Chapter 4. The Operator Framework
There is inevitable complexity in developing an Operator, and in managing its distribution, deployment, and lifecycle. The Red Hat Operator Framework makes it simpler to create and distribute Operators. It makes building Operators easier with a software development kit (SDK) that automates much of the repetitive implementation work. The Framework also provides mechanisms for deploying and managing Operators. Operator Lifecycle Manager (OLM) is an Operator that installs, manages, and upgrades other Operators. Operator Metering is a metrics system that accounts for Operators’ use of cluster resources. This chapter gives an overview of these three key parts of the Framework to prepare you to use those tools to build and distribute an example Operator. Along the way, you’ll install the operator-sdk command-line tool, the primary interface to SDK features.
Operator Framework Origins
The Operator SDK builds atop the Kubernetes controller-runtime, a set of libraries providing essential Kubernetes controller routines in the Go programming language. As part of the Operator Framework, the SDK provides integration points for distributing and managing Operators with OLM, and measuring them with Operator Metering. The SDK and the entire Red Hat Operator Framework are open source with contributors from throughout the community and other organizations, and are in the process of being donated to the vendor-neutral Cloud Native Computing Foundation, home to Kubernetes itself and many other related projects.
Operator Maturity Model
The Operator Maturity Model, depicted in Figure 4-1, sketches a way to think about different levels of Operator functionality. You can begin with a minimum viable product that installs its operand, then add lifecycle management and upgrade capabilities, iterating over time toward complete automation for your application.
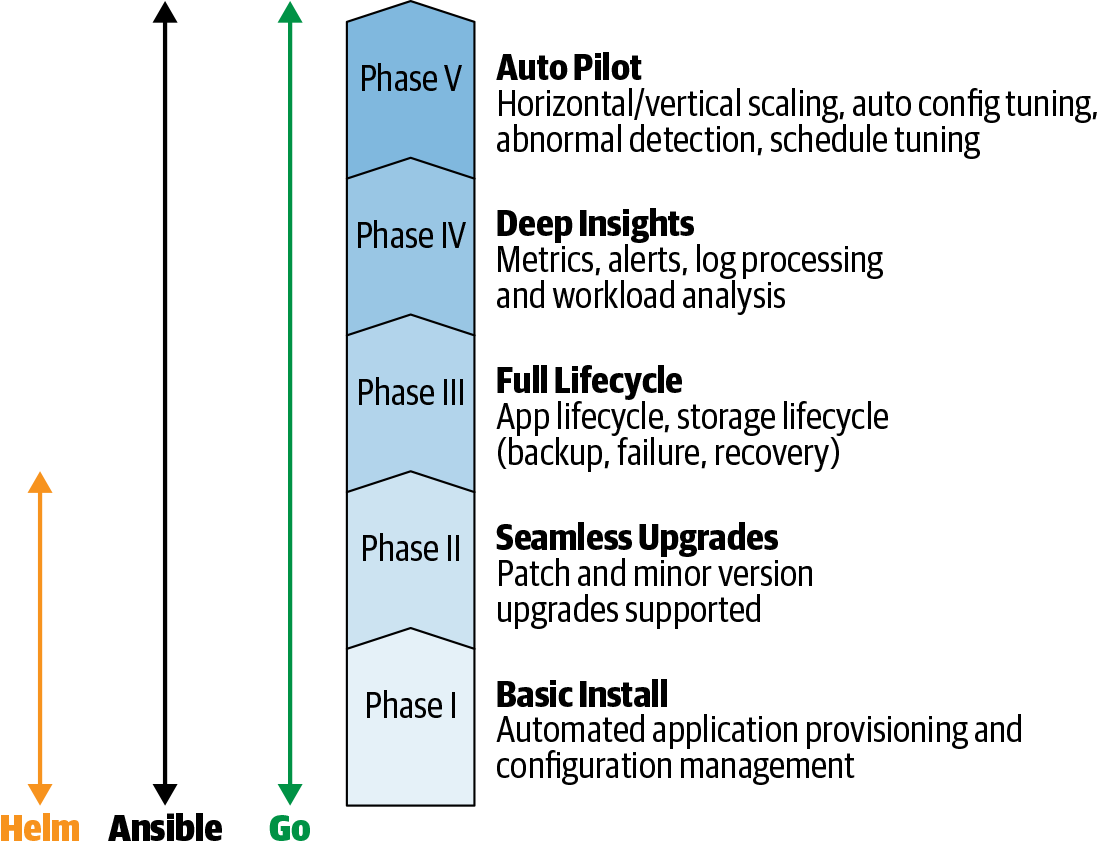
Figure 4-1. Operator Maturity Model
An Operator can have humble origins and grow in sophistication over a series of development cycles. The first phase of the model requires just enough application-specific code to create any resources the operand requires. In other words, phase one is the prepared, automated installation of an application.
