Chapter 1. Introduction
In this introductory chapter, we set the scene for the rest of the book by explaining a few of the core Kubernetes concepts used for designing and implementing container-based cloud-native applications. Understanding these new abstractions, and the related principles and patterns from this book, are key to building distributed applications made automatable by cloud-native platforms.
This chapter is not a prerequisite for understanding the patterns described later. Readers familiar with Kubernetes concepts can skip it and jump straight into the pattern category of interest.
The Path to Cloud Native
The most popular application architecture on the cloud-native platforms such as Kubernetes is the microservices style. This software development technique tackles software complexity through modularization of business capabilities and trading development complexity for operational complexity.
As part of the microservices movement, there is a significant amount of theory and supplemental techniques for creating microservices from scratch or for splitting monoliths into microservices. Most of these practices are based on the Domain-Driven Design book by Eric Evans (Addison-Wesley) and the concepts of bounded contexts and aggregates. Bounded contexts deal with large models by dividing them into different components, and aggregates help further to group bounded contexts into modules with defined transaction boundaries. However, in addition to these business domain considerations, for every distributed systemâwhether it is based on microservices or notâthere are also numerous technical concerns around its organization, structure, and runtime behavior.
Containers and container orchestrators such as Kubernetes provide many new primitives and abstractions to address the concerns of distributed applications, and here we discuss the various options to consider when putting a distributed system into Kubernetes.
Throughout this book, we look at container and platform interactions by treating the containers as black boxes. However, we created this section to emphasize the importance of what goes into containers. Containers and cloud-native platforms bring tremendous benefits to your distributed applications, but if all you put into containers is rubbish, you will get distributed rubbish at scale. Figure 1-1 shows the mixture of the skills required for creating good cloud-native applications.
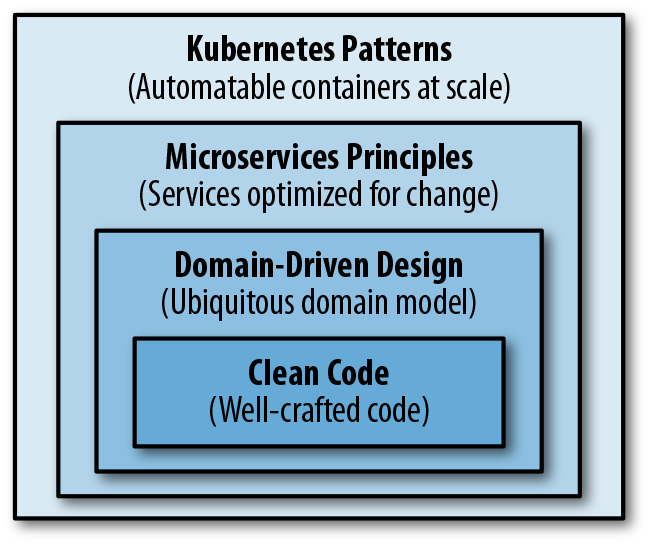
Figure 1-1. The path to cloud native
At a high level, there are multiple abstraction levels in a cloud-native application that require different design considerations:
-
At the lowest code level, every variable you define, every method you create, and every class you decide to instantiate plays a role in the long-term maintenance of the application. No matter what container technology and orchestration platform you use, the development team and the artifacts they create will have the most impact. It is important to grow developers who strive to write clean code, have the right amount of automated tests, constantly refactor to improve code quality, and are software craftsmen at heart.
-
Domain-Driven Design is about approaching software design from a business perspective with the intention of keeping the architecture as close to the real world as possible. This approach works best for object-oriented programming languages, but there are also other good ways to model and design software for real-world problems. A model with the right business and transaction boundaries, easy-to-consume interfaces, and rich APIs is the foundation for successful containerization and automation later.
-
The microservices architectural style very quickly evolved to become the norm, and it provides valuable principles and practices for designing changing distributed applications. Applying these principles lets you create implementations that are optimized for scale, resiliency, and pace of change, which are common requirements for any modern software today.
-
Containers were very quickly adopted as the standard way of packaging and running distributed applications. Creating modular, reusable containers that are good cloud-native citizens is another fundamental prerequisite. With a growing number of containers in every organization comes the need to manage them using more effective methods and tools. Cloud native is a relatively new term used to describe principles, patterns, and tools to automate containerized microservices at scale. We use cloud native interchangeably with Kubernetes, which is the most popular open source cloud-native platform available today.
