Chapter 1. Introduction
This chapter provides a high-level overview of TensorFlow and its primary use: implementing and deploying deep learning systems. We begin with a very brief introductory look at deep learning. We then present TensorFlow, showcasing some of its exciting uses for building machine intelligence, and then lay out its key features and properties.
Going Deep
From large corporations to budding startups, engineers and data scientists are collecting huge amounts of data and using machine learning algorithms to answer complex questions and build intelligent systems. Wherever one looks in this landscape, the class of algorithms associated with deep learning have recently seen great success, often leaving traditional methods in the dust. Deep learning is used today to understand the content of images, natural language, and speech, in systems ranging from mobile apps to autonomous vehicles. Developments in this field are taking place at breakneck speed, with deep learning being extended to other domains and types of data, like complex chemical and genetic structures for drug discovery and high-dimensional medical records in public healthcare.
Deep learning methods—which also go by the name of deep neural networks—were originally roughly inspired by the human brain’s vast network of interconnected neurons. In deep learning, we feed millions of data instances into a network of neurons, teaching them to recognize patterns from raw inputs. The deep neural networks take raw inputs (such as pixel values in an image) and transform them into useful representations, extracting higher-level features (such as shapes and edges in images) that capture complex concepts by combining smaller and smaller pieces of information to solve challenging tasks such as image classification (Figure 1-1). The networks automatically learn to build abstract representations by adapting and correcting themselves, fitting patterns observed in the data. The ability to automatically construct data representations is a key advantage of deep neural nets over conventional machine learning, which typically requires domain expertise and manual feature engineering before any “learning” can occur.
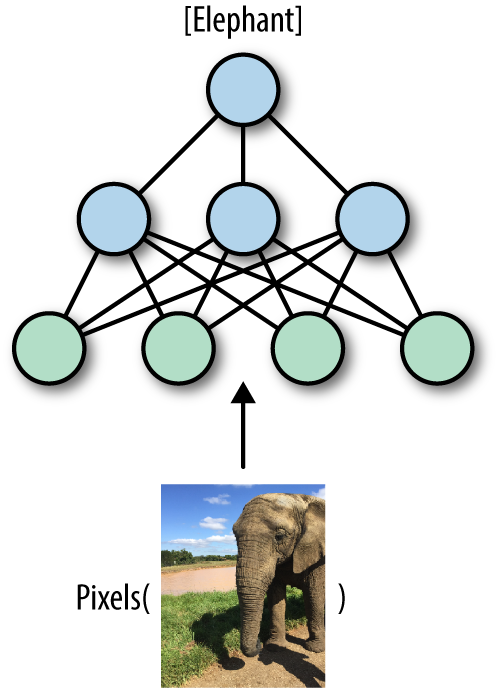
Figure 1-1. An illustration of image classification with deep neural networks. The network takes raw inputs (pixel values in an image) and learns to transform them into useful representations, in order to obtain an accurate image classification.
This book is about Google’s framework for deep learning, TensorFlow. Deep learning algorithms have been used for several years across many products and areas at Google, such as search, translation, advertising, computer vision, and speech recognition. TensorFlow is, in fact, a second-generation system for implementing and deploying deep neural networks at Google, succeeding the DistBelief project that started in 2011.
TensorFlow was released to the public as an open source framework with an Apache 2.0 license in November 2015 and has already taken the industry by storm, with adoption going far beyond internal Google projects. Its scalability and flexibility, combined with the formidable force of Google engineers who continue to maintain and develop it, have made TensorFlow the leading system for doing deep learning.
Using TensorFlow for AI Systems
Before going into more depth about what TensorFlow is and its key features, we will briefly give some exciting examples of how TensorFlow is used in some cutting-edge real-world applications, at Google and beyond.
Pre-trained models: state-of-the-art computer vision for all
One primary area where deep learning is truly shining is computer vision. A fundamental task in computer vision is image classification—building algorithms and systems that receive images as input, and return a set of categories that best describe them. Researchers, data scientists, and engineers have designed advanced deep neural networks that obtain highly accurate results in understanding visual content. These deep networks are typically trained on large amounts of image data, taking much time, resources, and effort. However, in a growing trend, researchers are publicly releasing pre-trained models—deep neural nets that are already trained and that users can download and apply to their data (Figure 1-2).