Operator SDK
The Operator SDK is a set of tools for scaffolding, building, and preparing an Operator for deployment. The SDK currently includes first-class support for constructing Operators in the Go programming language, with support for other languages planned. The SDK also offers what might be described as an adapter architecture for Helm charts or Ansible playbooks. We’ll cover these Adapter Operators in Chapter 6. In Chapter 7 we will show how to implement application-specific management routines in Go to build a custom Operator with the SDK tool.
Installing the Operator SDK Tool
The Operator SDK centers around a command-line tool, operator-sdk, that helps you build Operators. The SDK imposes a standard project layout, and in return creates skeletal Go source code for the basic Kubernetes API controller implementation and placeholders for your application-specific handlers. From there, the SDK provides convenience commands for building an Operator and wrapping it in a Linux container, generating the YAML-format Kubernetes manifests needed to deploy the Operator on Kubernetes clusters.
Binary installation
To install a binary for your operating system, download operator-sdk from the Kubernetes SDK repository, make it executable, and move it into a directory in your $PATH. The program is statically linked, so it’s ready to run on those platforms for which a release is available. At the time of this writing, the project supplies builds for macOS and Linux operating systems on the x86-64 architecture.
Tip
With any rapidly evolving project like operator-sdk, it’s a good idea to check the project’s installation instructions for the latest installation method.
Installing from source
To get the latest development version, or for platforms with no binary distribution, build operator-sdk from source. We assume you have git and go installed:
$goget-dgithub.com/operator-framework/operator-sdk$cd$GOPATH/src/github.com/operator-framework/operator-sdk$gitcheckoutmaster$maketidy$makeinstall
A successful build process writes the operator-sdk binary to your $GOPATH/bin directory. Run operator-sdk version to check it is in your $PATH.
These are the two most common and least dependent ways to get the SDK tool. Check the project’s install documentation for other options. The subsequent examples in this book use version series 0.11.x of operator-sdk.
Operator Lifecycle Manager
Operators address the general principle that any application, on any platform, must be acquired, deployed, and managed over time. Operators are themselves Kubernetes applications. While an Operator manages its operand, what manages an Operator?
Operator Lifecycle Manager takes the Operator pattern one level up the stack: it’s an Operator that acquires, deploys, and manages Operators on a Kubernetes cluster. Like an Operator for any application, OLM extends Kubernetes by way of custom resources and custom controllers so that Operators, too, can be managed declaratively, with Kubernetes tools, in terms of the Kubernetes API.
OLM defines a schema for Operator metadata, called the Cluster Service Version (CSV), for describing an Operator and its dependencies. Operators with a CSV can be listed as entries in a catalog available to OLM running on a Kubernetes cluster. Users then subscribe to an Operator from the catalog to tell OLM to provision and manage a desired Operator. That Operator, in turn, provisions and manages its application or service on the cluster.
Based on the description and parameters an Operator provides in its CSV, OLM can manage the Operator over its lifecycle: monitoring its state, taking actions to keep it running, coordinating among multiple instances on a cluster, and upgrading it to new versions. The Operator, in turn, can control its application with the latest automation features for the app’s latest versions.
Operator Metering
Operator Metering is a system for analyzing the resource usage of the Operators running on Kubernetes clusters. Metering analyzes Kubernetes CPU, memory, and other resource metrics to calculate costs for infrastructure services. It can also examine application-specific metrics, such as those required to bill application users based on usage. Metering provides a model for ops teams to map the costs of a cloud service or a cluster resource to the application, namespace, and team consuming it. It’s a platform atop which you can build customized reporting specific to your Operator and the application it manages, helping with three primary activities:
- Budgeting
-
When using Operators on their clusters, teams can gain insight into how infrastructure resources are used, especially in autoscaled clusters or hybrid cloud deployments, helping improve projections and allocations to avoid waste.
- Billing
-
When you build an Operator that provides a service to paying customers, resource usage can be tracked by billing codes or labels that reflect the internal structure of an Operator and application to calculate accurate and itemized bills.
- Metrics aggregation
-
Service usage and metrics can be viewed across namespaces or teams. For example, it can help you analyze the resources consumed by a PostgreSQL database Operator running many database server clusters and very many databases for different teams sharing a large Kubernetes cluster.
Summary
This chapter introduced the three pillars of the Operator Framework: the Operator SDK for building and developing Operators; Operator Lifecycle Manager for distributing, installing, and upgrading them; and Operator Metering for measuring Operator performance and resource consumption. Together these framework elements support the process of making an Operator and keeping it running.
You also installed the operator-sdk tool, so you’re equipped with the primary tool for building Operators. To get started, we’ll first introduce the example application you will construct an Operator to manage, the Visitors Site.
Get Kubernetes Operators now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