In this book, we are not covering clean code, domain-driven design, or microservices. We are focusing only on the patterns and practices addressing the concerns of the container orchestration. But for these patterns to be effective, your application needs to be designed well from the inside by applying clean code practices, domain-driven design, microservices patterns, and other relevant design techniques.
Distributed Primitives
To explain what we mean by new abstractions and primitives, here we compare them with the well-known object-oriented programming (OOP), and Java specifically. In the OOP universe, we have concepts such as class, object, package, inheritance, encapsulation, and polymorphism. Then the Java runtime provides specific features and guarantees on how it manages the lifecycle of our objects and the application as a whole.
The Java language and the Java Virtual Machine (JVM) provide local, in-process building blocks for creating applications. Kubernetes adds an entirely new dimension to this well-known mindset by offering a new set of distributed primitives and runtime for building distributed systems that spread across multiple nodes and processes. With Kubernetes at hand, we donât rely only on the local primitives to implement the whole application behavior.
We still need to use the object-oriented building blocks to create the components of the distributed application, but we can also use Kubernetes primitives for some of the application behaviors. Table 1-1 shows how various development concepts are realized differently with local and distributed primitives.
| Concept | Local primitive | Distributed primitive |
|---|---|---|
Behavior encapsulation |
Class |
Container image |
Behavior instance |
Object |
Container |
Unit of reuse |
.jar |
Container image |
Composition |
Class A contains Class B |
|
Inheritance |
Class A extends Class B |
A containerâs |
Deployment unit |
.jar/.war/.ear |
Pod |
Buildtime/Runtime isolation |
Module, Package, Class |
Namespace, Pod, container |
Initialization preconditions |
Constructor |
|
Postinitialization trigger |
Init-method |
|
Predestroy trigger |
Destroy-method |
|
Cleanup procedure |
|
Defer containera |
Asynchronous & parallel execution |
|
Job |
Periodic task |
|
|
Background task |
Daemon thread |
|
Configuration management |
|
|
a Defer (or de-init) containers are not yet implemented, but there is a proposal on the way to include this feature in future versions of Kubernetes. We discuss lifecycle hooks in Chapter 5, Managed Lifecycle. | ||
The in-process primitives and the distributed primitives have commonalities, but they are not directly comparable and replaceable. They operate at different abstraction levels and have different preconditions and guarantees. Some primitives are supposed to be used together. For example, we still have to use classes to create objects and put them into container images. However, some other primitives such as CronJob in Kubernetes can replace the ExecutorService behavior in Java completely.
Next, letâs see a few distributed abstractions and primitives from Kubernetes that are especially interesting for application developers.
Containers
Containers are the building blocks for Kubernetes-based cloud-native applications. If we make a comparison with OOP and Java, container images are like classes, and containers are like objects. The same way we can extend classes to reuse and alter behavior, we can have container images that extend other container images to reuse and alter behavior. The same way we can do object composition and use functionality, we can do container compositions by putting containers into a Pod and using collaborating containers.
If we continue the comparison, Kubernetes would be like the JVM but spread over multiple hosts, and would be responsible for running and managing the containers. Init containers would be something like object constructors; DaemonSets would be similar to daemon threads that run in the background (like the Java Garbage Collector, for example). A Pod would be something similar to an Inversion of Control (IoC) context (Spring Framework, for example), where multiple running objects share a managed lifecycle and can access each other directly.
The parallel doesnât go much further, but the point is that containers play a fundamental role in Kubernetes, and creating modularized, reusable, single-purpose container images is fundamental to the long-term success of any project and even the containersâ ecosystem as a whole. Apart from the technical characteristics of a container image that provide packaging and isolation, what does a container represent and what is its purpose in the context of a distributed application? Here are a few suggestions on how to look at containers:
-
A container image is the unit of functionality that addresses a single concern.
-
A container image is owned by one team and has a release cycle.
-
A container image is self-contained and defines and carries its runtime dependencies.
-
A container image is immutable, and once it is built, it does not change; it is configured.
-
A container image has defined runtime dependencies and resource requirements.
-
A container image has well-defined APIs to expose its functionality.
-
A container runs typically as a single Unix process.
-
A container is disposable and safe to scale up or down at any moment.
In addition to all these characteristics, a proper container image is modular. It is parameterized and created for reuse in the different environments it is going to run. But it is also parameterized for its various use cases. Having small, modular, and reusable container images leads to the creation of more specialized and stable container images in the long term, similar to a great reusable library in the programming language world.
