiofiles/virtual-service-recommendation-v1_and_v2_50_50.yml
Next, you can scale the number of pods for the v2 deployment of recommendation so that you have multiple instances in the load-balancing pool with which to work:
oc scale deployment recommendation-v2 --replicas=2 -n tutorial
Wait a moment for all of the pods to get to the ready state then generate some traffic against the customer service:
#!/bin/bash while true do curl customer-tutorial.$(minishift ip).nip.io sleep .1 done
You will see the load balancing 50/50 between the two different versions of the recommendation service. And within version v2, you will also see that some requests are handled by one pod and some requests are handled by the other pod:
customer => ... => recommendation v1 from '99634814': 448 customer => ... => recommendation v2 from '3416541697': 27 customer => ... => recommendation v1 from '99634814': 449 customer => ... => recommendation v1 from '99634814': 450 customer => ... => recommendation v2 from '2819441432': 215 customer => ... => recommendation v1 from '99634814': 451 customer => ... => recommendation v2 from '3416541697': 28 customer => ... => recommendation v2 from '3416541697': 29 customer => ... => recommendation v2 from '2819441432': 216
To test outlier detection, you’ll want one of the pods to misbehave. Find one of them and exec to it and instruct it to misbehave:
oc get pods -l app=recommendation,version=v2
You should see something like this:
recommendation-v2-2819441432 2/2 Running 0 1h recommendation-v2-3416541697 2/2 Running 0 7m
Now you can get into one of the pods and add some erratic behavior to it. Get one of the pod names from your system and run the following command:
oc -n tutorial exec -it \ recommendation-v2-3416541697 -c recommendation /bin/bash
You will be inside the application container of your pod recommendation-v2-3416541697. Now execute a simple curl command and then exit:
curl localhost:8080/misbehave exit
This is a special endpoint that will make our application return only 503s:
#!/bin/bash while true do curl customer-tutorial.$(minishift ip).nip.io sleep .1 done
You’ll see that whenever the pod recommendation-v2-3416541697 receives a request, you get a 503 error:
customer => ... => recommendation v1 from '2039379827': 495 customer => ... => recommendation v2 from '2036617847': 248 customer => ... => recommendation v1 from '2039379827': 496 customer => ... => recommendation v1 from '2039379827': 497 customer => 503 preference => 503 misbehavior from '3416541697' customer => ... => recommendation v2 from '2036617847': 249 customer => ... => recommendation v1 from '2039379827': 498 customer => 503 preference => 503 misbehavior from '3416541697'
Now let’s see what happens when you configure Istio to eject misbehaving hosts. Look at the DestinationRule in the following:
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
creationTimestamp: null
name: recommendation
namespace: tutorial
spec:
host: recommendation
subsets:
- labels:
version: v1
name: version-v1
trafficPolicy:
connectionPool:
http: {}
tcp: {}
loadBalancer:
simple: RANDOM
outlierDetection:
baseEjectionTime: 15.000s
consecutiveErrors: 1
interval: 5.000s
maxEjectionPercent: 100
- labels:
version: v2
name: version-v2
trafficPolicy:
connectionPool:
http: {}
tcp: {}
loadBalancer:
simple: RANDOM
outlierDetection:
baseEjectionTime: 15.000s
consecutiveErrors: 1
interval: 5.000s
maxEjectionPercent: 100
In this DestinationRule, you’re configuring Istio to check every 5 seconds for misbehaving pods and to remove those pods from the load-balancing pool after one consecutive error (artificially low for this example) and keep it out for 15 seconds:
oc -n tutorial replace -f
istiofiles/destination-rule-recommendation_cb_policy_pool
_ejection.yml
Let’s put some load on the service now and see its behavior:
#!/bin/bash while true do curl customer-tutorial.$(minishift ip).nip.io sleep .1 Done
You will see that whenever you get a failing request with 503 from the pod recommendation-v2-3416541697, it is ejected from the pool and doesn’t receive more requests until the sleep window expires, which takes at least 15 seconds:
customer => ... => recommendation v1 from '2039379827': 509 customer => 503 preference => 503 misbehavior from '3416541697' customer => ... => recommendation v1 from '2039379827': 510 customer => ... => recommendation v1 from '2039379827': 511 customer => ... => recommendation v1 from '2039379827': 512 customer => ... => recommendation v2 from '2036617847': 256 customer => ... => recommendation v2 from '2036617847': 257 customer => ... => recommendation v1 from '2039379827': 513 customer => ... => recommendation v2 from '2036617847': 258 customer => ... => recommendation v2 from '2036617847': 259 customer => ... => recommendation v2 from '2036617847': 260 customer => ... => recommendation v1 from '2039379827': 514 customer => ... => recommendation v1 from '2039379827': 515 customer => 503 preference => 503 misbehavior from '3416541697' customer => ... => recommendation v1 from '2039379827': 516 customer => ... => recommendation v2 from '2036617847': 261
Combination: Circuit Breaker + Pool Ejection + Retry
Even with pool ejection your application still does not look that resilient, probably because you are still letting some errors be propagated to your clients. But you can improve this. If you have enough instances or versions of a specific service running in your system, you can combine multiple Istio capabilities to achieve the ultimate backend resilience:
-
Circuit breaker, to avoid multiple concurrent requests to an instance
-
Pool ejection, to remove failing instances from the pool of responding instances
-
Retries, to forward the request to another instance just in case you get an open circuit breaker or pool ejection
By simply adding a retry configuration to our current VirtualService, we are able to completely get rid of our 503 responses. This means that whenever you receive a failed request from an ejected instance, Istio will forward the request to another healthy instance:
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
creationTimestamp: null
name: recommendation
namespace: tutorial
spec:
hosts:
- recommendation
http:
- retries:
attempts: 3
perTryTimeout: 4.000s
route:
- destination:
host: recommendation
subset: version-v1
weight: 50
- destination:
host: recommendation
subset: version-v2
weight: 50
And replace the VirtualService:
oc -n tutorial replace -f \ istiofiles/virtual-service-recommendation-v1_and_v2_retry.yml
Throw some requests at the customer endpoint:
#!/bin/bash while true do curl customer-tutorial.$(minishift ip).nip.io sleep .1 done
You will no longer receive 503s:
customer => ... => recommendation v1 from '2039379827': 538 customer => ... => recommendation v1 from '2039379827': 539 customer => ... => recommendation v1 from '2039379827': 540 customer => ... => recommendation v2 from '2036617847': 281 customer => ... => recommendation v1 from '2039379827': 541 customer => ... => recommendation v2 from '2036617847': 282 customer => ... => recommendation v1 from '2039379827': 542 customer => ... => recommendation v1 from '2039379827': 543 customer => ... => recommendation v2 from '2036617847': 283 customer => ... => recommendation v2 from '2036617847': 284
Your misbehaving pod recommendation-v2-3416541697 never shows up, thanks to pool ejection and retry.
Clean up by removing the timeout in RecommendationVerticle.java, rebuilding the docker image, deleting the misbehaving pod, and then removing the DestinationRule and VirtualService objects:
cd recommendation/java/vertx mvn clean package docker build -t example/recommendation:v2 . oc scale deployment recommendation-v2 --replicas=1 -n tutorial oc delete pod -l app=recommendation,version=v2 -n tutorial oc delete virtualservice recommendation -n tutorial oc delete destinationrule recommendation -n tutorial
Now that you have seen how to make your service to service calls more resilent and robust, it is time to purposely break things by introducing some chaos in Chapter 5.
Get Introducing Istio Service Mesh for Microservices, 2nd Edition now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

