Analysing HTML code and extracting data
In the previous sections, we learned the basics of HTML, CSS, and XPath. To scrape real-world web pages, the problem now becomesa question of writing the proper CSS or XPath selectors. In this section, we introduce some simple ways to figure out working selectors.
Suppose we want to scrape all available R packages at https://cran.rstudio.com/web/packages/available_packages_by_name.html. The web page looks simple. To figure out the selector expression, right-click on the table and select Inspect Element in the context menu, which should be available in most modern web browsers:
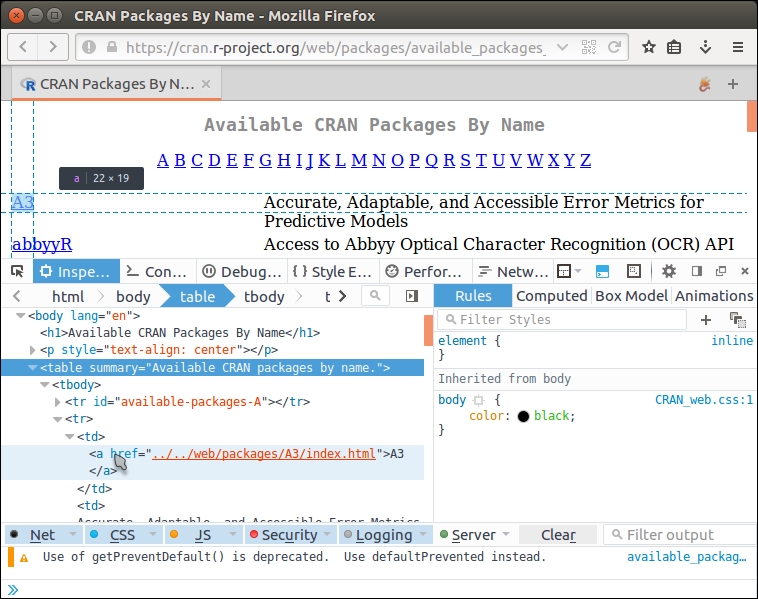
Then the inspector panel shows ...
Get Learning R Programming now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

