February 2017
Intermediate to advanced
274 pages
5h 58m
English
As noted in the previous section, so far, our script has performed a point in time streaming word count. The following diagram denotes the lines DStream and its micro-batches as per how our script had executed in the previous section:
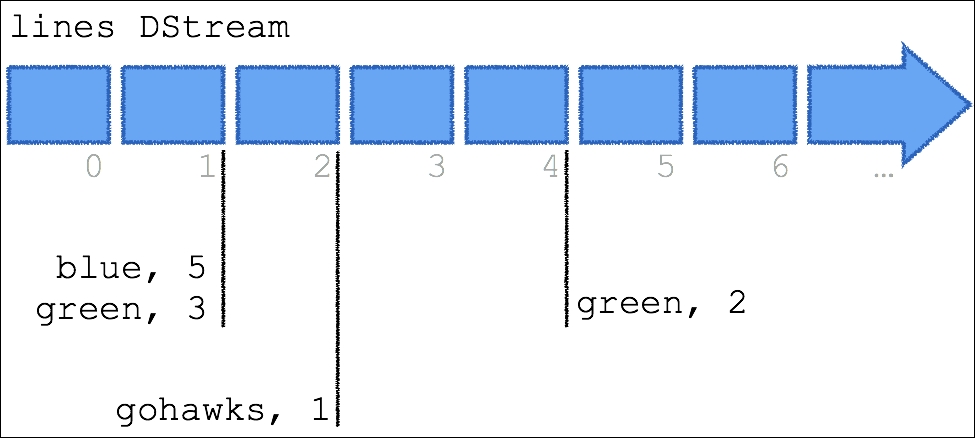
At the 1 second mark, our Python Spark Streaming script returned the value of {(blue, 5), (green, 3)}, at the 2 second mark it returned {(gohawks, 1)}, and at the 4 second mark, it returned {(green, 2)}. But what if you had wanted the aggregate word count over a specific time window?
The following figure represents us calculating a stateful aggregation:
In this case, we have a time ...
Read now
Unlock full access