Pods
Looking at the characteristics of containers, we can see that they are a perfect match for implementing the microservices principles. A container image provides a single unit of functionality, belongs to a single team, has an independent release cycle, and provides deployment and runtime isolation. Most of the time, one microservice corresponds to one container image.
However, most cloud-native platforms offer another primitive for managing the lifecycle of a group of containersâin Kubernetes it is called a Pod. A Pod is an atomic unit of scheduling, deployment, and runtime isolation for a group of containers. All containers in a Pod are always scheduled to the same host, deployed together whether for scaling or host migration purposes, and can also share filesystem, networking, and process namespaces. This joint lifecycle allows the containers in a Pod to interact with each other over the filesystem or through networking via localhost or host interprocess communication mechanisms if desired (for performance reasons, for example).
As you can see in Figure 1-2, at the development and build time, a microservice corresponds to a container image that one team develops and releases. But at runtime, a microservice is represented by a Pod, which is the unit of deployment, placement, and scaling. The only way to run a containerâwhether for scale or migrationâis through the Pod abstraction. Sometimes a Pod contains more than one container. One such example is when a containerized microservice uses a helper container at runtime, as Chapter 15, Sidecar demonstrates later.
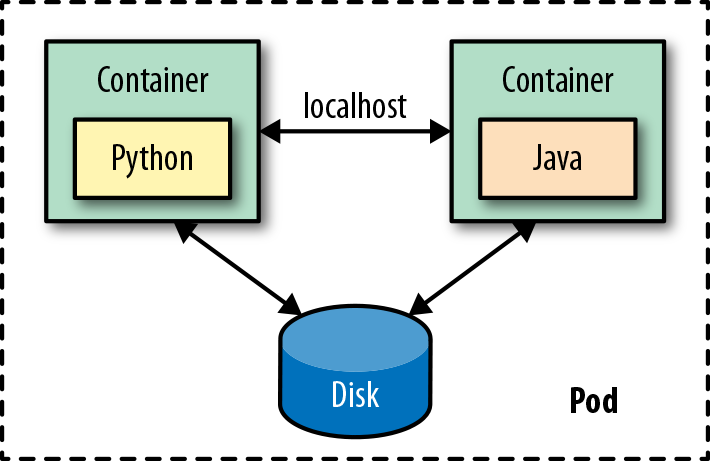
Figure 1-2. A Pod as the deployment and management unit
Containers and Pods and their unique characteristics offer a new set of patterns and principles for designing microservices-based applications. We looked at some of the characteristics of well-designed containers; now letâs look at some of the characteristics of a Pod:
-
A Pod is the atomic unit of scheduling. That means the scheduler tries to find a host that satisfies the requirements of all containers that belong to the Pod (there are some specifics around init containers, which we cover in Chapter 14, Init Container). If you create a Pod with many containers, the scheduler needs to find a host that has enough resources to satisfy all container demands combined. This scheduling process is described in Chapter 6, Automated Placement.
-
A Pod ensures colocation of containers. Thanks to the colocation, containers in the same Pod have additional means to interact with each other. The most common ways for communication include using a shared local filesystem for exchanging data or using the localhost network interface, or some host inter-process communication (IPC) mechanism for high-performance interactions.
-
A Pod has an IP address, name, and port range that are shared by all containers belonging to it. That means containers in the same Pod have to be carefully configured to avoid port clashes, in the same way that parallel running Unix processes have to take care when sharing the networking space on a host.
A Pod is the atom of Kubernetes where your application lives, but you donât access Pods directlyâthat is where Services enter the scene.
Services
Pods are ephemeralâthey can come and go at any time for all sort of reasons such as scaling up and down, failing container health checks, and node migrations. A Pod IP address is known only after it is scheduled and started on a node. A Pod can be rescheduled to a different node if the existing node it is running on is no longer healthy. All that means is the Podâs network address may change over the life of an application, and there is a need for another primitive for discovery and load balancing.
Thatâs where the Kubernetes Services come into play. The Service is another simple but powerful Kubernetes abstraction that binds the Service name to an IP address and port number permanently. So a Service represents a named entry point for accessing an application. In the most common scenario, the Service serves as the entry point for a set of Pods, but that might not always be the case. The Service is a generic primitive, and it may also point to functionality provided outside the Kubernetes cluster. As such, the Service primitive can be used for Service discovery and load balancing, and allows altering implementations and scaling without affecting Service consumers. We explain Services in detail in Chapter 12, Service Discovery.