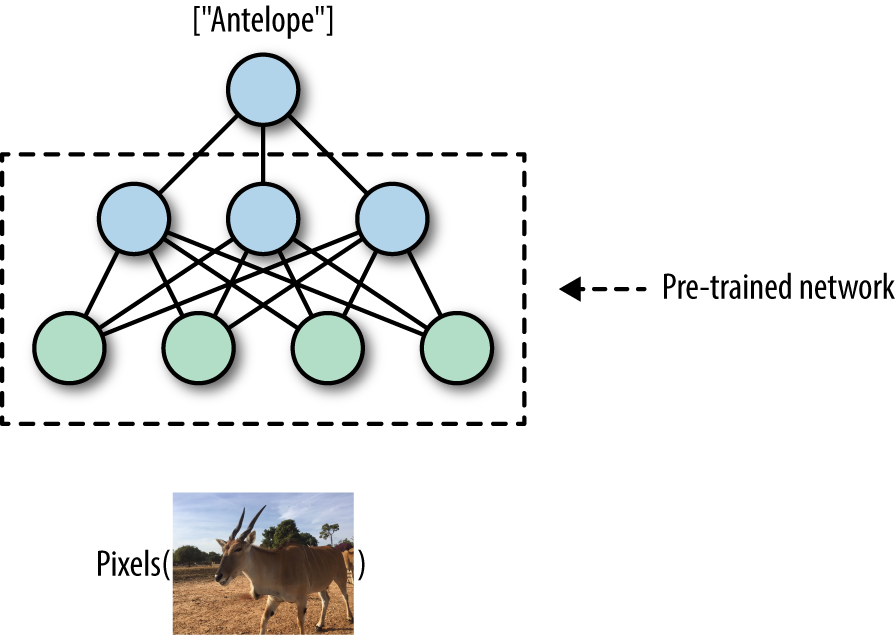
Figure 1-2. Advanced computer vision with pre-trained TensorFlow models.
TensorFlow comes with useful utilities allowing users to obtain and apply cutting-edge pretrained models. We will see several practical examples and dive into the details throughout this book.
Generating rich natural language descriptions for images
One exciting area of deep learning research for building machine intelligence systems is focused on generating natural language descriptions for visual content (Figure 1-3). A key task in this area is image captioning—teaching the model to output succinct and accurate captions for images. Here too, advanced pre-trained TensorFlow models that combine natural language understanding with computer vision are available.

Figure 1-3. Going from images to text with image captioning (illustrative example).
Text summarization
Natural language understanding (NLU) is a key capability for building AI systems. Tremendous amounts of text are generated every day: web content, social media, news, emails, internal corporate correspondences, and many more. One of the most sought-after abilities is to summarize text, taking long documents and generating succinct and coherent sentences that extract the key information from the original texts (Figure 1-4). As we will see later in this book, TensorFlow comes with powerful features for training deep NLU networks, which can also be used for automatic text summarization.

Figure 1-4. An illustration of smart text summarization.
TensorFlow: What’s in a Name?
Deep neural networks, as the term and the illustrations we’ve shown imply, are all about networks of neurons, with each neuron learning to do its own operation as part of a larger picture. Data such as images enters this network as input, and flows through the network as it adapts itself at training time or predicts outputs in a deployed system.
Tensors are the standard way of representing data in deep learning. Simply put, tensors are just multidimensional arrays, an extension of two-dimensional tables (matrices) to data with higher dimensionality. Just as a black-and-white (grayscale) images are represented as “tables” of pixel values, RGB images are represented as tensors (three-dimensional arrays), with each pixel having three values corresponding to red, green, and blue components.
In TensorFlow, computation is approached as a dataflow graph (Figure 1-5). Broadly speaking, in this graph, nodes represent operations (such as addition or multiplication), and edges represent data (tensors) flowing around the system. In the next chapters, we will dive deeper into these concepts and learn to understand them with many examples.
