Chapter 4. Machine Learning and Deep Learning
Machine learning (ML) and deep learning (DL) have emerged as viable technologies for helping organizations progress from deep analytics to predictive analytics by discovering actionable insights in the data. ML/DL models crunch massive datasets and automatically uncover the patterns, anomalies, and relationships needed to make more impactful, data-driven decisions.
But deploying ML within the enterprise presents some challenges. To help overcome these and achieve the full promise of ML, we can use technologies like GPU databases with hardware acceleration, in-memory data management, distributed computing, and integrated open source ML frameworks such as TensorFlow to deliver simpler, converged, and more turnkey solutions.
ML applications have become even easier to implement with the advent of user-defined functions (UDFs). UDFs are able to receive filtered data, perform arbitrary computations, and save the output to a separate table—all in real time on a single database platform. This simplifies and accelerates the entire ML pipeline by unifying the three key processes—data generation, model training, and model serving (as shown in Figure 4-1)—in a single solution that takes advantage of the GPU’s massively parallel processing power to deliver the performance needed.
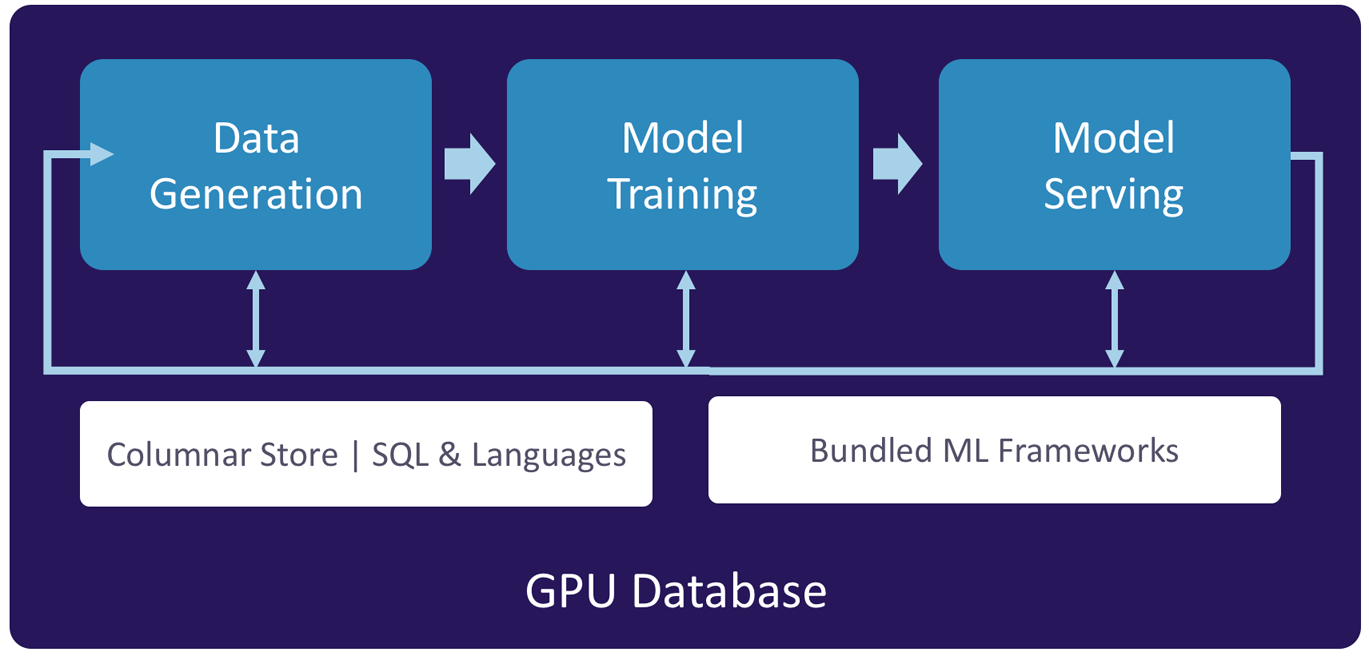
Figure 4-1. GPU databases accelerate the ML pipeline for faster model development and deployment
Data Generation involves acquiring, saving, and preparing datasets to train machine learning models. GPU databases offer advantages in all three data generation tasks:
-
For data acquisition, connectors for data-in-motion and at-rest with high-speed ingest make it easier to acquire millions of rows of data across disparate systems in seconds
-
For data persistence, the ability to store and manage multistructured data types in a single GPU database makes all text, images, spatial and time–series data easily accessible to ML/DL applications
-
For data preparation, the ability to achieve millisecond response times using popular languages like SQL, C++, Java, and Python makes it easier to explore even the most massive datasets
Model training is the most resource-intensive step in the ML pipeline, making it the biggest potential bottleneck. GPU databases with UDFs offer the performance needed to support plug-in custom code and open source ML libraries, such as TensorFlow, Caffe, Torch, and MXNet, for in-line model training. GPU databases maximize performance in three ways:
-
Acceleration—Massively parallel processing makes GPUs well-suited for compute-intensive model training workloads on large datasets; this eliminates the need for data sampling and expensive, resource-intensive tuning, and makes it possible to achieve a performance improvement of 100 times on commodity hardware
-
Distributed, scale-out architecture—Clustered GPU databases distribute data across multiple database shards enabling parallelized model training for better performance; a scale-out architecture makes it easy to add nodes on demand to improve performance and capacity
-
Vector and matrix operations—GPU databases use purpose-built, in-memory data structures and processing optimization to take full advantage of the parallelization available in modern GPUs to deliver an order of magnitude performance improvement on the vector and matrix operations that are common in ML workloads
Model Serving benefits from the ability to operationalize ML by bundling the ML framework(s) and deploying the models in the same GPU database used for data generation and model training, as depicted in Figure 4-2. With such unification, models can be assessed in-line for faster scoring and more accurate predictions.

Figure 4-2. Bundling the ML framework and deploying the models in the GPU database makes model serving an in-line process to help operationalize ML
GPU databases unify data with compute and model management to enable data exploration and preparation at any scale. GPU databases also accelerate model training, facilitate model deployment in production and make it easier to manage the model lifecycle to simplify the core workflows of any ML endeavor.
Get Introduction to GPUs for Data Analytics now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