Labels
We have seen that a microservice is a container at build time but represented by a Pod at runtime. So what is an application that consists of multiple microservices? Here, Kubernetes offers two more primitives that can help you define the concept of an application: labels and namespaces. We cover namespaces in detail in âNamespacesâ.
Before microservices, an application corresponded to a single deployment unit with a single versioning scheme and release cycle. There was a single file for an application in the form of a .war, or .ear or some other packaging format. But then, applications got split into microservices, which are independently developed, released, run, restarted, or scaled. With microservices, the notion of an application diminishes, and there are no longer key artifacts or activities that we have to perform at the application level. However, if you still need a way to indicate that some independent services belong to an application, labels can be used. Letâs imagine that we have split one monolithic application into three microservices, and another application into two microservices.
We now have five Pod definitions (and maybe many more Pod instances) that are independent of the development and runtime points of view. However, we may still need to indicate that the first three Pods represent an application and the other two Pods represent another application. Even the Pods may be independent, to provide a business value, but they may depend on each other. For example, one Pod may contain the containers responsible for the frontend, and the other two Pods are responsible for providing the backend functionality. If either of these Pods is down, the application is useless from a business point of view. Using label selectors gives us the ability to query and identify a set of Pods and manage it as one logical unit. Figure 1-3 shows how you can use labels to group the parts of a distributed application into specific subsystems.
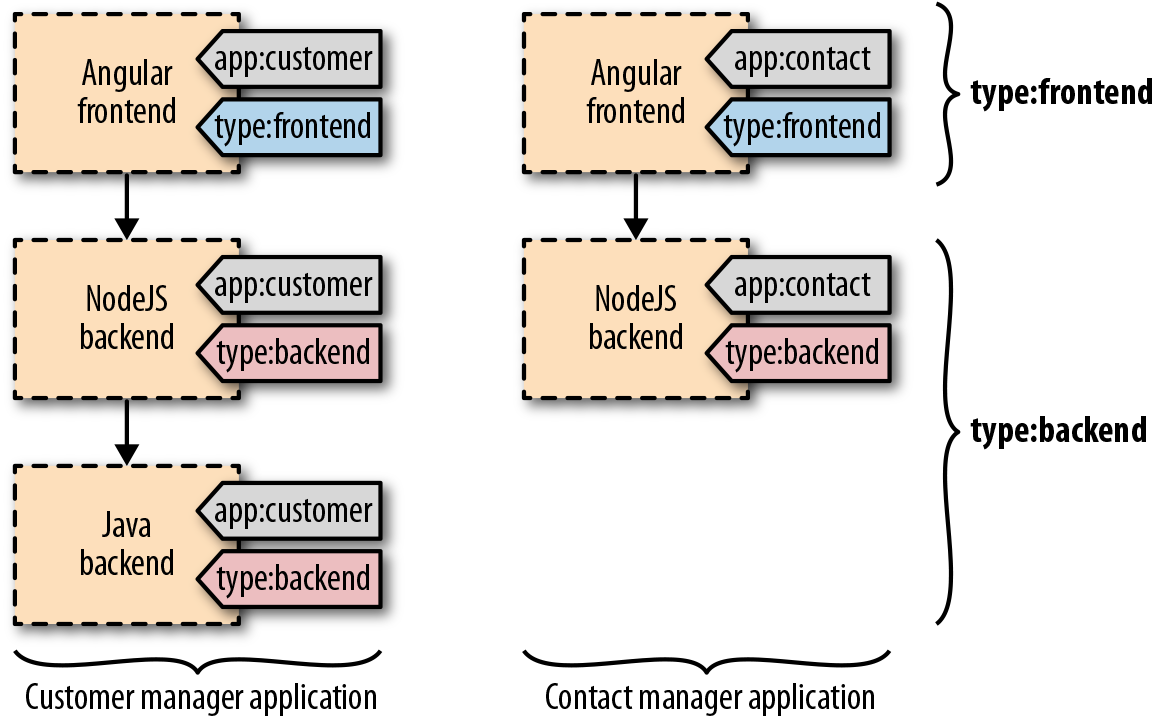
Figure 1-3. Labels used as an application identity for Pods
Here are a few examples where labels can be useful:
-
Labels are used by the ReplicaSets to keep some instances of a specific Pod running. That means every Pod definition needs to have a unique combination of labels used for scheduling.