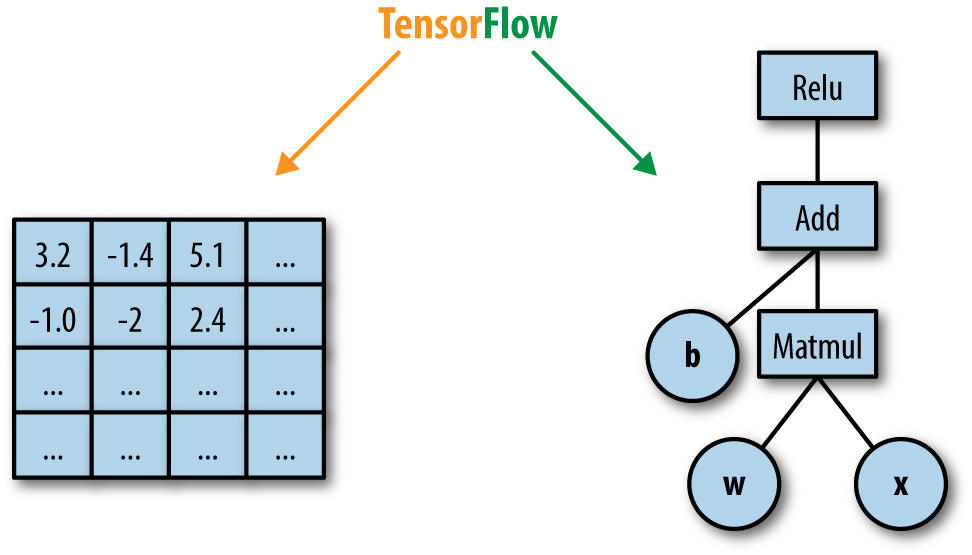
Figure 1-5. A dataflow computation graph. Data in the form of tensors flows through a graph of computational operations that make up our deep neural networks.
A High-Level Overview
TensorFlow, in the most general terms, is a software framework for numerical computations based on dataflow graphs. It is designed primarily, however, as an interface for expressing and implementing machine learning algorithms, chief among them deep neural networks.
TensorFlow was designed with portability in mind, enabling these computation graphs to be executed across a wide variety of environments and hardware platforms. With essentially identical code, the same TensorFlow neural net could, for instance, be trained in the cloud, distributed over a cluster of many machines or on a single laptop. It can be deployed for serving predictions on a dedicated server or on mobile device platforms such as Android or iOS, or Raspberry Pi single-board computers. TensorFlow is also compatible, of course, with Linux, macOS, and Windows operating systems.
The core of TensorFlow is in C++, and it has two primary high-level frontend languages and interfaces for expressing and executing the computation graphs. The most developed frontend is in Python, used by most researchers and data scientists. The C++ frontend provides quite a low-level API, useful for efficient execution in embedded systems and other scenarios.
Aside from its portability, another key aspect of TensorFlow is its flexibility, allowing researchers and data scientists to express models with relative ease. It is sometimes revealing to think of modern deep learning research and practice as playing with “LEGO-like” bricks, replacing blocks of the network with others and seeing what happens, and at times designing new blocks. As we shall see throughout this book, TensorFlow provides helpful tools to use these modular blocks, combined with a flexible API that enables the writing of new ones. In deep learning, networks are trained with a feedback process called backpropagation based on gradient descent optimization. TensorFlow flexibly supports many optimization algorithms, all with automatic differentiation—the user does not need to specify any gradients in advance, since TensorFlow derives them automatically based on the computation graph and loss function provided by the user. To monitor, debug, and visualize the training process, and to streamline experiments, TensorFlow comes with TensorBoard (Figure 1-6), a simple visualization tool that runs in the browser, which we will use throughout this book.