-
Labels are also used heavily by the scheduler. The scheduler uses labels for co-locating or spreading Pods to place Pods on the nodes that satisfy the Podsâ requirements.
-
A Label can indicate a logical grouping of set of Pods and give an application identity to them.
-
In addition to the preceding typical use cases, labels can be used to store metadata. It may be difficult to predict what a label could be used for, but it is best to have enough labels to describe all important aspects of the Pods. For example, having labels to indicate the logical group of an application, the business characteristics and criticality, the specific runtime platform dependencies such as hardware architecture, or location preferences are all useful.
Later, these labels can be used by the scheduler for more fine-grained scheduling, or the same labels can be used from the command line for managing the matching Pods at scale. However, you should not go overboard and add too many labels in advance. You can always add them later if needed. Removing labels is much riskier as there is no straight-forward way of finding out what a label is used for, and what unintended effect such an action may cause.
Annotations
Another primitive very similar to labels is called annotations. Like labels, annotations are organized as a map, but they are intended for specifying nonsearchable metadata and for machine usage rather than human.
The information on the annotations is not intended for querying and matching objects. Instead, it is intended for attaching additional metadata to objects from various tools and libraries we want to use. Some examples of using annotations include build IDs, release IDs, image information, timestamps, Git branch names, pull request numbers, image hashes, registry addresses, author names, tooling information, and more. So while labels are used primarily for query matching and performing actions on the matching resources, annotations are used to attach metadata that can be consumed by a machine.
Namespaces
Another primitive that can also help in the management of a group of resources is the Kubernetes namespace. As we have described, a namespace may seem similar to a label, but in reality, it is a very different primitive with different characteristics and purpose.
Kubernetes namespaces allow dividing a Kubernetes cluster (which is usually spread across multiple hosts) into a logical pool of resources. Namespaces provide scopes for Kubernetes resources and a mechanism to apply authorizations and other policies to a subsection of the cluster. The most common use case of namespaces is representing different software environments such as development, testing, integration testing, or production. Namespaces can also be used to achieve multitenancy, and provide isolation for team workspaces, projects, and even specific applications. But ultimately, for a greater isolation of certain environments, namespaces are not enough, and having separate clusters is common. Typically, there is one nonproduction Kubernetes cluster used for some environments (development, testing, and integration testing) and another production Kubernetes cluster to represent performance testing and production environments.
Letâs see some of the characteristics of namespaces and how they can help us in different scenarios:
-
A namespace is managed as a Kubernetes resource.
-
A namespace provides scope for resources such as containers, Pods, Services, or ReplicaSets. The names of resources need to be unique within a namespace, but not across them.
-
By default, namespaces provide scope for resources, but nothing isolates those resources and prevents access from one resource to another. For example, a Pod from a development namespace can access another Pod from a production namespace as long as the Pod IP address is known. However, there are Kubernetes plugins that provide networking isolation to achieve true multitenancy across namespaces if desired.
-
Some other resources such as namespaces themselves, nodes, and PersistentVolumes do not belong to namespaces and should have unique cluster-wide names.
-
Each Kubernetes Service belongs to a namespace and gets a corresponding DNS address that has the namespace in the form of
<service-name>.<namespace-name>.svc.cluster.local. So the namespace name is in the URI of every Service belonging to the given namespace. Thatâs one reason it is vital to name namespaces wisely. -
ResourceQuotas provide constraints that limit the aggregated resource consumption per namespace. With ResourceQuotas, a cluster administrator can control the number of objects per type that are allowed in a namespace. For example, a developer namespace may allow only five ConfigMaps, five Secrets, five Services, five ReplicaSets, five PersistentVolumeClaims, and ten Pods.
-
ResourceQuotas can also limit the total sum of computing resources we can request in a given namespace. For example, in a cluster with a capacity of 32 GB RAM and 16 cores, it is possible to allocate half of the resourcesâ16 GB RAM and 8 coresâfor the production namespace, 8 GB RAM and 4 cores for staging environment, 4 GB RAM and 2 cores for development, and the same amount for testing namespaces. The ability of imposing resource constraints on a group of objects by using namespaces and ResourceQuotas is invaluable.
Discussion
Weâve only briefly covered a few of the main Kubernetes concepts we use in this book. However, there are more primitives used by developers on a day-by-day basis. For example, if you create a containerized service, there are collections of Kubernetes objects you can use to reap all the benefits of Kubernetes. Keep in mind, these are only the objects used by application developers to integrate a containerized service into Kubernetes. There are also other concepts used by administrators to enable developers to manage the platform effectively. Figure 1-4 gives an overview of the multitude of Kubernetes resources that are useful for developers.
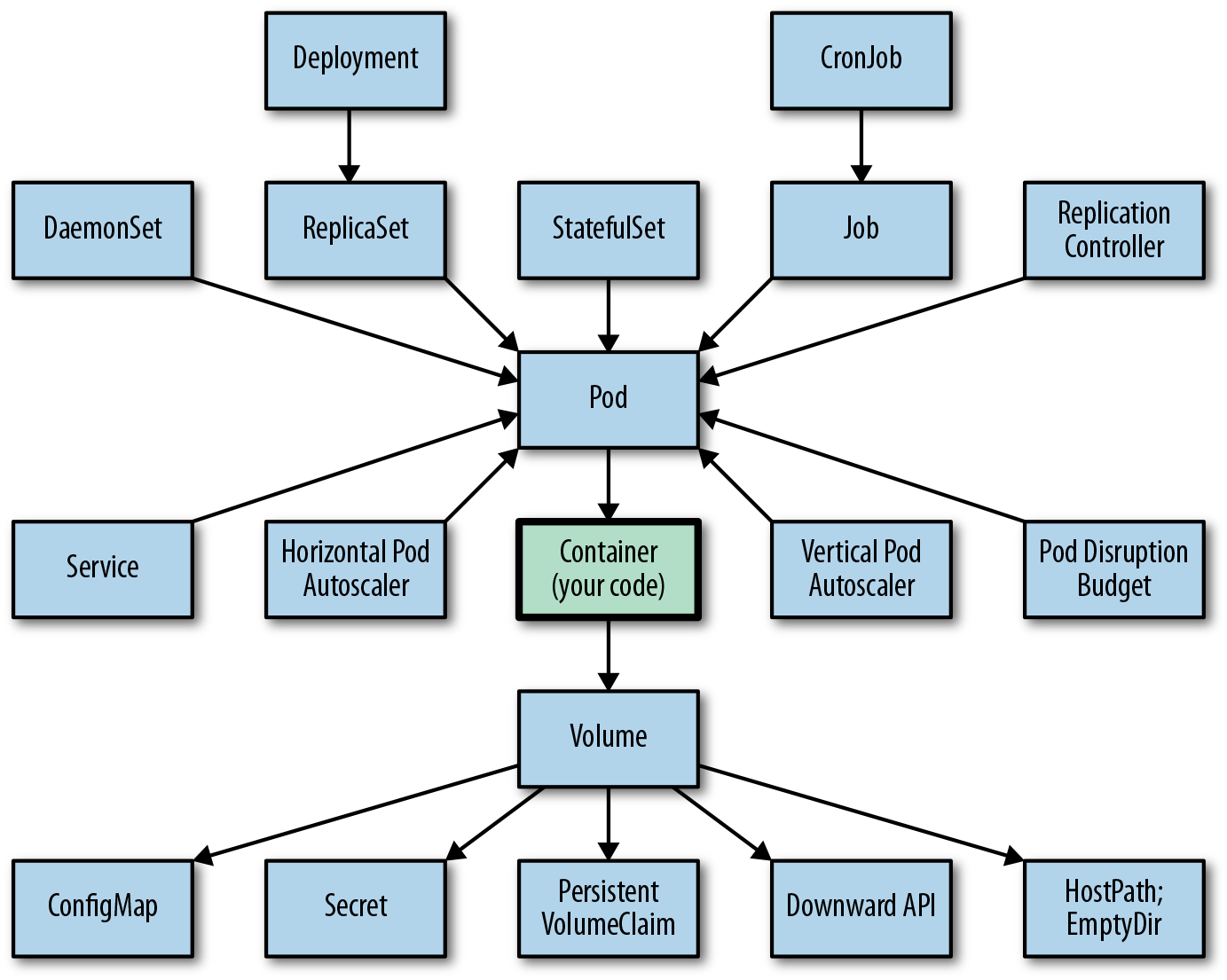
Figure 1-4. Kubernetes concepts for developers
With time, these new primitives give birth to new ways of solving problems, and some of these repetitive solutions become patterns. Throughout this book, rather than describing a Kubernetes resource in detail, we will focus on Kubernetes aspects that are proven as patterns.
Get Kubernetes Patterns now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