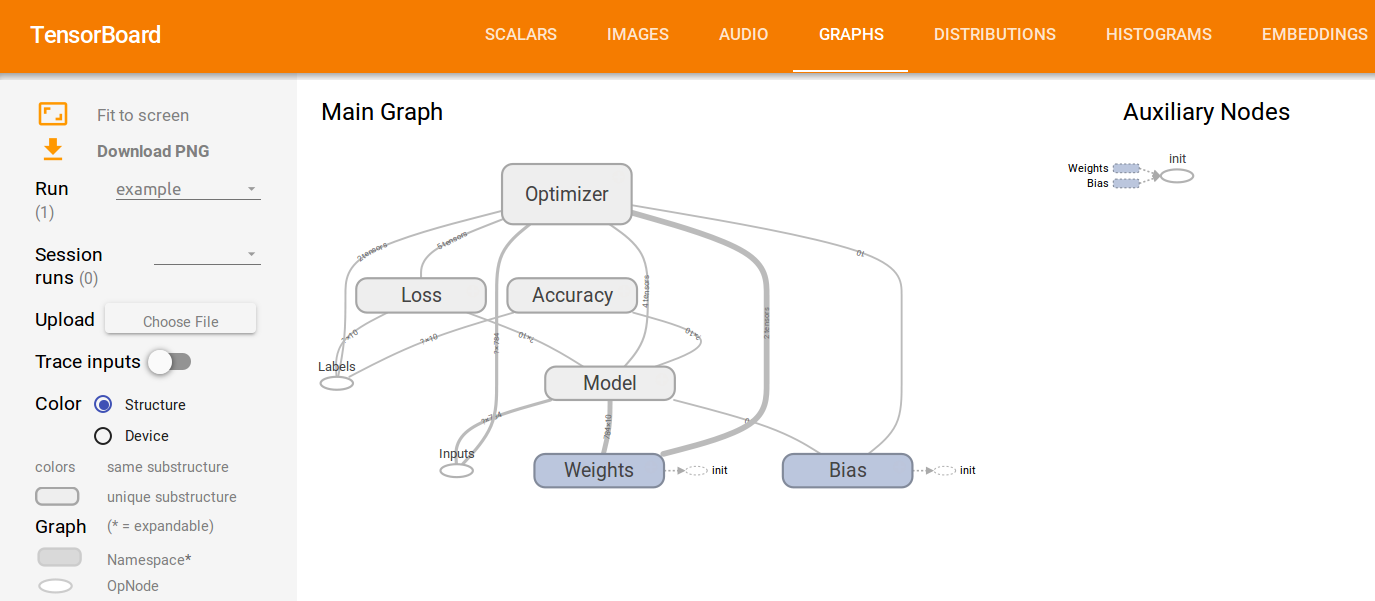
Figure 1-6. TensorFlow’s visualization tool, TensorBoard, for monitoring, debugging, and analyzing the training process and experiments.
Key enablers of TensorFlow’s flexibility for data scientists and researchers are high-level abstraction libraries. In state-of-the-art deep neural nets for computer vision or NLU, writing TensorFlow code can take a toll—it can become a complex, lengthy, and cumbersome endeavor. Abstraction libraries such as Keras and TF-Slim offer simplified high-level access to the “LEGO bricks” in the lower-level library, helping to streamline the construction of the dataflow graphs, training them, and running inference. Another key enabler for data scientists and engineers is the pretrained models that come with TF-Slim and TensorFlow. These models were trained on massive amounts of data with great computational resources, which are often hard to come by and in any case require much effort to acquire and set up. Using Keras or TF-Slim, for example, with just a few lines of code it is possible to use these advanced models for inference on incoming data, and also to fine-tune the models to adapt to new data.
The flexibility and portability of TensorFlow help make the flow from research to production smooth, cutting the time and effort it takes for data scientists to push their models to deployment in products and for engineers to translate algorithmic ideas into robust code.
TensorFlow abstractions
TensorFlow comes with abstraction libraries such as Keras and TF-Slim, offering simplified high-level access to TensorFlow. These abstractions, which we will see later in this book, help streamline the construction of the dataflow graphs and enable us to train them and run inference with many fewer lines of code.
But beyond flexibility and portability, TensorFlow has a suite of properties and tools that make it attractive for engineers who build real-world AI systems. It has natural support for distributed training—indeed, it is used at Google and other large industry players to train massive networks on huge amounts of data, over clusters of many machines. In local implementations, training on multiple hardware devices requires few changes to code used for single devices. Code also remains relatively unchanged when going from local to distributed, which makes using TensorFlow in the cloud, on Amazon Web Services (AWS) or Google Cloud, particularly attractive. Additionally, as we will see further along in this book, TensorFlow comes with many more features aimed at boosting scalability. These include support for asynchronous computation with threading and queues, efficient I/O and data formats, and much more.
Deep learning continues to rapidly evolve, and so does TensorFlow, with frequent new and exciting additions, bringing better usability, performance, and value.
Summary
With the set of tools and features described in this chapter, it becomes clear why TensorFlow has attracted so much attention in little more than a year. This book aims at first rapidly getting you acquainted with the basics and ready to work, and then we will dive deeper into the world of TensorFlow with exciting and practical examples.
Get Learning TensorFlow now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

